

China's Open-Weight Takeover
A field map of Chinese AI labs and platforms: Qwen, DeepSeek, Kimi, ByteDance, and Alibaba. How they came to dominate open models, work around compute constraints, and reshape the global AI landscape

For two years the consensus framing of the AI race was a capability gap: U.S. frontier labs led, China followed by 6–18 months, and export controls would widen the lag. As of mid-2026 that framing is the wrong abstraction. The gap that matters is no longer who trains the single best model — it is who supplies the tokens the world actually runs. On that axis China has already won the open layer.
The shift is measurable. On OpenRouter — the largest neutral router of LLM traffic, processing north of 20 trillion tokens per week — Chinese-origin models moved from a rounding error to the majority of consumption inside eighteen months. Anthropic and Google still command premium revenue per token, but on raw usage the center of gravity has moved offshore. This is what commoditization of a layer looks like in real time: the frontier becomes a feature, and the open, cheap, good-enough tier eats the volume.
This piece maps the field in three parts, plus the reframe the whole story turns on: (1) the labs and their relative share of use — Qwen, DeepSeek, Kimi, and the Alibaba/ByteDance platforms beneath them, including a deeper profile of who they are and what they are worth; (2) the chip ecosystem and supply — Huawei Ascend, the HBM bottleneck, and the offshore-neocloud workaround now being closed; and (3) ByteDance’s lead in video and media models, the one frontier where a Chinese lab is not catching up but setting the pace. Threaded through all three: the January 2025 DeepSeek panic predicted the wrong disruption.
Key points
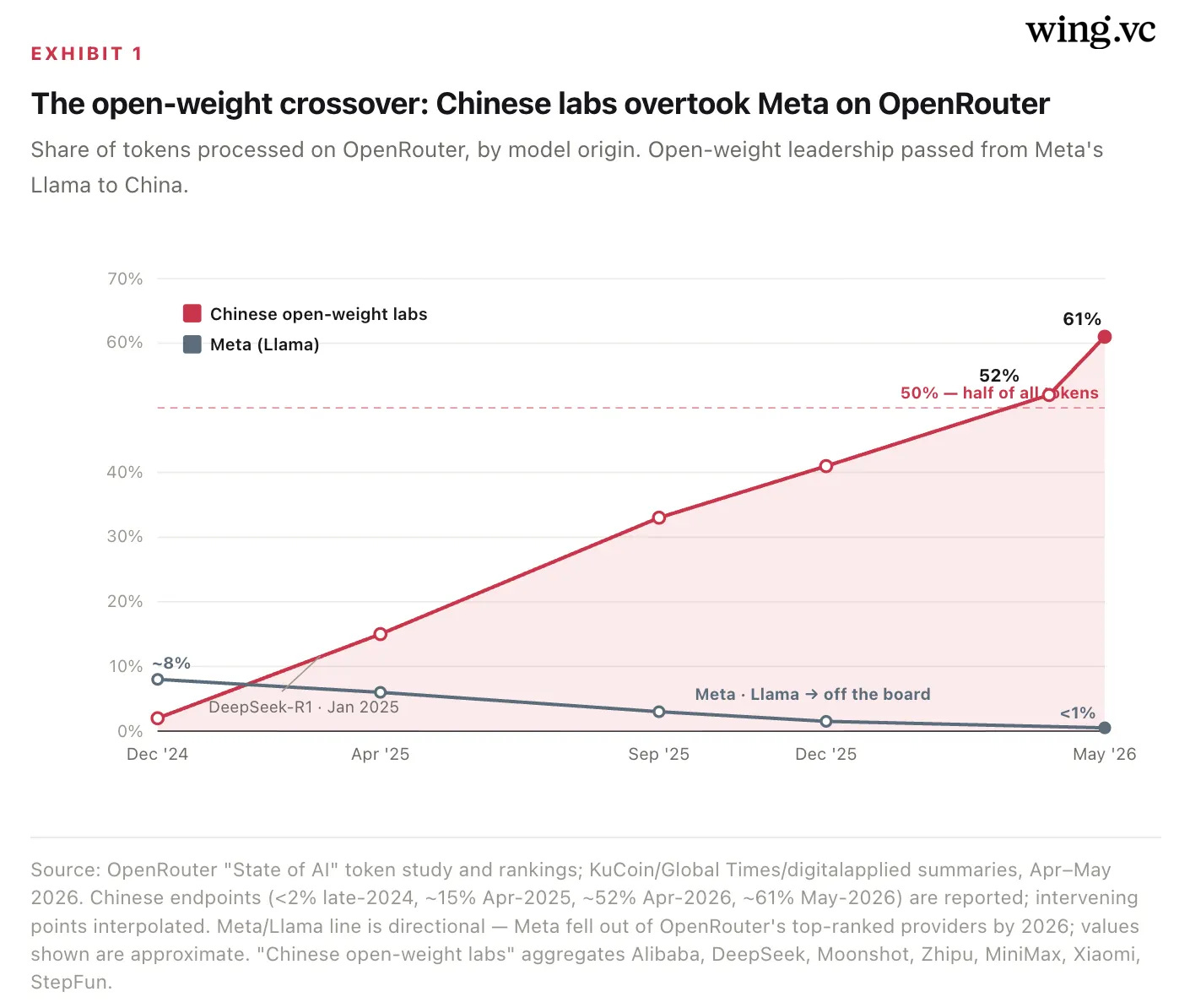
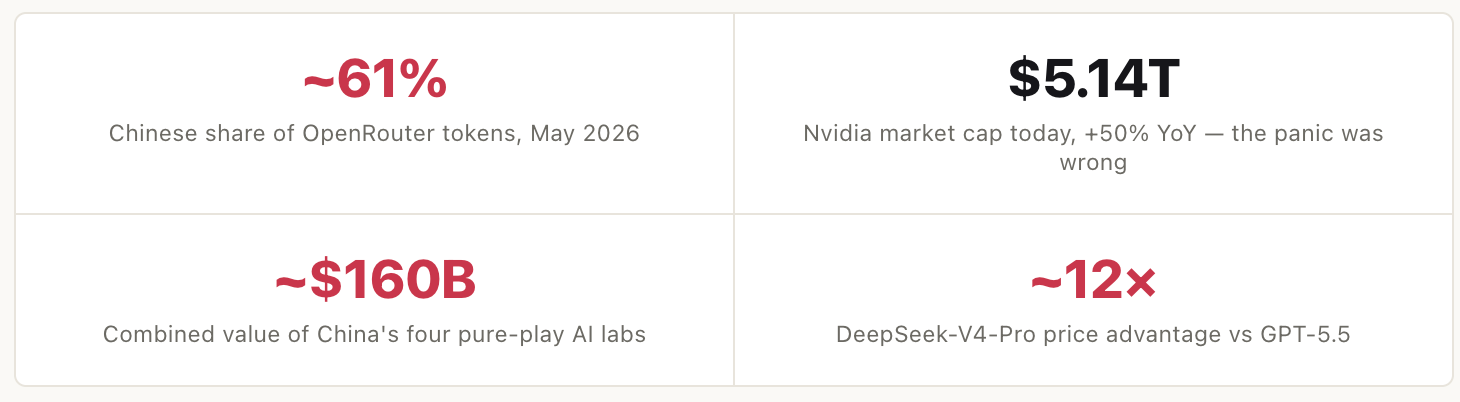
Distribution flipped. By May 2026, Chinese open-weight models were ~61% of all tokens consumed on OpenRouter, the largest neutral LLM router. Four of the five most-used models are Chinese — and Meta’s Llama, the open-weight leader two years ago, has fallen off the rankings entirely.
The DeepSeek panic was backwards. Markets feared a cheap Chinese model would crater compute demand — they wiped ~$600B off Nvidia in a day. Nvidia is now worth $5.14T (+50% YoY). Semis didn’t break; the disruption landed on model market share instead.
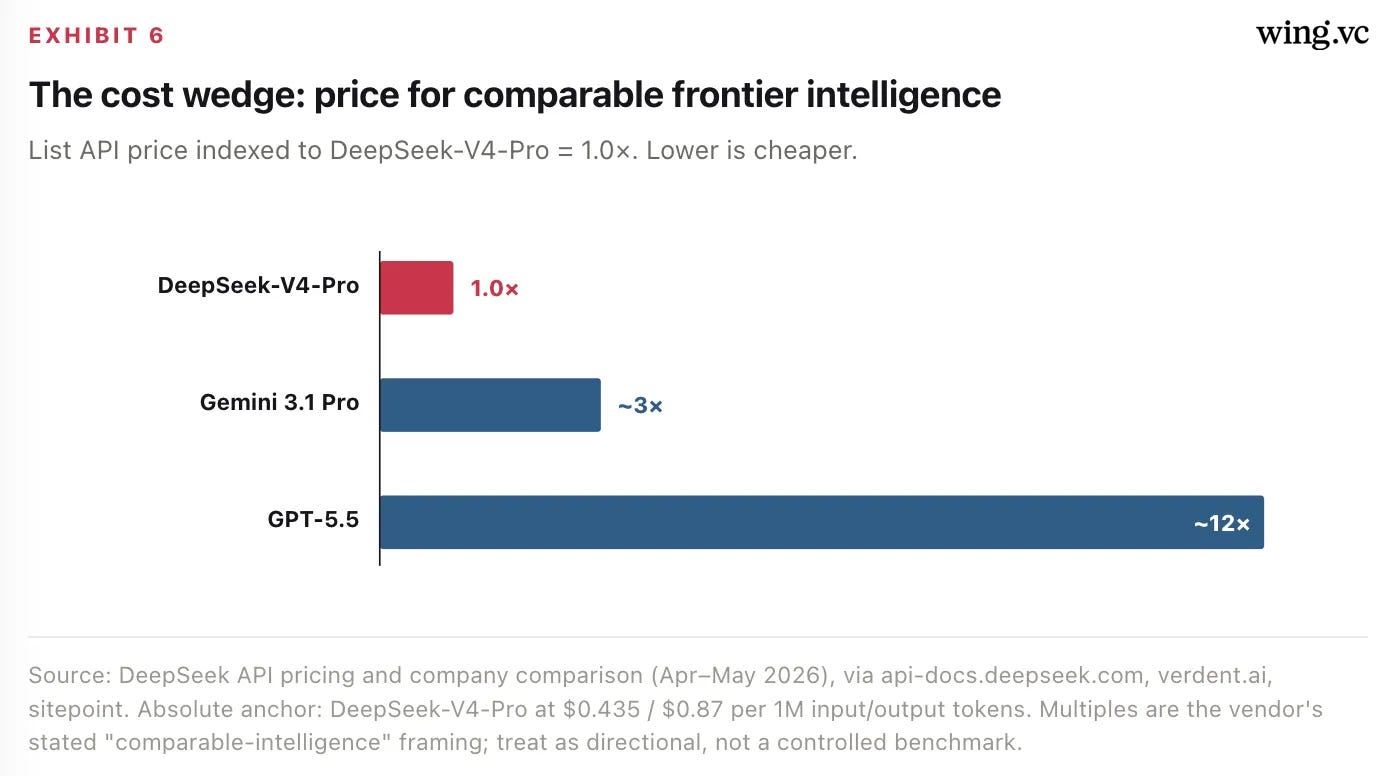
Price is the weapon. DeepSeek-V4-Pro lists ~12× under GPT-5.5 at comparable benchmark intelligence. Cost, not capability, is the wedge.
The labs are a portfolio, not a monolith. Qwen owns the ecosystem, DeepSeek price-performance, Kimi agentic cadence, ByteDance media. The pure-play labs alone are now worth ~$160B combined; their platform backers add >$1.5T.
Supply is HBM-bound, not logic-bound. SMIC can feed Huawei’s Ascend line; domestic HBM caps 2026 output near 250k–300k 910C-class packages. The binding constraint is memory.
The offshore-compute loophole closed. On May 31, 2026, BIS extended licensing to any China-parented buyer regardless of where its subsidiary sits — shutting the Singapore/Malaysia neocloud channel for new purchases.
The share shift: China captured the open layer in eighteen months
The single most important chart in Chinese AI is not a benchmark — it is a usage curve. OpenRouter’s token-routing data shows Chinese open-weight models crossing from negligible to majority share of all tokens processed between late 2024 and mid-2026. The inflection traces directly to DeepSeek-R1 in January 2025, which proved that a Chinese lab could match Western reasoning quality and release the weights, and to the subsequent flood of Qwen, Kimi, GLM, MiniMax, and Xiaomi MiMo releases that filled every price-performance niche beneath the U.S. frontier.
Two structural forces sit under the curve. First, workload mix shifted toward code: programming rose from ~11% of OpenRouter usage at the start of 2025 to more than 50% by mid-2026, and Chinese models are disproportionately strong and cheap on coding. Second, the router itself scaled ~4× year-over-year — from roughly 5T tokens/week in April 2025 to over 20T in April 2026 — so China did not just take share, it took share of a market that quadrupled.
Aggregate share understates the drama at the top of the table. The incumbents did not merely lose ground proportionally; Google’s token share collapsed from roughly 37% to 13% over the year as developers re-routed cost-sensitive workloads to open weights. Anthropic held the premium tier on reasoning and coding quality, and OpenAI’s share of routed volume — distinct from its first-party ChatGPT traffic — fell into single digits.
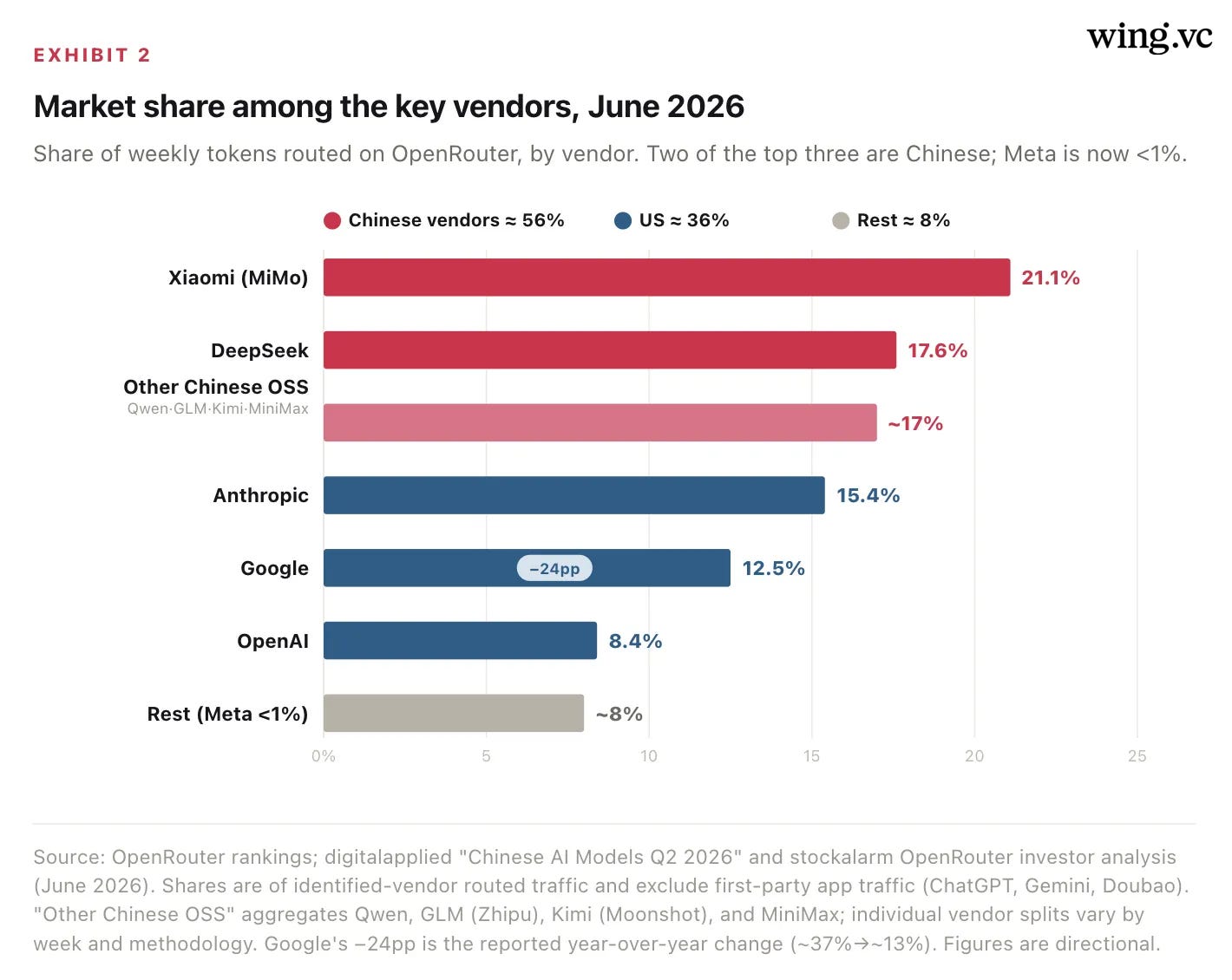
Read the vendor table closely and three things stand out. First, the single largest vendor is Xiaomi — not a name most Western investors associate with frontier AI — whose MiMo models alone take ~21% of routed tokens and ~22% of all coding traffic. Second, DeepSeek at ~17.6% outranks every U.S. lab, sitting above Anthropic’s 15.4% and well above Google and OpenAI. Third, Meta has effectively exited: the company that defined open-weight AI with Llama in 2023–24 has fallen below 1% of routed volume, displaced entirely by Chinese open weights. (Methodologies differ — counting only identified vendors puts the Chinese share near 56%, while the broader origin-based measure in Exhibit 1 reaches ~61% — but every cut tells the same story.)
The frontier is no longer where the volume is. Premium reasoning is a 15-point niche; the cheap, open, good-enough tier is the market — and it is overwhelmingly Chinese.
One caveat worth stating plainly: routed inference is not the whole market. First-party consumer traffic — ChatGPT, Gemini, Doubao — dwarfs the router, and Anthropic and OpenAI still capture the majority of industry revenue because they price at a premium and serve enterprises directly. OpenRouter is a leading indicator of where developers reach when nobody is watching the brand. On that signal, the open Chinese tier is the default.
The DeepSeek panic predicted the wrong disruption
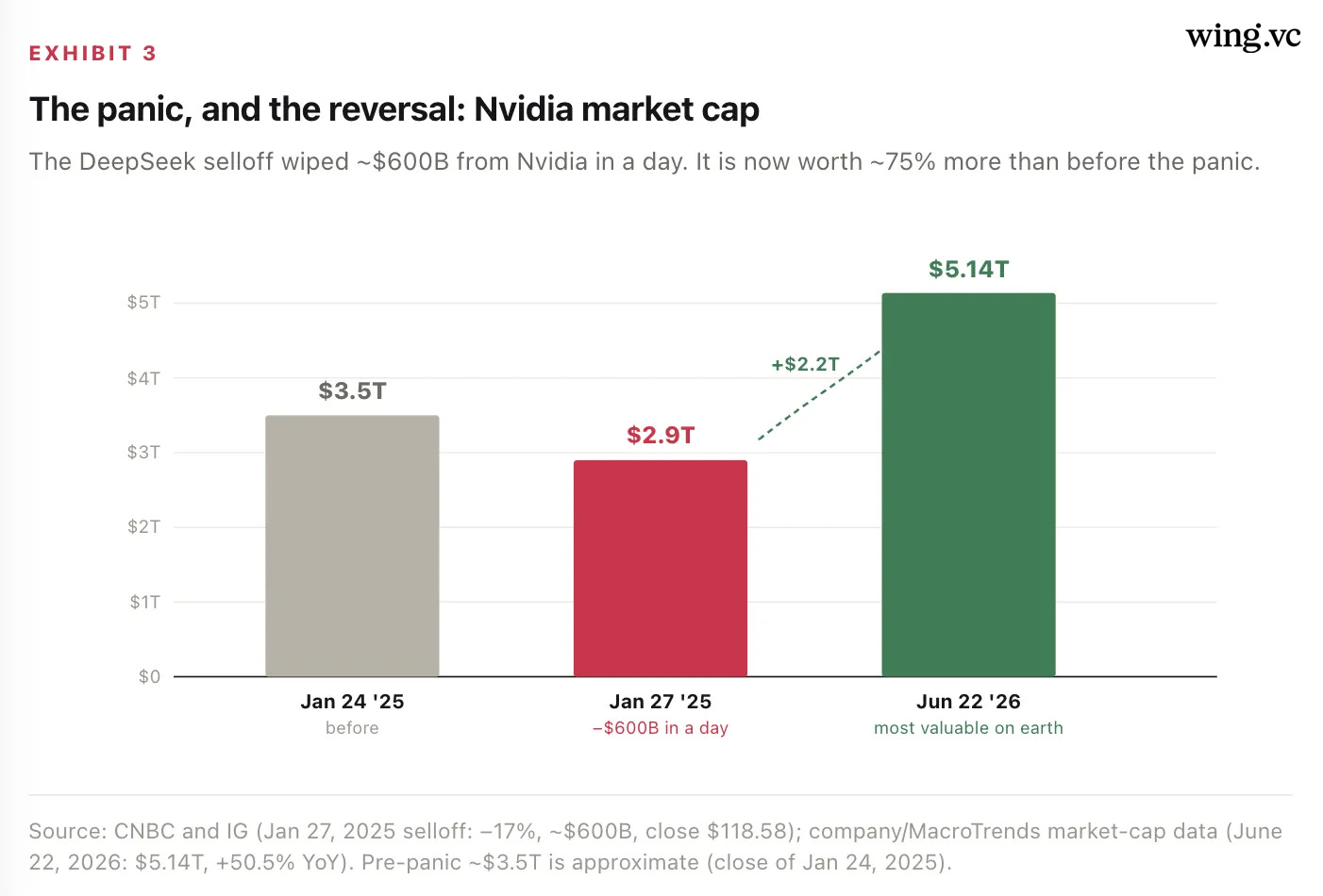
It is worth remembering what the market actually believed eighteen months ago. On January 27, 2025, days after DeepSeek-R1 showed a Chinese lab could match Western reasoning for a fraction of the training cost, investors concluded the obvious: if frontier intelligence is suddenly cheap, the demand for expensive accelerators must collapse. They sold. Nvidia fell 17% and shed roughly $600 billion in market value in a single session — the largest one-day loss in U.S. market history — and Broadcom dropped 17% (~$200B). The thesis was crisp: efficient Chinese models break the compute supercycle.
That thesis was wrong in the most complete way possible. By June 2026, Nvidia is worth $5.14 trillion, up ~50% year-over-year, the most valuable company on earth, and AI capex hit records on both sides of the Pacific. Cheaper intelligence did not shrink compute demand — it expanded it. Token volume on OpenRouter alone quadrupled; total inference grew faster than per-token efficiency improved. The Jevons dynamic held: drop the unit cost of intelligence and the world consumes vastly more of it.
What actually came true was the other half of the DeepSeek thesis — the half the market ignored while it was selling chips. DeepSeek did not destroy demand for compute. It demonstrated that Chinese labs would capture the model layer, and they did: from ~2% to ~61% of routed tokens. The disruption was real, but it landed one layer up from where the market priced it — on model-vendor share, where margins were already thin and are now mostly Chinese, not on silicon, which compounded. For an infrastructure investor, that is the single most important re-rating of the cycle: efficiency gains accrue to the compute layer and the distribution layer; they get competed away in the middle.
The Chinese Labs: A portfolio of specialists, not a single champion
Treating “Chinese AI” as one actor obscures the real structure. It is a portfolio of at least seven serious franchises, each with a different control point, business model, and owner. Three pure-play open-weight labs — DeepSeek, Moonshot (Kimi), and Zhipu (GLM) — compete on weights, price, and release cadence. Two platform giants — Alibaba (Qwen) and ByteDance (Doubao/Seed) — treat models as demand generation for cloud and consumer surfaces. And two more — MiniMax and Xiaomi (MiMo) — have become major suppliers almost sideways, the first out of a content-generation business, the second out of a phone company. What they share is a strategy: release open weights, price at a fraction of the U.S. frontier, and let distribution compound.
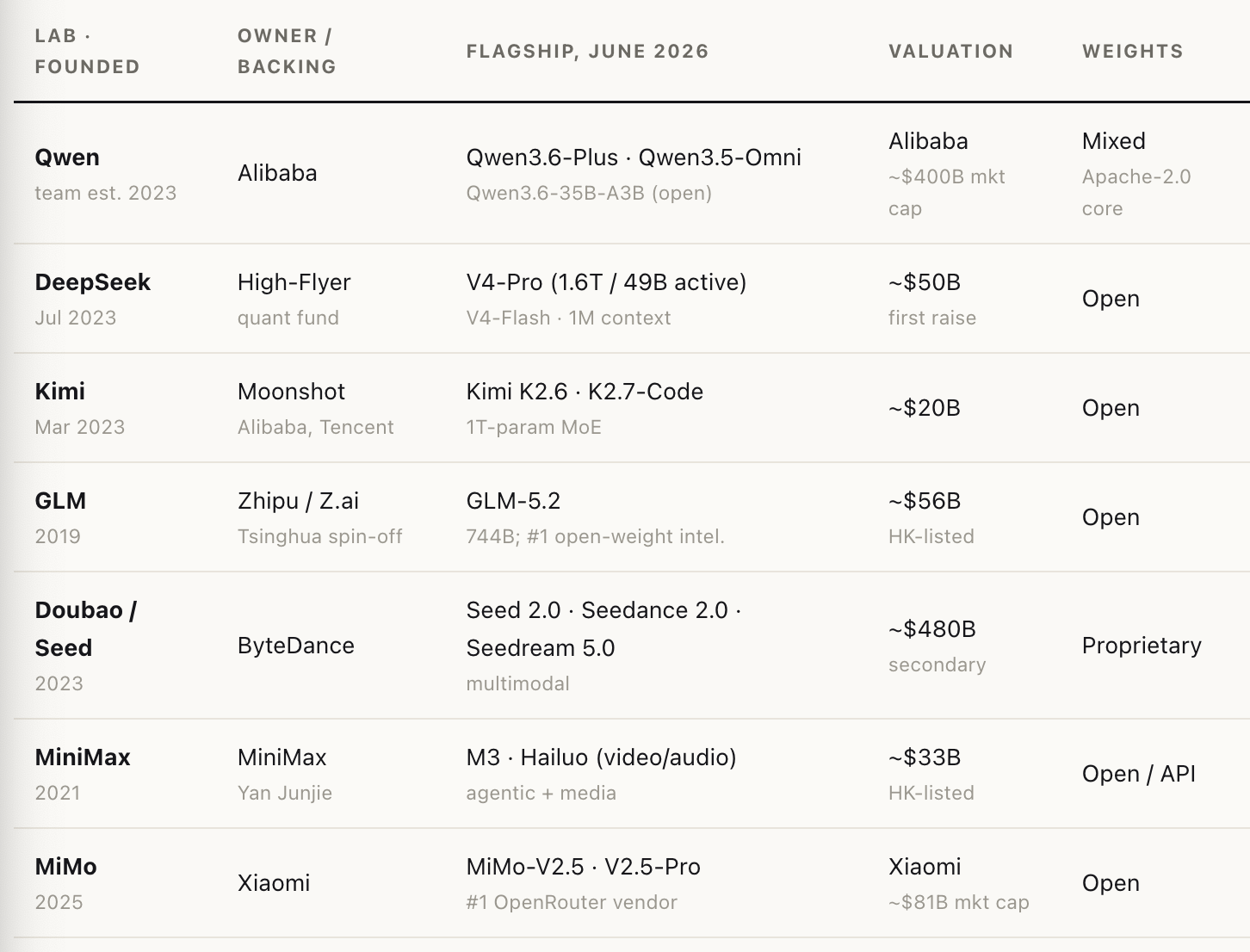
The aggregate is the statistic that should reframe the category for any investor still treating these as research curiosities. The four pure-play Chinese AI labs — Zhipu, DeepSeek, MiniMax, and Moonshot — are now worth roughly $159B combined, up from a near-zero base eighteen months ago. DeepSeek alone went from a quant fund’s side project to a reported ~$50B first external round (founder Liang Wenfeng personally subscribing ~$3B, ~40% of it). Behind them stand platform owners — Tencent, ByteDance, Alibaba — carrying more than $1.5 trillion of AI-exposed market value.
Qwen / Alibaba — the ecosystem standard
Qwen is the most important open-model franchise in the world, and the gap is not close. It has surpassed 1 billion cumulative downloads on Hugging Face, overtaking Meta’s Llama as the most-downloaded open model, and now anchors more than 200,000 Qwen-tagged models and over 113,000 derivatives — more than Google and Meta’s base families combined. Roughly 40% of all new LLM derivatives created on Hugging Face are now Qwen-based, and China accounted for ~41% of all Hub downloads over the trailing year. In June 2026 trending rankings, Chinese open models held five of the top ten slots.

The strategic logic is not philanthropy. Alibaba runs Qwen as a top-of-funnel for Alibaba Cloud: open weights seed adoption, paid inference and fine-tuning capture the monetizable tail. It is working. Cloud Intelligence Group revenue reached ¥158.1B in FY2026 (+34% YoY), AI-related product revenue posted triple-digit growth for eleven consecutive quarters, AI now drives ~30% of external cloud revenue (a ~$5B run-rate), and the firm pushed capex to ¥126.1B for the year. Open weights are the cheapest customer-acquisition channel in infrastructure.
DeepSeek — the price-performance frontier
DeepSeek is the lab that started the repricing. Founded in July 2023 by Liang Wenfeng as an offshoot of his quantitative hedge fund High-Flyer, it has no consumer platform to defend and no cloud P&L to protect — just a model franchise, a stockpile of GPUs the fund had accumulated for trading, and a founder who treats open weights as ideology. Its R1 release in January 2025, trained for a reported <$6M on export-compliant H800s, is what triggered the Nvidia selloff. In 2026 it took its first outside capital at a reported ~$45–50B valuation, with Liang personally subscribing ~$3B — a structure that keeps control firmly with the founder.
The product strategy is to undercut. The V4 family (April 2026) spans V4-Pro (1.6T parameters, 49B activated) and V4-Flash (284B / 13B activated), both at 1M-token context. List pricing of $0.435 / $0.87 per 1M input/output tokens places it roughly 3× below Gemini 3.1 Pro and ~12× below GPT-5.5 at comparable benchmark intelligence. The result is measurable U.S.
pull: DeepSeek’s share of token usage on Vercel rose from under 1% to ~17% by May 2026, even as its share of revenue stayed near 1% — the clearest single illustration of how cheap the open tier has made intelligence.
Kimi / Moonshot — agentic coding and cadence
Moonshot, founded in March 2023 by Tsinghua- and Carnegie Mellon-trained researcher Yang Zhilin, competes on two axes incumbents struggle to match: coding quality and shipping speed. Kimi K2.6 (April 20, 2026), a 1T-parameter MoE, ties GPT-5.5 on SWE-Bench Pro (58.6%) and leads Humanity’s Last Exam with tools (54.0) — ahead of GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro on that benchmark — at roughly 80% lower cost, with an agent-swarm architecture that coordinates up to 100 parallel sub-agents. Artificial Analysis ranks it #1 among open-weight systems. Then came K2.7-Code on June 12 — the fifth major Kimi release in under a year, cutting reasoning-token usage ~30%. That cadence is the moat: Moonshot iterates faster than enterprise procurement cycles.
The market is paying for it. Moonshot raised $2B at a $20B valuation in May 2026 (cumulative ~$3.9B in six months, the most of any Chinese LLM startup), with Alibaba and Tencent on the cap table, as revenue ran from a $100M annualized run-rate in March to $200M in April. Of the pure-play labs, Moonshot has best converted benchmark leadership into commercial momentum.
ByteDance — scale, media, and the cloud beneath it
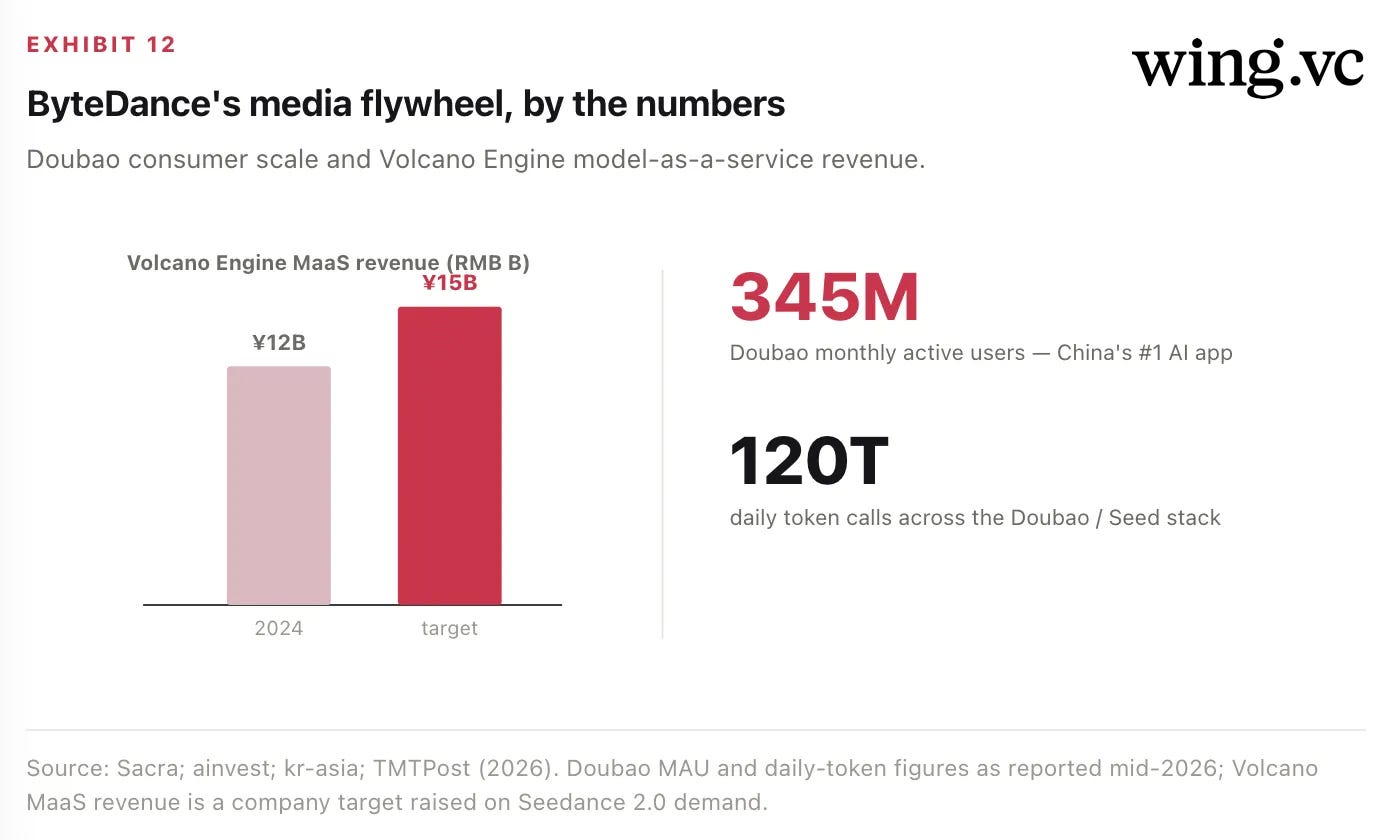
ByteDance is the platform counterweight to the open-weight labs, and — at a ~$480B secondary-market valuation (General Atlantic has tested $550B) — by far the most valuable of them. Its Doubao assistant reached 345M monthly active users and 120 trillion daily token calls, and its Volcano Engine cloud lifted its model-as-a-service revenue target to ¥15B (~$2.2B). ByteDance keeps its best models proprietary and behind APIs — the opposite of Qwen — because it monetizes attention and cloud, not weights, and it is far enough along on a self-designed inference chip (targeting 100k+ units in 2026) to hedge its Nvidia dependence. Its decisive lead, covered in Section 4, is in video.
The next tier — GLM, MiniMax, and the Xiaomi surprise
Three more names matter for anyone sizing the supply base. Zhipu (Z.ai), a 2019 Tsinghua spin-off now listed in Hong Kong at ~$56B, shipped GLM-5.2 — a 744B-parameter model that leads the Artificial Analysis Intelligence Index among open weights in June 2026, and is the strongest of the cohort in enterprise and government deployments. MiniMax (founded 2021 by ex-SenseTime researcher Yan Junjie; HK-listed ~$33B) pairs the M-series LLMs with its Hailuo video/audio models, straddling text and media. And the genuine surprise is Xiaomi: its MiMo models, an afterthought to a phone-and-EV company, are by several weekly counts the single most-used vendor on OpenRouter (~21% of tokens, ~22% of coding traffic). That a handset maker can lead global open-model usage is the strongest evidence that distribution and price, not research prestige, now decide share.
Chips and Supply: Huawei silicon, an HBM ceiling, and the offshore workaround
The software story above runs on hardware these labs increasingly cannot buy at will. China’s compute supply now rests on three legs: a maturing domestic accelerator in Huawei’s Ascend line, a still-open but narrowing channel to Nvidia silicon, and — until five weeks ago — a large offshore rental market in Southeast Asia. Each leg has a different fragility.
Huawei Ascend: competitive at the rack, constrained at the wafer’s edge
Huawei’s CloudMatrix 384 (CM384) is the clearest evidence that China can build at the system level. It lashes 384 Ascend 910C dies into a single super-node delivering roughly 300 PFLOPs of dense BF16 — close to 2× the compute of Nvidia’s GB200 NVL72 — by trading power efficiency for brute scale. At the rack, China has an answer. The constraint sits one layer down. Per SemiAnalysis, SMIC’s logic capacity is no longer the binding limit; high-bandwidth memory is. Domestic HBM from CXMT is projected at ~2.0M stacks in 2026, enough to finish only ~250,000–300,000 910C-class packages.
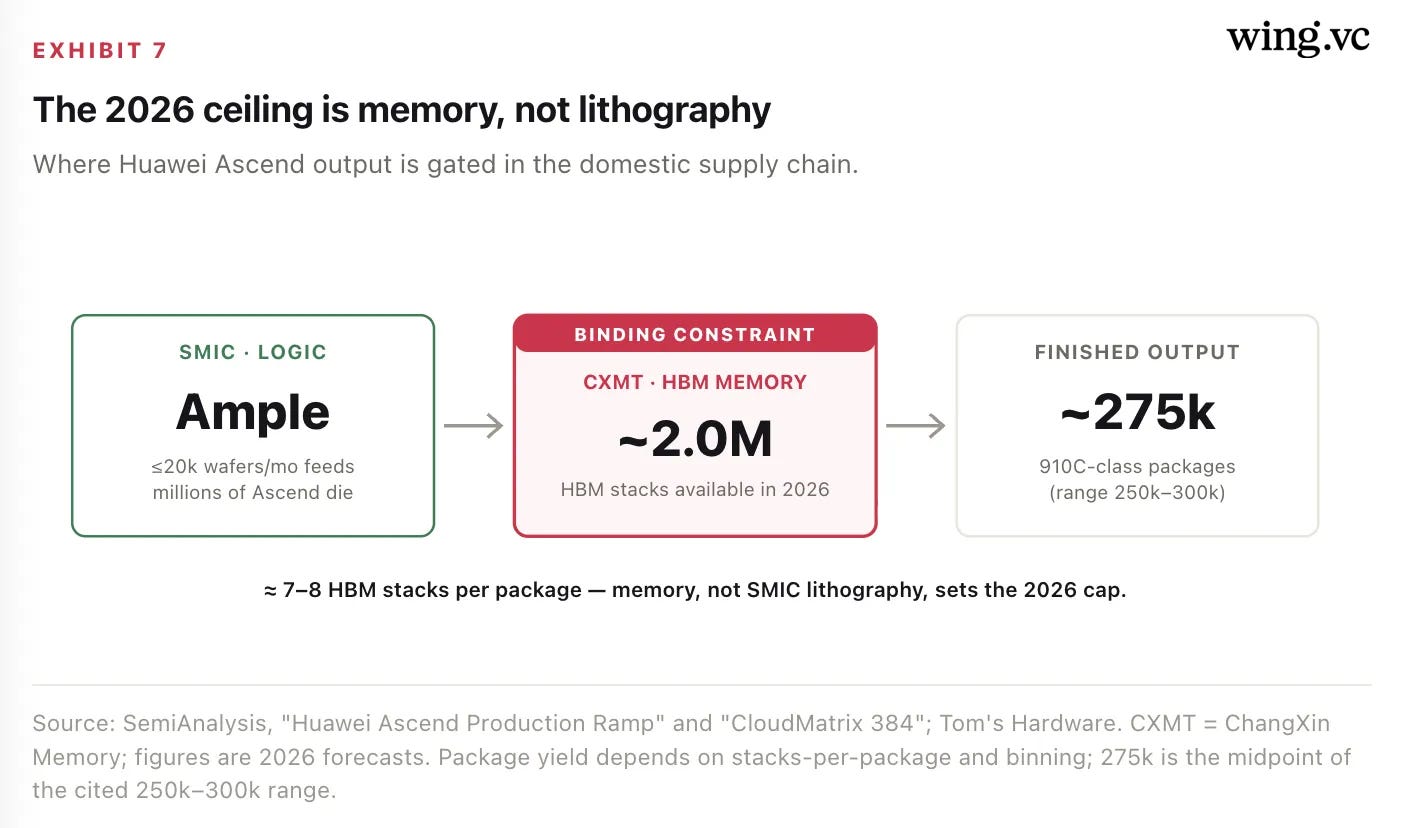
For investors, the takeaway is that China’s accelerator output is small relative to demand — a few hundred thousand high-end packages against domestic compute appetite measured in millions of GPU-equivalents — and that the leverage point for U.S. policy has moved from logic (SMIC, lithography) to memory (HBM, CXMT/Samsung/SK Hynix). The 910C is also less power-efficient than Nvidia’s parts, so China is spending its scarce energy and capital budget less efficiently per useful FLOP. That gap is closing, but it is real and it is the reason the offshore-Nvidia channel mattered so much.
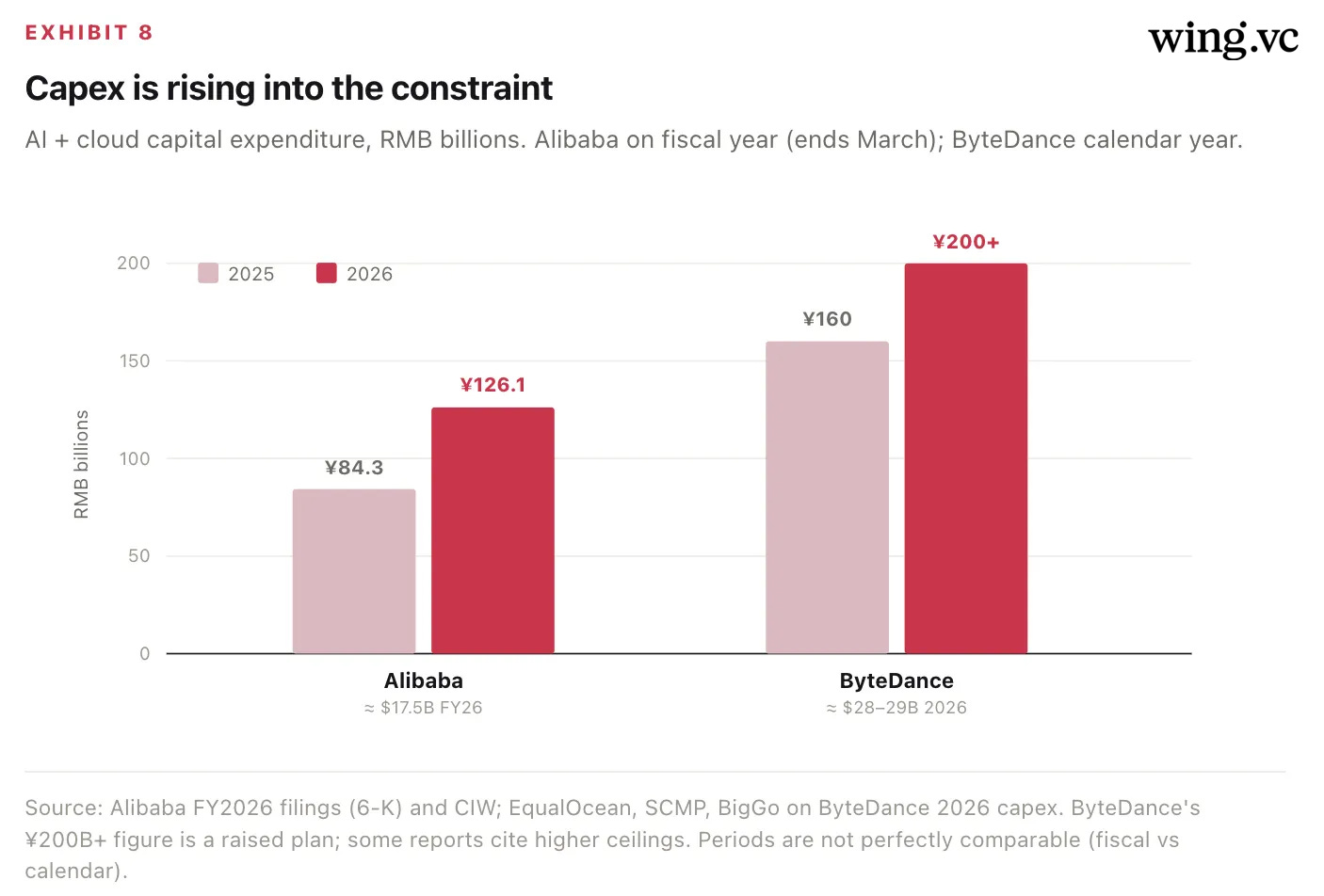
The capex arms race
Constrained supply has not slowed spending — it has accelerated it, as the platform owners race to lock up whatever compute they can. Alibaba lifted full-year capex to ¥126.1B (≈ $17.5B), up from ¥84.3B. ByteDance is the more aggressive spender, raising 2026 capex past ¥200B (≈ $28–29B), with roughly half historically earmarked for AI chips — and some reports put its ceiling materially higher.
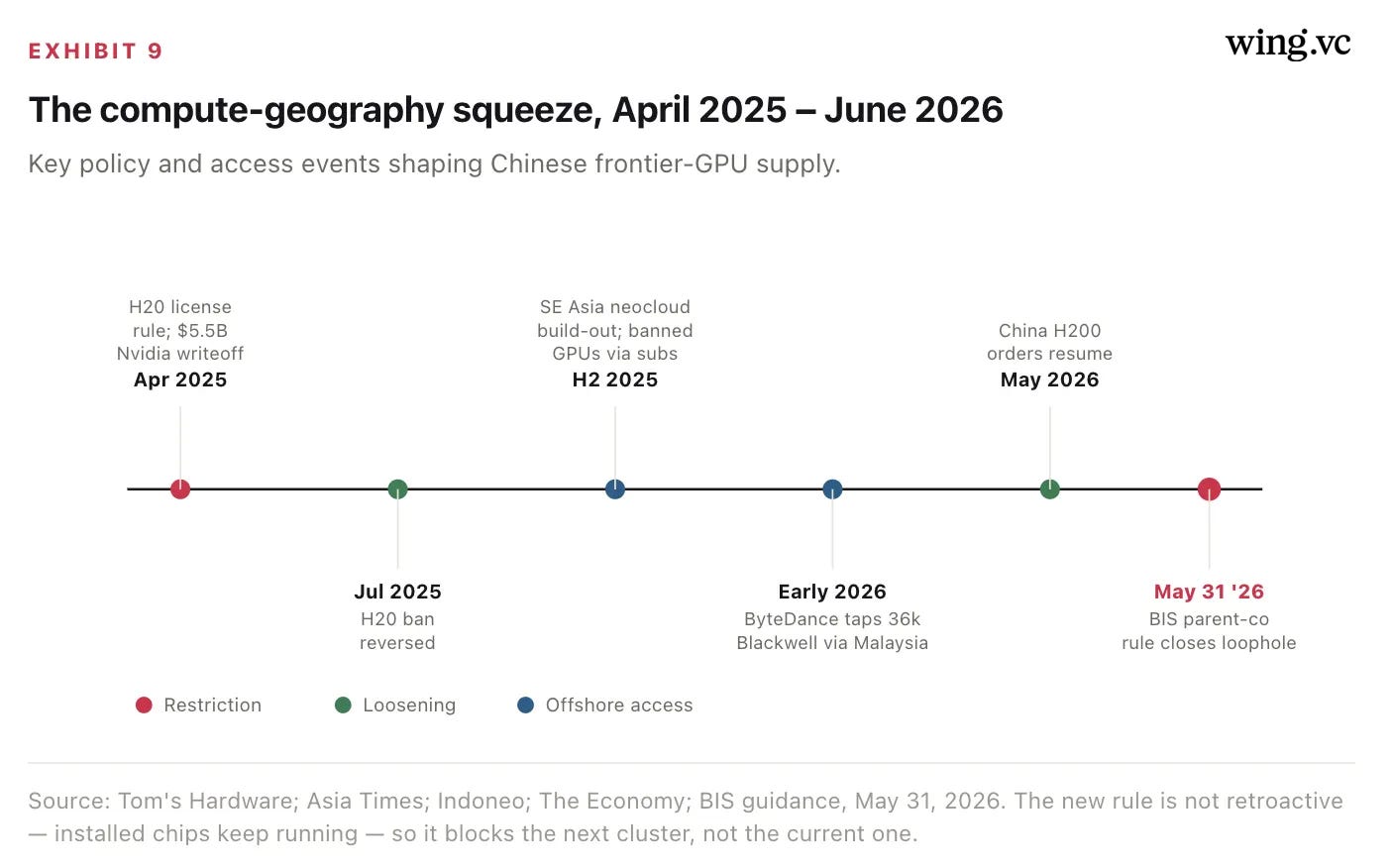
The offshore-compute loophole — opened, exploited, and just closed
Because the best Nvidia parts were export-restricted and Huawei output was capped, Chinese labs did the rational thing: they rented frontier GPUs offshore. For roughly a year, a China-parented company could stand up — or rent from — a data center in Singapore, Malaysia, or Indonesia and run banned Blackwell-class silicon legally, because the hardware never shipped to the mainland. ByteDance reportedly secured access to a 36,000-GPU Blackwell cluster through a Malaysian cloud operator, a deal Nvidia confirmed as compliant. That channel narrowed sharply on May 31, 2026, when BIS extended licensing to any buyer whose ultimate parent sits in China or Macau, regardless of where the subsidiary is registered.
The net picture on compute: China can build competitive systems but cannot yet make enough of the memory that finishes them, the cheapest path to frontier silicon (offshore rental) just narrowed, and the policy lever has migrated to HBM. Expect three responses — a domestic HBM build-out (CXMT capacity expansion), continued Ascend system scaling despite efficiency penalties, and more inference pushed onto the very open models from Section 2, which are cheap enough to run on constrained hardware. Scarcity of training compute is precisely why the open, efficient model tier is a strategic asset, not just a commercial one.
ByteDance and the video frontier: Not catch up — it is ahead
In text and code, the Chinese labs win on price and distribution while the U.S. frontier still sets the quality ceiling. In video and media generation, that ceiling is now Chinese. The shift is partly capability and partly economics: video models are absurdly expensive to serve, and the firms that win are the ones that can subsidize generation against another business — ads, short-form, a billion-user app. ByteDance has exactly that, and it has used it to take the lead.
ByteDance’s Seedance 2.0 (February 12, 2026) is a unified multimodal audio-video model: text, image, audio, and video in; synchronized video plus dual-channel stereo audio out, in a single forward pass, with native multi-shot inside one 15-second render. It topped Artificial Analysis’s Video Arena for both text-to-video and image-to-video from launch, and remains #1 on the with-audio board. Its only real challenger is also Chinese — Alibaba’s HappyHorse-1.0 — with Google’s Veo 3.1 holding third and Kuaishou’s Kling 3.0 placing four entries in the top ten.
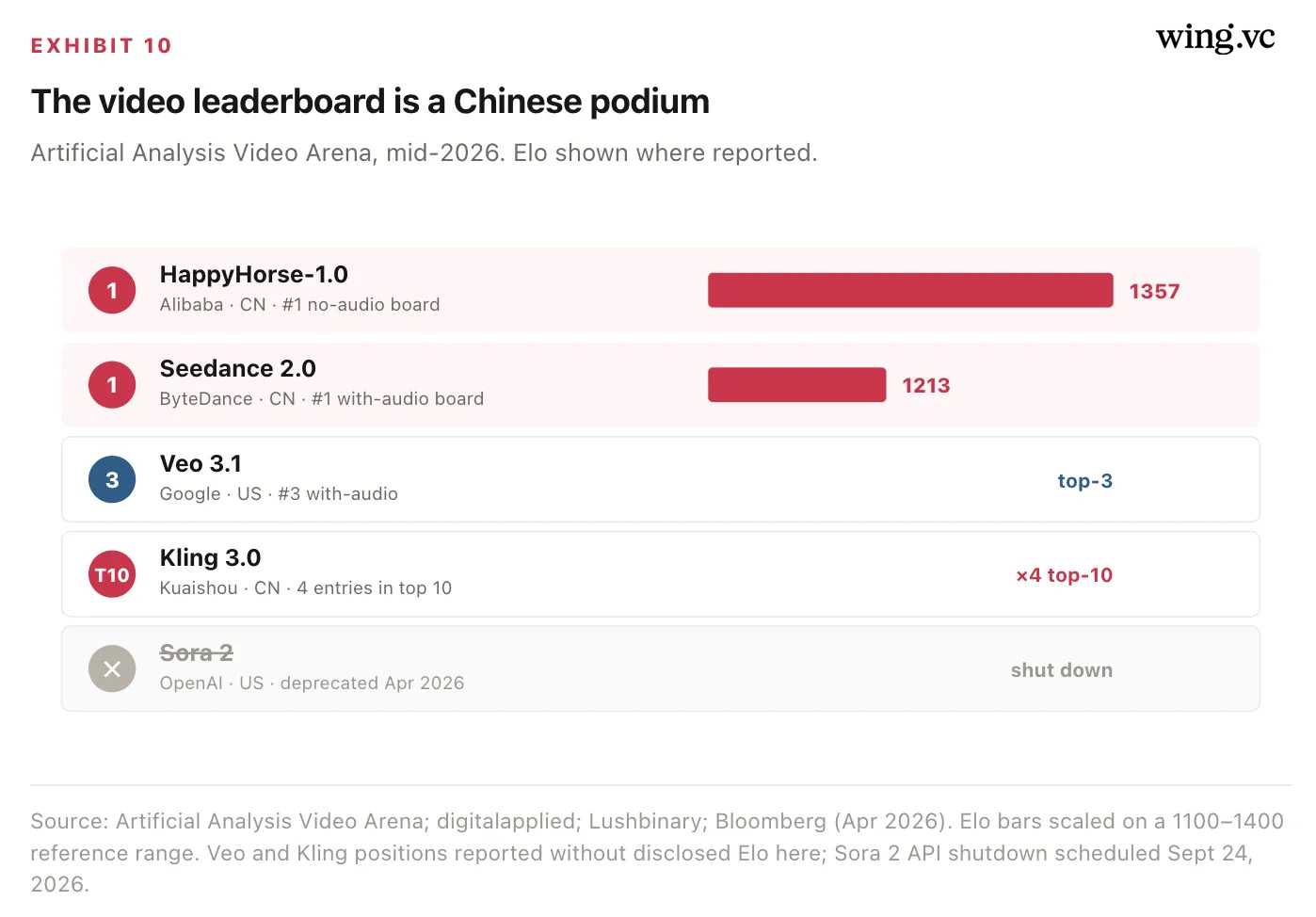
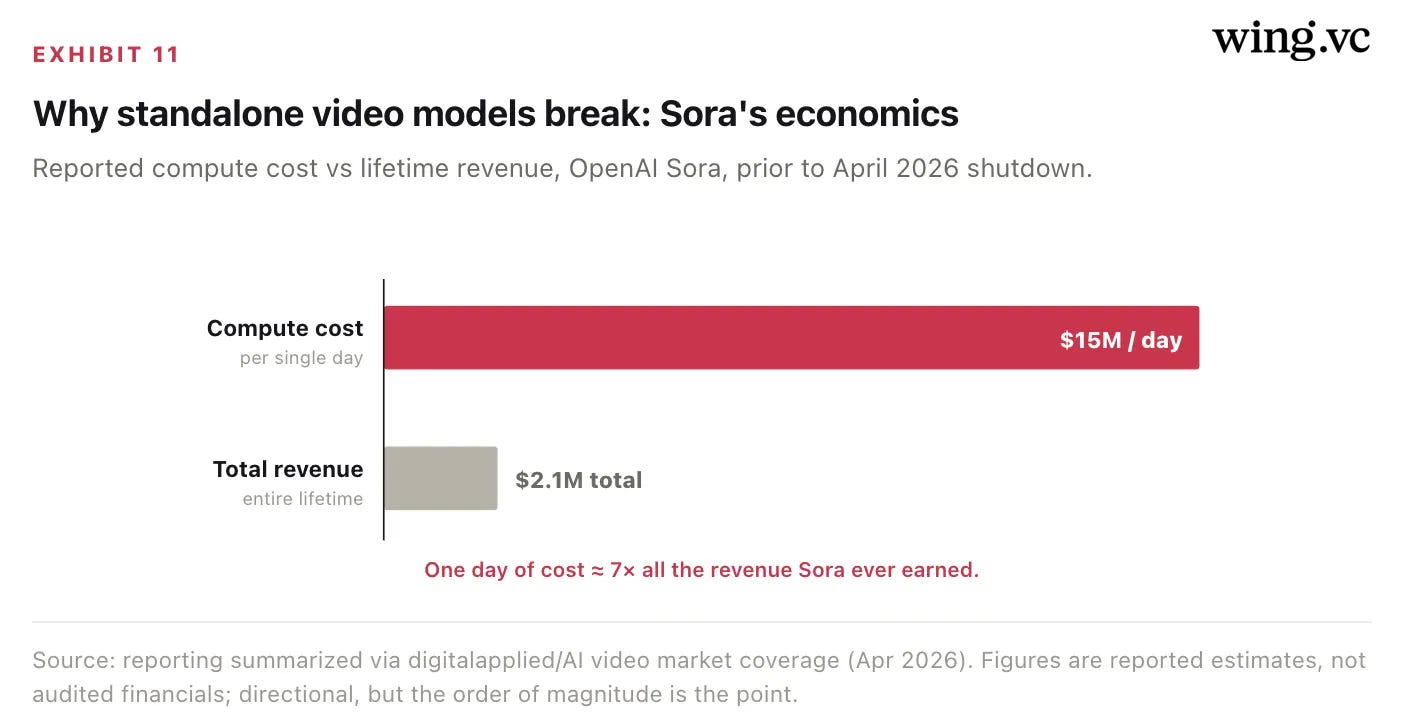
Why the economics favor ByteDance, not OpenAI
The clearest proof that media generation is an economics problem, not just a quality problem, is Sora’s collapse. OpenAI’s consumer video product reportedly burned ~$15M per day in compute against ~$2.1M in total lifetime revenue — a day of cost exceeding all the revenue it ever earned by roughly 7×. OpenAI deprecated Sora in April 2026. ByteDance runs the same workload at the same scale, but against a short-video advertising machine that already monetizes attention. Seedance is not a standalone P&L; it is a feature of Doubao, Jimeng (Dreamina), Volcano Engine Ark, and BytePlus.
That structural subsidy is why ByteDance can keep a video model at the frontier while a pure-play cannot. It also explains ByteDance’s monetization posture: keep the models proprietary, expose them through APIs and apps, and capture value at the consumer and cloud layers. Volcano Engine raised its model-as-a-service revenue target to ¥15B on the strength of Seedance demand, and Doubao’s reach gives every model instant distribution.
Implications: Where margin survives when the model layer is free
The strategic conclusion is not “China is winning AI.” It is narrower and more useful: the open model layer has been commoditized, and China supplies it. That repricing is permanent, and it relocates where value accrues. For an infrastructure investor, five implications follow.
1. Weights are a funnel, not a moat. Qwen’s billion downloads are a customer-acquisition expense for Alibaba Cloud, not a product. Any thesis that underwrites a standalone open-weight model business as the durable asset is mispriced. The defensible positions are distribution (ByteDance, Alibaba), cost structure (DeepSeek), release cadence (Moonshot), and the cloud/inference layer that monetizes all of them. Margin lives above and below the model, not in it.
2. The binding constraint is memory, and so is the policy lever. China can design competitive systems (CM384) and has adequate logic capacity (SMIC), but domestic HBM caps 2026 high-end output near 250k–300k packages. That makes HBM the single highest-leverage node in the entire stack — for Beijing’s industrial policy, for Washington’s controls, and for investors. Watch CXMT’s ramp, Samsung/SK Hynix’s China exposure, and any HBM-specific export action; those move the real frontier more than any model release.
3. Scarcity of training compute is exactly why efficient open models are strategic. When you cannot buy unlimited frontier silicon, a model that delivers near-frontier quality at a tenth of the inference cost is not just commercially attractive — it is a national hedge. The cheapness that looks like a race to the bottom is, from Beijing’s side, a way to extract maximum useful intelligence from constrained hardware. Expect more inference pushed onto small, efficient, open models and more domestic Ascend deployment despite its efficiency penalty.
4. In media, back the distribution, not the generator. Sora’s shutdown is the cleanest data point of the year: a frontier-quality video model with no attached business is uninvestable at current unit economics. The winners are models welded to a consumer or ad platform that can subsidize generation — ByteDance first, Kuaishou and Alibaba behind it. Standalone video pure-plays are structurally short of the cash flow needed to stay at the frontier; the durable plays are the platforms and the inference infrastructure underneath them.
5. The DeepSeek panic is the template: price the disruption to the right layer. The market’s January 2025 error was not believing China would disrupt — it was putting the disruption on silicon when it belonged on model-vendor share. Efficiency gains flowed down to compute (Nvidia at $5.14T) and up to distribution; they were competed away in the middle, where the open Chinese labs now sit. That is also the risk to the labs themselves: at a combined ~$160B, the pure-plays occupy the thinnest-margin layer in the stack, and their equity value depends entirely on converting free weights into something that isn’t free — Alibaba’s cloud pull, ByteDance’s consumer surface, Moonshot’s enterprise ARR. For a U.S. investor, the cleanest hedge against Chinese model-share gains is to own the compute and memory layers that every one of those tokens still runs on.
What to watch over the next 12–18 months
HBM: CXMT capacity beyond ~2M stacks; any HBM-specific U.S. control. The output ceiling moves with this number.
Offshore enforcement: whether the May 31 BIS parent-company rule is actually enforced against Singapore/Malaysia/Gulf neoclouds, or merely announced.
Frontier gap: whether DeepSeek/Kimi close the remaining quality gap to GPT-5.5 / Claude Opus on agentic tasks, or plateau just below it.
Monetization: Alibaba Cloud AI run-rate (past ~$5B) and ByteDance Volcano MaaS revenue (¥15B target) — the proof that open weights convert to cloud margin.
U.S. response: whether a credibly open, efficient U.S. model re-enters the Hugging Face top tier, or the open layer stays Chinese by default.
Summary
As of June 2026, China supplies the majority of the world’s open-model tokens, sets the price of intelligence at the open tier, and leads outright in video generation. It does this from a constrained compute base — competitive systems, capped memory, a just-closed offshore channel — which is precisely why efficiency and openness are central to its strategy rather than incidental to it. The U.S. frontier still defines the quality ceiling and captures most industry revenue, but it no longer controls the default. The contest has moved from “who builds the best model” to “who controls the layers that still carry margin”: memory and interconnect below the model, distribution and cloud above it. That is where the next five years of returns — and the next round of export policy — will be decided.
Sources
OpenRouter — State of AI: 100T-Token LLM Usage Study and LLM Rankings.
KuCoin / Global Times — OpenRouter: 61% of token consumption by Chinese models; Chinese models take top six usage spots.
digitalapplied — OpenRouter Rankings April 2026; Chinese AI Models Q2 2026 Landscape.
Hugging Face — State of Open Source, Spring 2026; One Year Since the DeepSeek Moment.
Pandaily — Qwen surpasses 1 billion downloads; getaibook — Chinese open models overtake U.S. on the Hub.
DeepSeek — API Pricing; verdent.ai — V4 Pricing & Migration (2026); sitepoint — DeepSeek V4 Released.
Moonshot AI — Kimi K2.6; miraflow — K2.6 ties GPT-5.5 on coding; DevOps.com — Kimi K2.7-Code.
SemiAnalysis — Huawei Ascend Production Ramp (HBM bottleneck); CloudMatrix 384; Tom’s Hardware — Ascend ecosystem scales.
Alibaba — FY2026 6-K; CIW — Alibaba Cloud Q1 2026. ByteDance capex — EqualOcean, SCMP.
Export controls / neoclouds — Tom’s Hardware — ByteDance 36k Blackwell via Malaysia; Asia Times — SE Asia data-center crackdown; Indoneo — BIS parent-company rule.
ByteDance video / Doubao — ByteDance Seed models; sitepoint — Seedance 2.0; kr-asia (Volcano MaaS target); Sacra — ByteDance overview. Video market — digitalapplied: AI video after Sora; Bloomberg.
DeepSeek panic / Nvidia — CNBC — Nvidia sheds ~$600B, biggest one-day loss; IG — why NVDA fell 17%; MacroTrends — NVDA market cap ($5.14T, Jun 2026).
Vendor share / Meta decline — stockalarm — OpenRouter rankings investor analysis (Chinese 46–56%); cryptobriefing — U.S. startups shifting to Chinese LLMs.
Valuations — TechCrunch — Moonshot $2B at $20B; SCMP — DeepSeek first raise; Bloomberg — ByteDance ~$480B; companiesmarketcap — Chinese company market caps.