

600 kW Per Rack: The AI Power Crisis Reshaping Electrical Infrastructure
In 24 months, AI server racks go from 120 kW to 600 kW. The electrical supply chain — transformers, power semiconductors, cooling systems, substations — wasn't built for this.

TL;DR — Five things to know
AI racks go from 120 kW today to 600 kW by 2027. Power infrastructure value per rack jumps from $36K to $398K+ — more than 10× baseline. This is not incremental.
The architecture shifts completely — AC→50V DC becomes AC→800V DC (HVDC). Silicon Carbide and GaN are the enabling materials. NVIDIA has already picked its semiconductor partners.
Air cooling is effectively dead above 40 kW. The liquid cooling market grows from $5.5B to $25.8B by 2035. Every new hyperscale campus is being designed liquid-native from the ground up.
Power transformers now carry 4-year lead times. More than 50% of U.S. data centers planned for 2026 face delays. This is a structural bottleneck, not a supply chain hiccup.
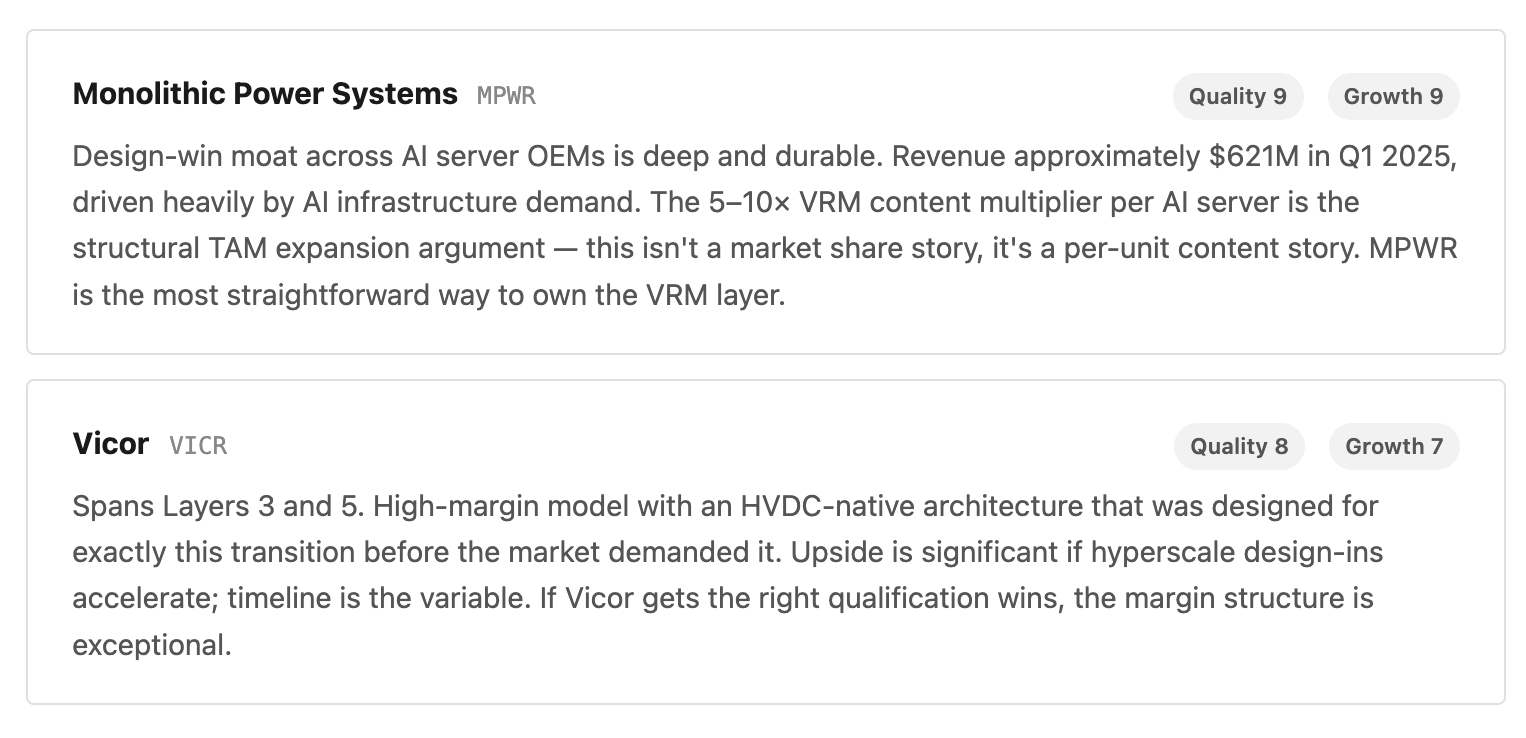
The investment thesis spans five layers: grid infrastructure → facility power → rack PSU → power semiconductors → chip-level VRM. Each has different risk, margin, and timing.
Five Generations. Five Times the Power. Twenty-Four Months.
A GB200 Blackwell rack today draws 120 kilowatts. That’s already forcing hyperscale operators to redesign power distribution floors and pull in supplemental cooling hardware mid-build. GB300 takes that to 140 kW. Vera Rubin, shipping in 2026, clears 200 kW. Vera Rubin CPX hits 380 kW. And Vera Rubin Ultra — paired with NVIDIA’s new Kyber rack architecture — lands at 600 kW per rack.
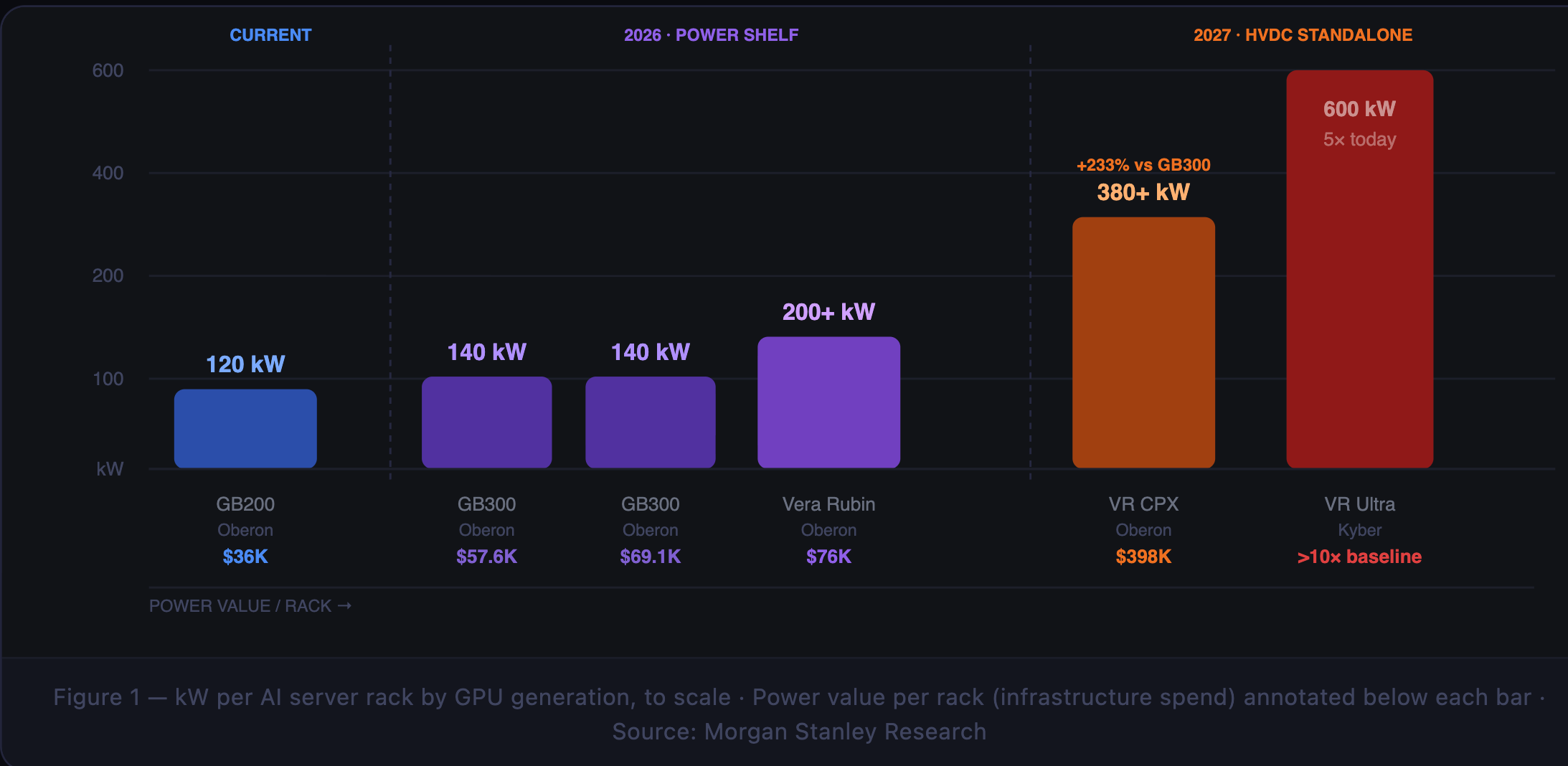
Six hundred kilowatts. In a single rack. Roughly the power draw of 600 American homes, packed into a steel enclosure seven feet tall and two feet wide. A 1,000-rack AI cluster at Vera Rubin Ultra density requires 600 megawatts of utility-grade power — the average electrical load of San Francisco.
The economic consequence, per Morgan Stanley Research, is equally direct. Power infrastructure value per AI server rack jumps from $36,000 with GB200 to $398,160 with Vera Rubin CPX — a 1,005% increase — and exceeds 10× baseline with Vera Rubin Ultra. The power electronics industry isn’t a side story in the AI buildout. It’s one of the central economic narratives.
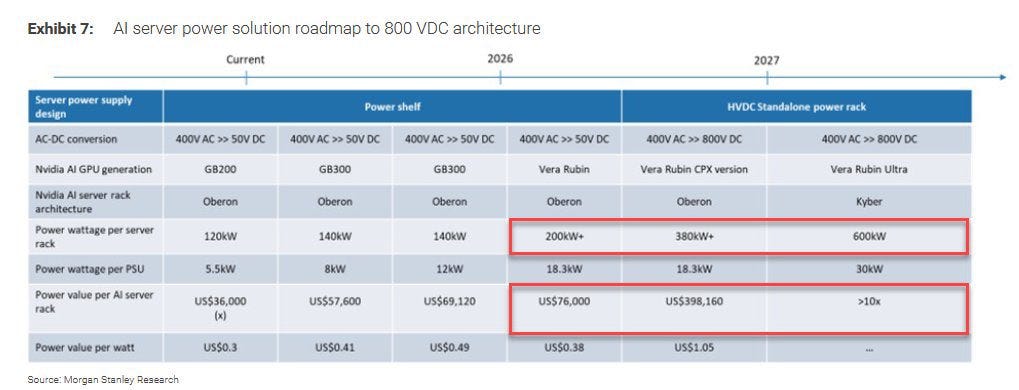
Source: Morgan Stanley Research, Exhibit 7
The Architecture Has to Change. Completely.
Today’s data centers run on a power architecture that was never designed for what’s being asked of it. AC from the grid converts to low-voltage DC inside each server’s PSU. Fine at 10 kW per rack — a number that grew only incrementally for decades. Now it’s growing exponentially, and at 600 kW the physics turn against you hard.
Source: AEIS
The problem is Ohm’s law. Power loss in a conductor equals current squared times resistance (P = I²R). Low-voltage DC forces you to move the same wattage at much higher current, and losses scale with the square of that current. The copper in your busways heats up. The conversion stages multiply. A system losing 8–10% of its power at 120 kW is wasting 48–60 kW per rack at 600 kW — waste heat equivalent to the HVAC load of a small office building, generated inside a 7-foot cabinet.
NVIDIA’s answer, baked into Vera Rubin CPX and Ultra, is a complete switch to High-Voltage Direct Current at 800V. A centralized Silicon Carbide rectifier converts utility AC directly to 800V DC. High-voltage distribution across the rack cuts resistive losses sharply. Fewer conversion stages. Less heat. More compute per watt delivered.

This is a platform transition, not an upgrade cycle — comparable in kind to spinning disk to NAND, or mechanical relays to solid-state switching. Every piece of rack-level power infrastructure gets redesigned. Every PSU, busbar, connector, and voltage regulator module needs re-qualification for 800V operation. That qualification cycle runs 12–24 months per generation. Vendors who clear it first hold a durable position in that GPU lifecycle. Vendors who don’t are excluded from the design entirely.
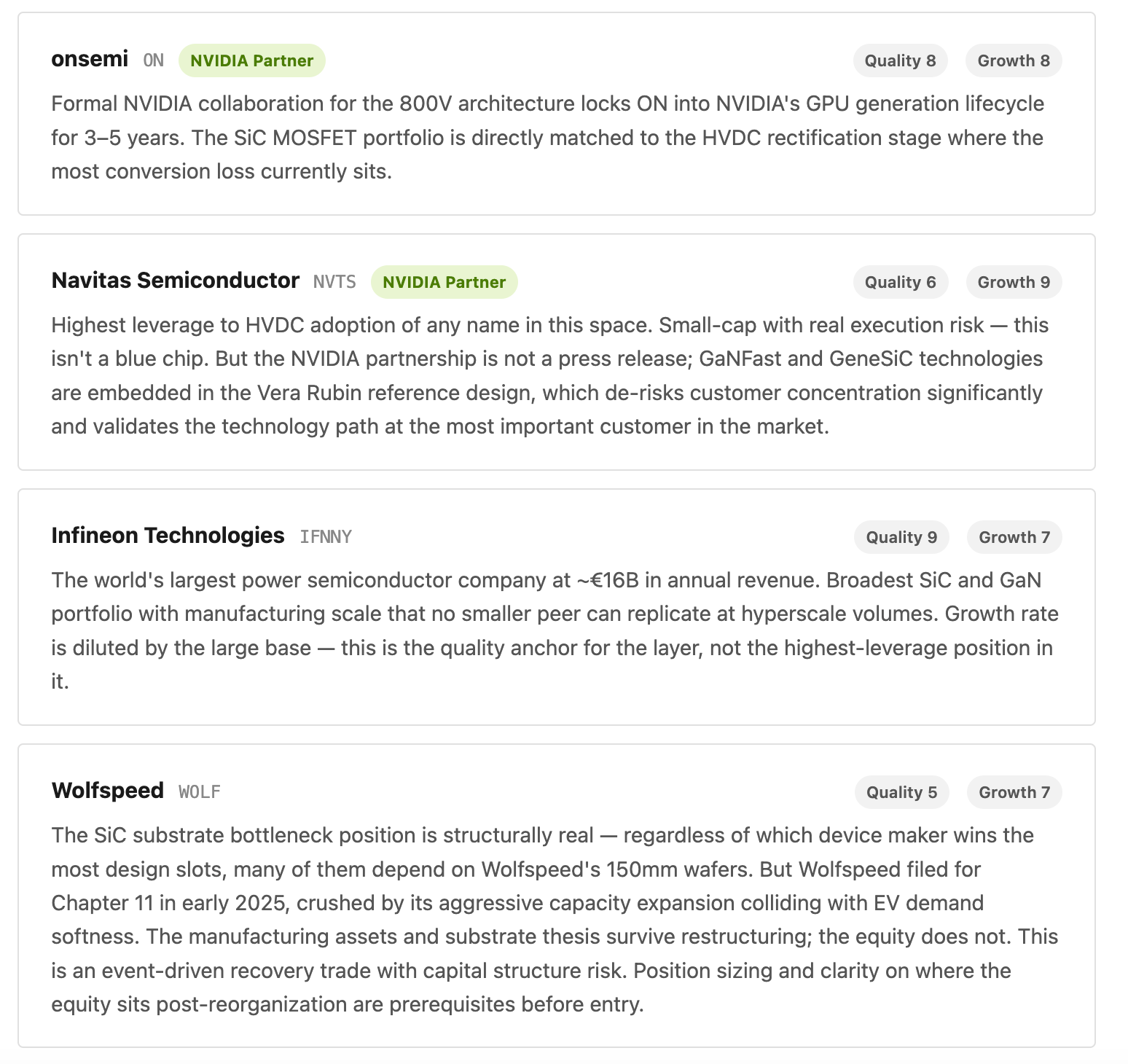
Vertiv has a full 800V HVDC product line slated for 2026. ON Semiconductor and Navitas Semiconductor have both disclosed formal NVIDIA collaboration agreements for the 800V transition — the kind of design-in that locks a vendor into a GPU generation’s revenue cycle for 3–5 years.
Silicon Carbide and GaN: The Materials That Make It Possible
Silicon has a hard ceiling around 650V. It cannot efficiently switch at the voltages and speeds 800V HVDC demands. The answer is wide bandgap semiconductors — materials with a larger energy gap between valence and conduction bands, which translates directly to higher breakdown voltage, higher switching frequency, and lower on-resistance.

Two materials carry the load. Silicon Carbide handles the high-voltage, high-current front end of HVDC conversion. A 1200V SiC MOSFET replacing a legacy silicon device delivers a 25–40% reduction in conversion losses at the rectification stage. Gallium Nitride runs the other side — operating at extremely high switching frequencies in the DC-DC stages that deliver final voltage to the GPU die, enabling smaller magnetics and better transient response in a fraction of the footprint.
Market Context
The SiC power device market landed at ~$4.6 billion in 2025 [source], growing at 19–27% CAGR through 2030. Electric vehicles drove that demand for five years. Data centers are now becoming a second vector — and a structurally more durable one. Hyperscale capex commitments run 10+ years and don’t reprice with interest rate cycles the way consumer EV purchases do.
NVIDIA’s vendor selections are the clearest market signal available. Navitas Semiconductor’s GaNFast and GeneSiC technologies are in the reference design for Vera Rubin generation power systems. ON Semiconductor’s SiC MOSFET collaboration targets the 800V rectification stage specifically. Infineon — the world’s largest power semiconductor company at roughly €16 billion in annual revenue — has 1200V SiC devices in active qualification for AI data center applications, with manufacturing scale no smaller peer can replicate at hyperscale volumes.
The substrate bottleneck. Most SiC device manufacturers — ON Semi, STMicro, Infineon — depend on SiC wafer supply from a tight group of substrate producers. Wolfspeed was the dominant U.S. source. That thesis now requires careful handling: Wolfspeed filed for Chapter 11 in early 2025, crushed by its aggressive capacity expansion program colliding with softening EV demand. The substrate leverage position is still structurally real — the wafers are still needed, the manufacturing assets didn’t vanish — but the equity is a restructuring story, not a clean infrastructure compounder. Meanwhile, Chinese manufacturers (SICC, TankeBlue, Sanan IC) are expanding capacity aggressively, applying downward pressure on substrate pricing that will ultimately benefit device makers and end customers while compressing whoever inherits Wolfspeed’s supply position post-reorganization.
Air Cooling Is Already Dead. The Industry Just Hasn’t Filed the Death Certificate.
Conventional air cooling has a practical density ceiling around 30–40 kW per rack. Above that, the volume of air you’d need to move exceeds what you can force through a rack enclosure at reasonable static pressure. Fans consume more power. Hot spots form. The economics invert — you spend more electricity removing heat than you would have spent throttling the compute.
At 120 kW, operators are already deploying rear-door heat exchangers and direct-to-chip liquid loops as a patch. Vera Rubin at 200 kW makes direct-to-chip mandatory. CPX at 380 kW pushes into immersion cooling territory. Vera Rubin Ultra at 600 kW strongly favors two-phase immersion — liquid refrigerant that boils on contact with hot components, with vapor recondensed and recirculated — though high-flow single-phase direct liquid cooling remains physically viable depending on the specific thermal design. This is industrial cooling technology borrowed from semiconductor fabs and chemical plants, now being deployed at internet infrastructure scale.
The capital intensity here is severe, and not in a “spend more to upgrade” sense — in a “start over” sense. A facility built for 40 kW air-cooled racks cannot be incrementally retrofitted to handle 200+ kW liquid-cooled systems. Floor loading, piping, leak detection, CDU placement, and electrical distribution all have to be redesigned from scratch. Greenfield hyperscale campuses announced today are going in liquid-native. Legacy colo providers face a binary: spend heavily to rebuild, or cede the AI workload tier entirely to the hyperscalers who built for this from day one.
The market trajectory reflects this. Liquid cooling at roughly $5.5 billion in 2025 is projected to reach $25.8 billion by 2035 — approximately 18–20% CAGR, driven almost entirely by AI infrastructure density requirements. Cloud providers dominate the current installed base, but enterprise AI deployments will extend that demand well beyond the hyperscale tier.
Transformers: The Four-Year Bottleneck Nobody Talks About Enough
Every kilowatt of AI compute connects to the utility grid through a transformer. Not metaphorically. A physical transformer — a custom-engineered device wound with high-purity copper and grain-oriented electrical steel, filled with insulating oil, weighing anywhere from 5 to 500 tons — sits at the boundary of every data center and the grid that feeds it. There is no shortcut around this device.

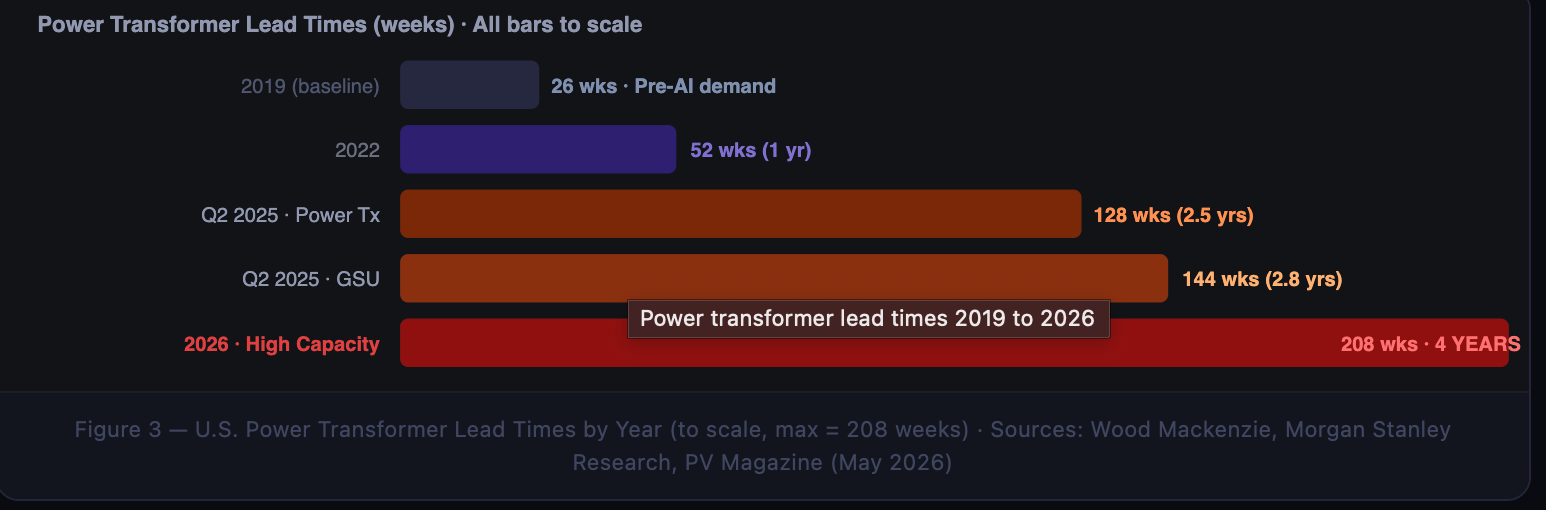
High-capacity units now quote 4-year lead times. Standard power transformers are at 128 weeks. Generator step-up units (GSUs) are at 144 weeks. Prices for power transformers have risen 77% since 2019; GSUs are up 45%. GSU demand itself increased 274% between 2019 and 2025. More than 50% of U.S. data centers planned for 2026 are expected to be delayed or canceled specifically because specialized electrical equipment cannot be sourced in time.

The causes are structural. U.S. transformer manufacturing capacity hasn’t meaningfully expanded in 15 years. The critical raw material inputs — grain-oriented electrical steel (GOES) and high-purity copper — are sourced primarily from Japan, South Korea, and increasingly China. Building a new transformer factory takes 3–5 years from capital commitment to first unit out the door. Nobody is going to solve this in a budget cycle.
Substations compound the problem. A large AI campus needing 100–500 MW of utility interconnect requires switchgear, protection relays, metering equipment, and civil infrastructure — each with its own lead time stack. U.S. grid interconnect permitting averages 3–5 years. The interconnect queue at regional transmission organizations currently holds over 2,600 GW of pending capacity requests. Total U.S. installed generation capacity is approximately 1,200 GW. The queue is more than double the grid.
The Implication for Data Center Timelines
If you’re announcing a 500 MW campus today and haven’t already ordered your transformers, you’re late by several years. The companies that hold the deepest transformer manufacturing relationships and the most durable customer contracts don’t need to outcompete anyone — the shortage is the moat.
The AI Power Stack: Five Layers from Grid to GPU
Power doesn’t teleport from the utility grid to an NVIDIA GPU. It moves through five distinct layers of infrastructure, each with its own supply chain, lead times, and companies controlling the chokepoints.

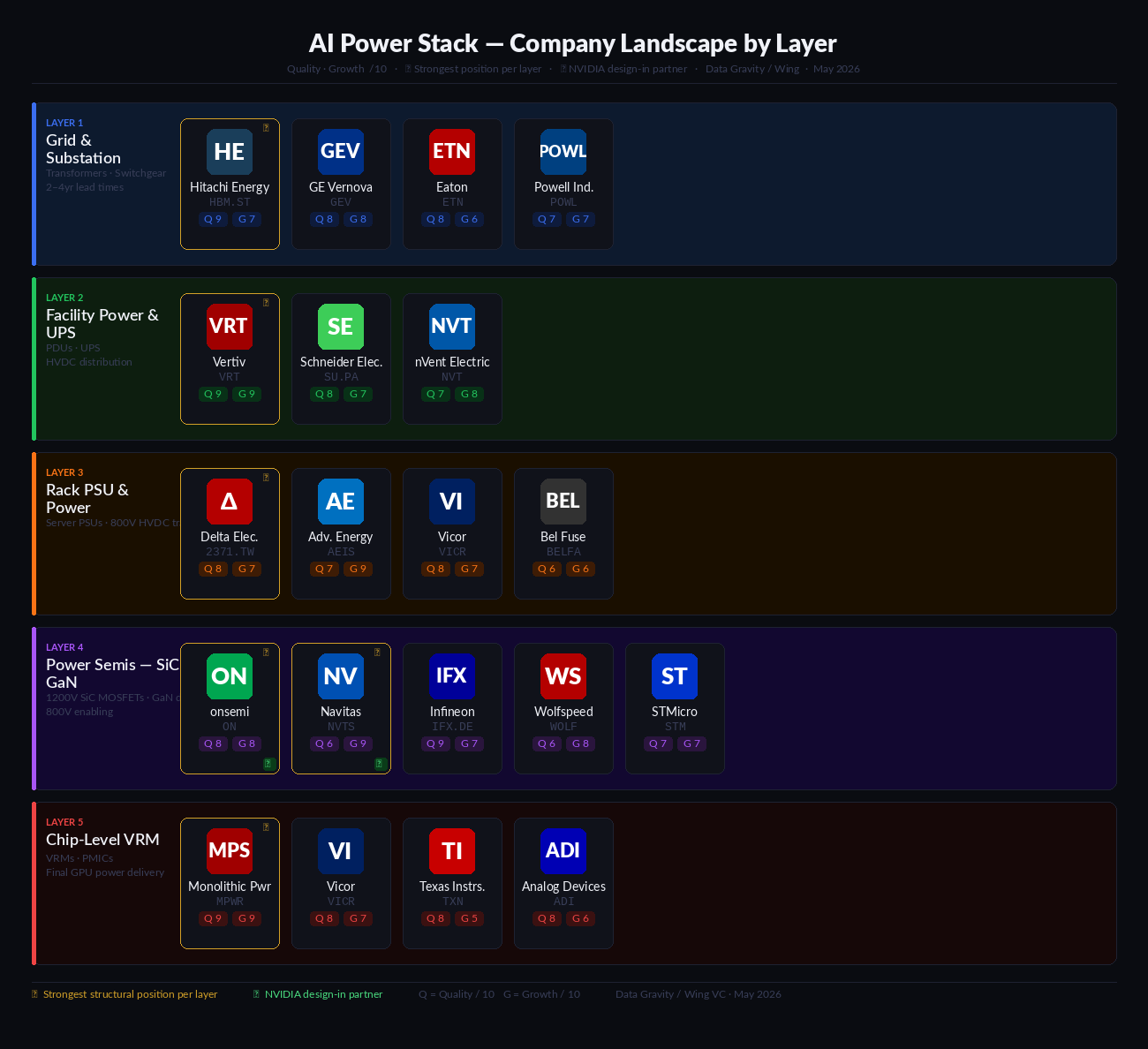
Layer 1 — Grid & Substation Infrastructure High-voltage transformers, switchgear, substations. The bottleneck before the building even exists. Lead times now 2–4 years. More than 50% of U.S. data centers planned for 2026 face delays here.
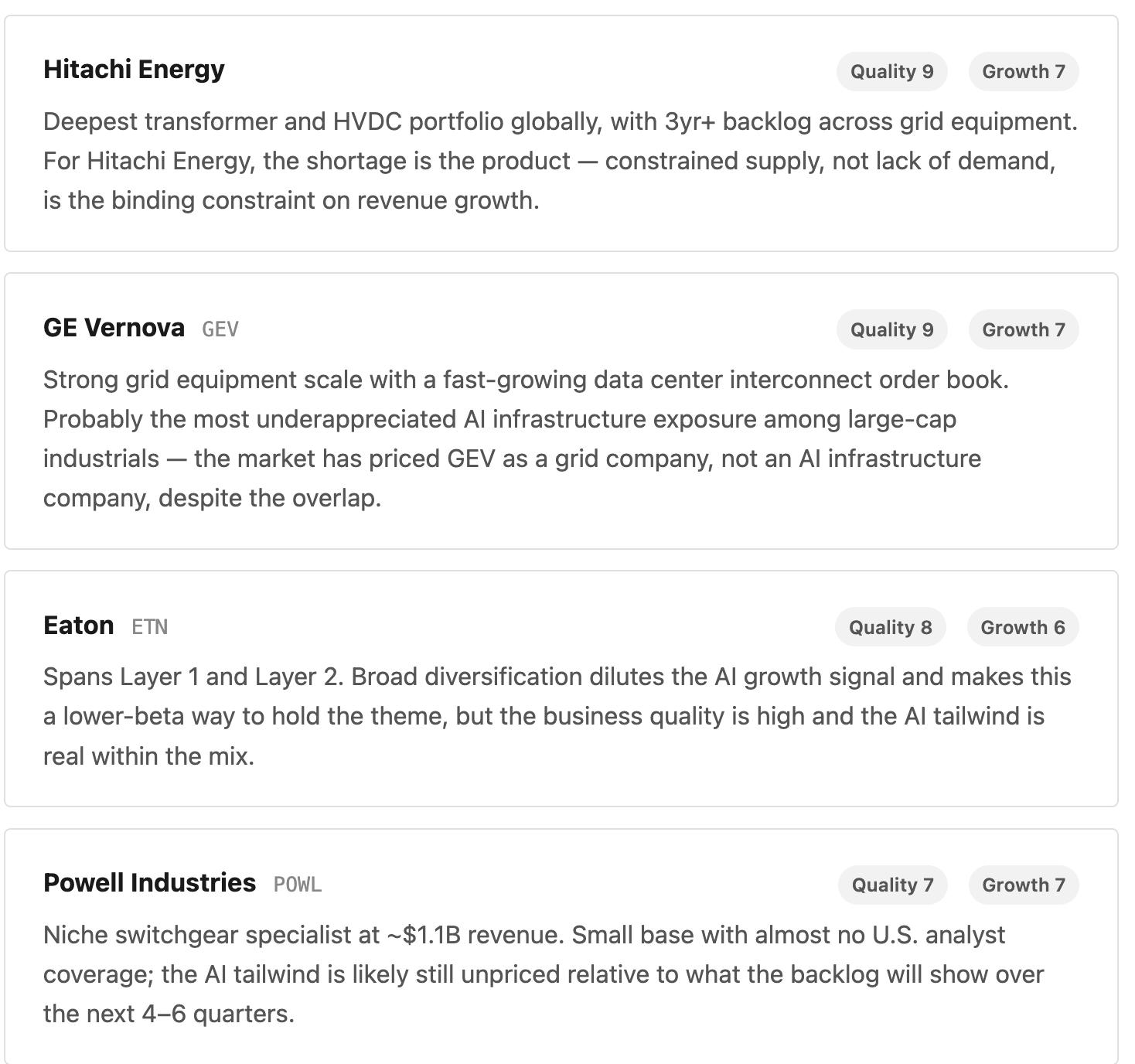
Layer 2 — Data Center Power Distribution & UPS PDUs, UPS systems, busways, coolant distribution. Everything between the utility interconnect and the server rack. This is where facility-level critical power lives.
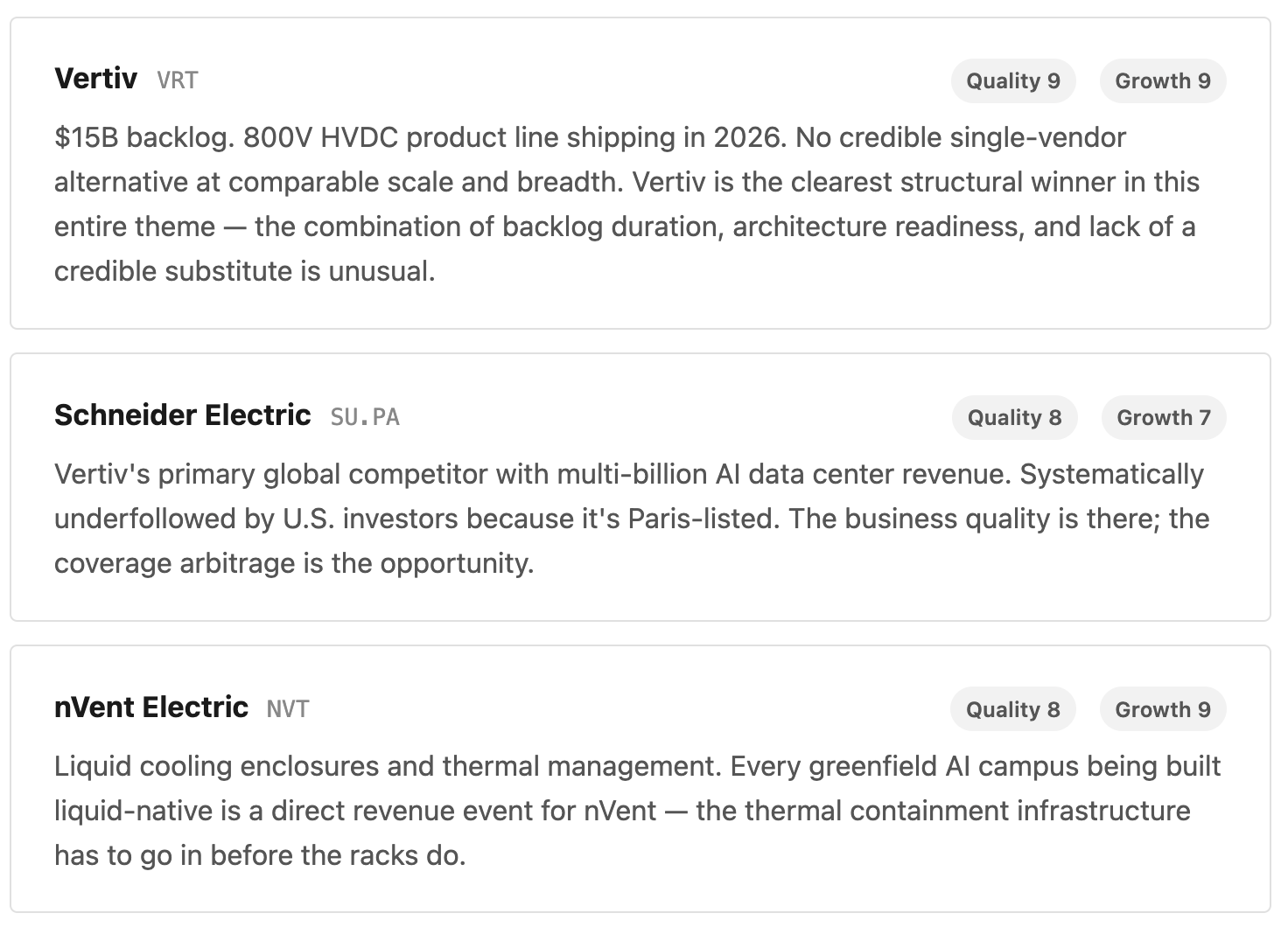
Layer 3 — Rack-Level Power & PSU Server power supply units and power shelves. Currently converting AC to 50V DC per server. The 800V HVDC transition — arriving with Vera Rubin CPX in 2027 — redesigns this entire layer from scratch.
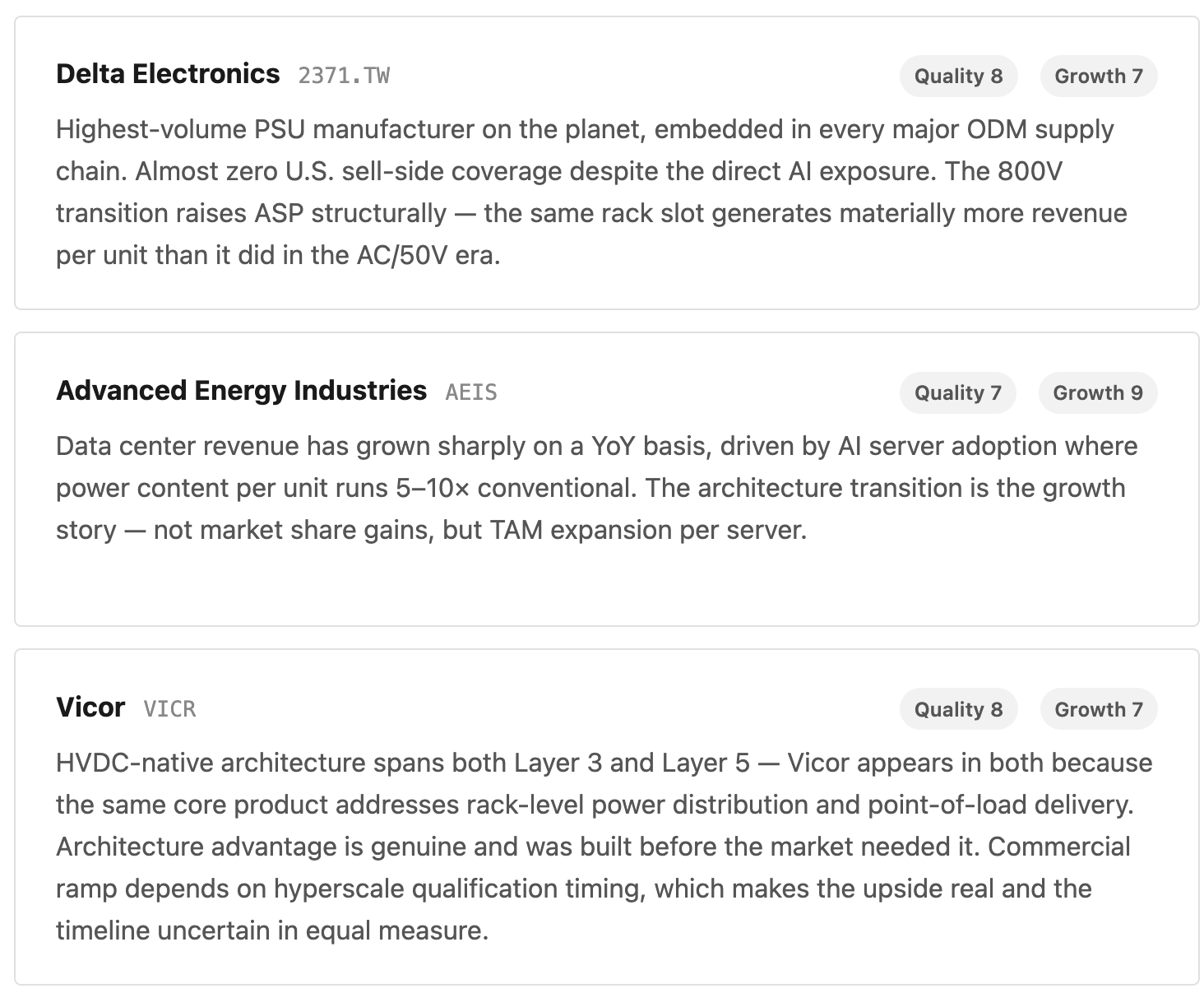
Layer 4 — Power Semiconductors (SiC & GaN) The materials that make the 800V transition physically possible. Silicon Carbide handles high-voltage rectification; Gallium Nitride handles high-frequency low-voltage conversion. Together they deliver 25–40% fewer conversion losses versus legacy silicon.
Layer 5 — Point-of-Load & Chip-Level VRM Voltage regulators and power management ICs that deliver precise, tightly regulated voltage directly to the GPU die. Highest dollar content per AI server. Smallest physical footprint. Closest to the compute.
Each layer has different lead times, different competitive dynamics, and different exposure to the 800V transition. The companies controlling the chokepoints at each level are covered below — but the macro argument stands on its own.
The Physics Don’t Negotiate
Everything else in AI infrastructure is debatable: which model architecture wins long-term, which cloud provider takes share, which REIT lands the best interconnect deal. The power problem is not debatable. It is a direct consequence of semiconductor physics and thermodynamics — more compute per chip requires more power per chip, more chips per rack requires more power per rack, and neither of those relationships bends for anyone’s financial model.
The scale of the requirement — 600 kW per rack, 4-year transformer lead times, an HVDC transition touching every electrical component from the substation to the GPU — is measurable, predictable, and already locked into NVIDIA’s product roadmap. These are not projections. They are engineering specifications.
The companies in this stack are not speculating on AI demand. They are selling into a confirmed equipment cycle with 2–4 year backlog visibility and architectural transitions that reset design-win competition every 18–24 months. For investors willing to work through the layers, the power electronics theme may be one of the most grounded, data-supported ways to own the AI infrastructure buildout — without paying for hope.
Note: If you are a founder/operator building in this space, please reach out to me.
This is the most concrete “the constraint is physics, not software” piece I’ve read, and it’s exactly why I think LatAm’s opening is real: when power infrastructure value per rack jumps 10×, transformers carry 4-year lead times, and the front end depends on grain-oriented electrical steel and high-purity copper, the jurisdictions with clean firm power and strategic minerals stop being peripheral and become part of the stack. Silicon Carbide rectifiers and liquid cooling are the new gating items, and Brazil sits on several of the upstream inputs. I made the case for the region capturing the infrastructure layer here: https://thiagopedicosaragiotto.substack.com/p/the-physical-layer-of-ai-why-latam
Spot on — and the closer nails it: "selling into a confirmed equipment cycle," not speculating on demand. Physics over narrative.
Where I'd push one level further: the bottleneck isn't the edge — its durability is. Spotting a tight supply chain is easy right now; the capital-cycle question is how long each one survives incoming capital. By that test, these layers split hard.
Transformers/grid is the durable one — 15 years of flat capacity, 3–5 years to build a plant, inputs sourced abroad. Capital can't respond fast enough; the shortage is the moat. SiC is the opposite: Chinese substrate expansion, EV overcapacity spilling in, Wolfspeed reorganized rather than retired. Same tightness today, but a fast supply response — usually where pricing power erodes first. Tight now, looser in 18–24 months.
Detection vs durability. That's the layer I keep working through. Great piece.