

Anthropic's Compute Advantage: Why Silicon Strategy is Becoming an AI Moat
Why Anthropic’s integration into hyperscaler silicon programs may give it a lasting advantage in the economics of frontier AI.

Compute is not a commodity for frontier AI labs. It is a structural cost input that determines margin, throughput, and model iteration velocity at scale. The divergence in how Anthropic, OpenAI, and Microsoft have approached silicon procurement over the last 18 months is not just a supply chain story — it is a compounding strategic gap.

Project Rainier, Anthropic and AWS
Anthropic has built what is today the most diversified and cost-efficient compute architecture among frontier AI labs. OpenAI remains almost entirely dependent on Nvidia. Microsoft’s internal chip program is years behind schedule. The structural implications favor Anthropic on unit economics and negotiating leverage as inference workloads scale. While Anthropic has had so much demand, it has struggled with up-time — its long-term strategy is the most fundamentally resilient.
One important caveat up front: compute advantage amplifies model advantage; it does not replace it. If a competitor’s models are materially better, customers absorb the higher token cost. The argument here is not that Anthropic wins because of infrastructure. The argument is that equivalent model quality delivered at 30–60% lower cost per token is a compounding advantage — on margin, on training budget, and on the pace of iteration.
The Structural Divide
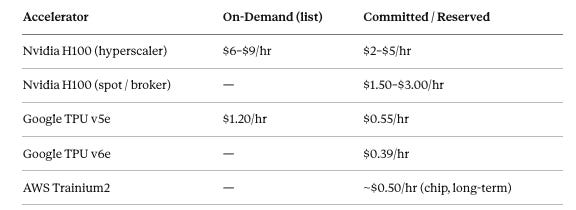
Every frontier model company faces the same binding constraint: various estimates put Nvidia at ~90%+ of the discrete GPU market and a dominant share of AI training accelerators deployed in the field, and that pricing power is real. H100 on-demand list pricing at major hyperscalers (AWS, Azure, GCP) peaked at $7–$8/hour; even after the 2025 oversupply correction drove spot and commodity-broker rates to $1.50–$3.00/hour, the published on-demand rate at hyperscalers still runs $6–$9/hour. Committed and reserved pricing falls somewhere in between — typically $2–$5/hour depending on contract length and volume — but requires capital-intensive multi-year lockup.
The question is not whether you can afford Nvidia GPUs. At scale, the question is whether Nvidia is the only lever you can pull, and what that dependency costs you annually.
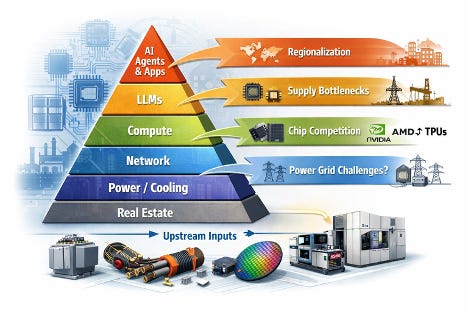
There is a layer beneath the GPU pricing question that gets less attention: HBM supply. The real bottleneck in high-density AI clusters is not the accelerator die — it is High Bandwidth Memory, packaging, and power density. TSMC’s CoWoS packaging capacity is a genuine constraint, and Nvidia’s pricing power is partly a downstream effect of controlling where that supply gets allocated. Any chip independence strategy that bypasses this layer — custom accelerators still require HBM stacks — is incomplete. True chip independence means secured HBM allocation, packaging slots, and power-deliverable data center capacity; the die is just the most visible part. Anthropic’s TPU and Trainium commitments are meaningful partly because Google and Amazon have negotiated their own HBM supply chains, transferring that allocation risk away from Anthropic.
Anthropic answered the dependency question structurally. OpenAI has not.
AI LAB COMPUTE STRATEGY (March 2026)
──────────────────────────────────────────────────────────────────────────
Lab Primary Stack Diversification Custom Silicon
──────────────────────────────────────────────────────────────────────────
Anthropic TPU v5/v6 + Trainium2 Multi-hyperscaler Operational now
+ Nvidia (research) operational today
OpenAI Nvidia H100/H200/B200 None at scale today Broadcom: 2027+
Microsoft Nvidia (dominant) Maia 200: 2 sites Maia 200: 2yr late
──────────────────────────────────────────────────────────────────────────The strategic conclusion this table points to: the winning economic model is not chip ownership — it is deep integration into a hyperscaler’s silicon program. Labs that pursued partnership-driven vertical integration have operational compute today. Labs that pursued ownership are years behind.
Anthropic: Dual-Hyperscaler, Dual-Accelerator
Project Rainier
In October 2025, Amazon opened Project Rainier — a purpose-built AI compute campus in Indiana with an $11 billion infrastructure investment. The cluster runs on Trainium2, AWS’s custom AI accelerator, and operates at an estimated scale that makes it among the largest operational AI compute clusters in the world. Anthropic is its primary tenant; training Claude is the primary workload.

The economics are the point. Trainium2 runs at approximately half the price of comparable Nvidia H100 instances in sustained workloads. Effective committed cost drops to roughly $0.50/chip/hour — compared to $2–$5/hour for H100 on committed or reserved contracts at equivalent hyperscaler rates. Anthropic has reported 50% cost reductions and material throughput gains versus GPU configurations on specific training runs.
Amazon’s total investment in Anthropic now stands at $8 billion (following the initial $4 billion in 2023 and a further tranche in late 2024). This is not a vendor relationship. It is a strategic alignment that gives Anthropic priority allocation on the Trainium roadmap and infrastructure access at cost.
The Google TPU Deal

On October 23, 2025, Anthropic announced an expansion of its Google Cloud partnership committing to 1 million TPUv7 Ironwood chips — over 1 gigawatt of compute capacity — coming online in 2026. The total deal value is approximately $52 billion. The structure is split: 400,000 TPUv7 chips purchased directly from Broadcom for roughly $10 billion in finished racks (Broadcom CEO Hock Tan confirmed the order publicly), with the remaining 600,000 chips rented through Google Cloud Platform at an estimated $42 billion in remaining performance obligations. Anthropic deploying purchased TPUs in its own facilities — rather than renting all capacity through GCP — signals a shift toward compute ownership, not just procurement. Google has invested $3 billion in Anthropic at approximately 10% equity, with an additional $1 billion committed in January 2025.
To house the direct-purchase TPU clusters, Anthropic selected Fluidstack — a UK-based data center operator — to build custom facilities in Texas and New York, part of a broader $50 billion domestic infrastructure commitment announced in late 2025. Fluidstack handles site construction, cabling, burn-in, and acceptance testing; their CEO described the partnership as enabling “rapid delivery of gigawatts of power” for frontier AI development. The sites are coming online throughout 2026, creating approximately 800 permanent jobs and 2,400 construction jobs.
TPUv7 Ironwood offers approximately 20–30% better raw performance than prior generations, and 50% better price-per-token at the system level versus equivalent GPU configurations. Google cites 60–65% lower power consumption per equivalent FP8 throughput versus GPU alternatives, which matters at gigawatt scale.
The realistic cost advantage for TPUs on LLM training workloads is 30–60% versus H100 clusters in comparable configurations. Claims of 4–10x cost improvement are achievable but apply to specific workloads with highly optimized kernels — not general production workloads. TPUs require custom compiler stacks (XLA), and most model teams optimize for CUDA first. The migration complexity is real: TPU software tooling, debugging infrastructure, and workload portability have historically lagged the Nvidia ecosystem by years. Anthropic’s engineering investment to operate across multiple architectures is a genuine cost that partially offsets the hardware savings, and the thesis depends on Anthropic having solved — or continuing to solve — those tooling gaps at scale.
Why Multi-Accelerator Is Structurally Distinct
Anthropic runs across three accelerator families: Google TPUs, AWS Trainium2, and Nvidia GPUs for research and CUDA-dependent workloads. Each platform is assigned to configurations where its price-performance profile is strongest.
Most frontier model companies rely on a single hyperscaler and a single accelerator family. Anthropic’s portfolio approach produces three advantages that are difficult to replicate quickly.

Cost arbitrage is the most obvious: the blended rate across TPUs and Trainium2 versus an all-Nvidia stack is 30–60% cheaper at comparable throughput on optimized workloads. Supply redundancy is the second: a capacity constraint at one vendor does not halt training. Negotiating leverage is the third, and arguably the most durable: when you are simultaneously committing to 1 million TPUs and a gigawatt-scale Trainium cluster, you have a credible alternative in every procurement conversation. Nvidia’s pricing power is real — but only against buyers with no alternative. It is worth noting that the mere existence of Google TPUs as a credible alternative was reportedly sufficient to save OpenAI — which has never deployed TPUs at scale — roughly 30% on its own Nvidia chip negotiations. Anthropic, which actually uses them at production scale, has considerably more leverage.
The total committed compute across Google TPUs and AWS Trainium now exceeds 2 gigawatts of dedicated capacity. On publicly available estimates, Anthropic’s annualized revenue run rate was in the range of $3–5 billion by late 2025, trending higher. The compute cost per token on this architecture is structurally lower than an Nvidia-only stack at similar scale.
OpenAI: Nvidia Dependency and an ASIC That Hasn’t Shipped
OpenAI’s production compute fleet runs on Nvidia GPUs. Published estimates place active GPU deployments at 100,000–200,000 H100/H200 chips, with additional Blackwell (GB200) orders in progress. These figures are not publicly confirmed. What is confirmed: Bloomberg estimated OpenAI’s quarterly Nvidia GPU spend at approximately $1.8 billion (roughly 6% of Nvidia’s total quarterly revenue at the time). At that run rate, Nvidia dependency is not a footnote — it is the primary cost structure.
Training compute spend in 2024 was approximately $3 billion; inference spend was approximately $1.8 billion. GPT-4 inference alone was projected at roughly $2.3 billion in 2024 — approximately 15x the original training cost. This asymmetry is the core inference economics problem: as models scale and usage grows, inference spend dominates, and the cost structure is entirely Nvidia’s.
Sam Altman has stated OpenAI would own “well over 1 million GPUs” by end of 2025, anchored by the $500 billion Stargate infrastructure program. But compute diversity within Stargate is less developed than the headline suggests.
The Broadcom ASIC: Production Starts H2 2026
On October 13, 2025, OpenAI and Broadcom announced co-development of custom AI accelerators targeting 10 gigawatts of capacity. OpenAI designs the architecture; Broadcom manufactures through TSMC. Production begins H2 2026. Meaningful deployment at scale is a 2027 event at the earliest.
For competitive purposes, this chip does not exist yet. OpenAI’s inference economics through at least 2026 are Nvidia economics. OpenAI also signed a $10 billion deal with Cerebras in January 2026 for 750 megawatts of low-latency inference compute through 2028 — more immediately actionable, with Q1 2026 first deployments, but narrow in scope.
The Stalled Nvidia Mega-Deal
In September 2024, Nvidia and OpenAI announced a letter of intent for a partnership in which Nvidia would invest up to $100 billion in OpenAI as OpenAI deployed at least 10 gigawatts of Nvidia systems.
As of March 2026, no definitive agreement has been signed. Nvidia CFO Colette Kress stated in December 2025 — two months after the announcement — that the $100 billion investment was “never a commitment.” The Wall Street Journal reported negotiations went on ice after internal Nvidia skepticism about OpenAI’s business model. No money has changed hands. Jensen also framed the investment as an invitation to invest from OpenAI, showing OpenAI is essentially at the mercy of Nvidia:
The circular economics were always awkward: Nvidia investing in OpenAI while OpenAI is its largest customer. The stall suggests the announcement was more strategic signaling than procurement commitment.
Microsoft: Announced, Not Shipped
Microsoft’s Maia chip program is the clearest example of the gap between custom silicon ambition and deployment reality.
Maia 100, announced November 2023, was deployed almost exclusively for internal Microsoft staff productivity workloads. It was not designed for generative AI inference at production scale. Two years post-announcement, it has not powered any significant external production service. Microsoft spent $31 billion on Nvidia AI chips in 2024 alone — the most of any cloud provider — while Maia 100 sat on the bench.
Maia 200, announced January 26, 2026, is a more serious design: TSMC 3nm, competitive FP8 throughput, 216GB HBM3e. On paper it is capable. In practice it entered limited deployment in two data centers in early 2026, over two years behind the original roadmap. Delays were caused by last-minute design changes, simulation instability, and high employee turnover affecting chip teams. By the time Maia 200 reaches meaningful Azure deployment, Nvidia’s Blackwell generation will be well-established in production across the industry.
The most telling data point is not the delay itself — chip design is genuinely hard, and two-year slips are not unusual. It is that Microsoft committed $31 billion in a single year to the vendor it was trying to reduce dependence on, while the alternative produced nothing deployable. Custom silicon timelines are measured in years, not quarters. Microsoft is not going to be chip-independent within this model generation cycle.
The Economics at Scale
At committed rates across a gigawatt-scale cluster, the blended cost advantage of TPU + Trainium over all-Nvidia runs roughly $1–2 billion per month on comparable throughput. Annualized, that is $12–$24 billion in structural cost advantage at full 2-gigawatt deployment — before accounting for power efficiency differentials, which are material at that scale. This assumes high utilization and workload fit; realized savings depend on kernel maturity and scheduling efficiency, both of which require sustained engineering investment to sustain.
Inference is projected to account for two-thirds of all compute spend in 2026, up from one-third in 2023. Every token served is a cost event. The cost per token is the unit economics of every API-facing AI business. Anthropic’s blended architecture makes that unit economics structurally better than a lab running equivalent inference on H100s — not by an order of magnitude, but by enough to matter at scale.
Implications
For Anthropic: The compute architecture is not just a cost advantage — it is a capacity advantage. At 2+ gigawatts of committed compute, Anthropic can run training runs that competitors cannot finance at equivalent cost. That compounds model iteration speed. The critical risk is engineering complexity: maintaining efficient workflows across three accelerator families and two compiler stacks requires real investment and creates coordination overhead that Nvidia-only stacks do not.
For OpenAI: The Broadcom ASIC is a credible long-term move, but it does not affect 2026 economics. As H100 spot prices have collapsed, OpenAI’s inference costs have improved — not because of anything OpenAI did, but because oversupply hit the GPU commodity market. That dynamic will tighten again as Blackwell deployment absorbs capacity through 2026. The one scenario that meaningfully narrows the gap: if Blackwell (GB200) delivers on its performance claims, inference cost per token on Nvidia hardware could fall 40–60% from H100 baselines, which compresses Anthropic’s current advantage. That is a real variable to watch.
For Microsoft: Maia 200 arriving two years late is a failure of execution, not strategy. The strategy was correct. But the more important signal for investors is the gap between ambition and output: $31 billion to Nvidia in one year while the internal program produced nothing deployable.
For investors: Compute cost structure is not typically a line item in AI company analysis. It should be. The cost per token served is the unit economics of every API-facing AI business. A 30–60% structural advantage at the compute layer does not translate 1:1 into margin — energy, networking, and engineering overhead all factor in — but it translates substantially. Anthropic’s path to positive gross margin is structurally easier from this compute foundation than from an all-Nvidia stack. At the scale these companies are targeting, the difference is not rounding error.
For the silicon market: The Anthropic model — dual-hyperscaler, multi-accelerator, committed long-term capacity — is likely to become the template for any frontier lab that reaches sufficient scale to negotiate it. Google and Amazon have strong incentives to subsidize Anthropic’s compute to validate their custom silicon against Nvidia at production scale; Anthropic gets below-market compute and Google and AWS get a credible reference proving TPU and Trainium can train state-of-the-art models. Ownership of chips is hard. Integration into the right silicon program is tractable, scalable, and — as this case shows — faster to gigawatt scale than any internal program has managed.
Summary
Anthropic has built the most cost-efficient and diversified compute architecture among frontier AI labs, anchored by Project Rainier — among the largest operational AI compute clusters in the world — and a commitment to 1 million TPUv7 Ironwood chips at 1+ gigawatt scale via a $52 billion deal structured across direct Broadcom purchase and GCP rental. Fluidstack is building the US data centers to house that compute. The blended economics are 30–60% cheaper per token than equivalent Nvidia H100 configurations on optimized workloads.
OpenAI remains structurally dependent on Nvidia through at least 2026. Its Broadcom ASIC is real but does not reach scale until 2027. The stalled $100 billion Nvidia investment deal is PR, not procurement strategy.
Microsoft’s Maia program is two years behind schedule. The company spent $31 billion on Nvidia chips in 2024 while its internal silicon produced nothing deployable for production.
Compute advantage amplifies model advantage. It does not replace it. But in an industry where inference spend is scaling faster than training spend, and where the cost of serving tokens will compound at every major model release, the lab that built the most efficient compute architecture 18 months ago is running a structurally different race than the one that didn’t.
Silicon strategy matters but the real bottleneck is power. Every custom ASIC roadmap is irrelevant if you can't get grid connection in time. Grid wait times are 3-5 years in most US markets. The companies solving power procurement will be key in the next months
The H100 debuted in 2022. I don't know why its the central focus of pricing comparison when B200 has been in the wild for quite a while now, and B300 is available too. You would obviously expect new late 2025, early 2026 silicon to outperform the nVidia model from 2022. Also, if you're paying for hour, how fast the system obviously matters deeply because it reduces training run time. Which is the point of the article. But it glosses over what that performance differential is between chips and again fails to account for B200 & B300 being significantly more capable than h100 and h200 chips. Especially in full system builds with accompanying improved networking, cooling, CPU, system RAM, etc. A B200 is ~36% more expensive per hour on CoreWeave. nVidia claims as high as 15x more inference throughput on DGX B200 vs DGX H100 and 3x more training throughput (https://www.nvidia.com/en-us/data-center/dgx-b200/). You get a lot more for that 36% price uplift. And with B300's massively larger VRAM window you can theoretically not need to rent as many to get the same job done even if it does cost more per hour. H100 just isnt the target anymore.