

Databricks acquires Tabular for $1B+: What is Apache Iceberg?
Exploring Databricks' acquisition of Tabular and the role of Apache Iceberg in modern data lakehouse interoperability

Databricks has recently announced its acquisition of Tabular, a company specializing in open table formats in enterprise data architecture based off its Apache Iceberg. This acquisition enables Databricks to significantly enhance its data lakehouse platform by integrating advanced open table formats, offering users faster, more reliable, and scalable data platform. Integrating Tabular’s expertise and technology will enhance Databricks’ ability to manage large-scale data storage and analytics, particularly in optimizing AI workloads. This will enable more efficient data retrieval and processing, making it easier for AI models to access and analyze massive datasets, leading to faster and more accurate insights.

What is Apache Iceberg? Why is Iceberg Gaining Adoption?
Apache Iceberg is an open-source table format designed to handle large analytic datasets in data lakes and data warehouses. Iceberg addresses key challenges associated with big data, such as ensuring high performance, managing schema evolution, and enabling ACID transactions. One of the primary reasons for its growing adoption is its ability to efficiently manage petabyte-scale data, which is crucial for modern data processing needs, including AI workloads.
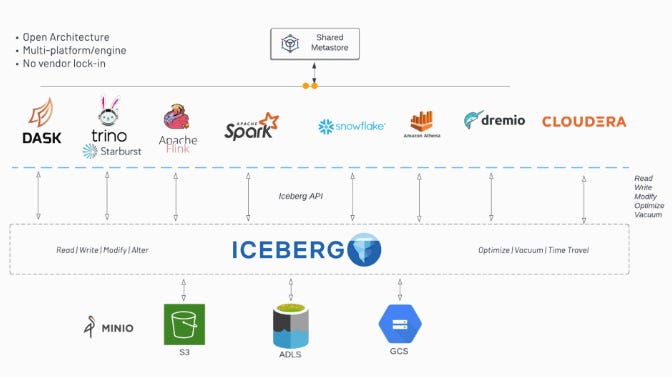
Iceberg supports features like time travel, which allows users to query historical data easily, and optimizes data layout to significantly improve read and write performance. This is particularly beneficial for AI use cases that require consistent and quick access to vast amounts of historical data for training models. Additionally, Iceberg integrates seamlessly with popular data processing and query engines such as Apache Spark, Apache Flink, Trino, and Presto, making it a versatile choice for organizations looking to streamline their data pipelines. These query engines leverage Iceberg’s capabilities to execute complex queries more efficiently and at a lower cost.


The format also enhances data reliability and consistency, which are critical for AI and machine learning applications. By providing a robust framework for managing large datasets, Apache Iceberg enables more efficient data retrieval and processing, leading to faster and more accurate AI model training and inference. As a result, it is becoming a preferred choice for organizations aiming to optimize their data lakes and improve data accessibility and analytics capabilities.
Tabular Overview
Tabular is the company specializing in commercializing Apache Iceberg and its open table formats. Founded by former Netflix data team Ryan Blue and Daniel Weeks, Tabular has quickly gained traction in the data infrastructure space. Apache Iceberg was originally created at Netflix to address the challenges of managing petabyte-scale datasets in their data lake. The engineering team at Netflix developed Iceberg to improve performance, support schema evolution, and enable more efficient querying and data processing. By open-sourcing Iceberg, Netflix aimed to provide a robust table format that could be widely adopted by the industry to tackle similar big data challenges. Tabular had raised a total of $37M from a16z, Zetta, Altimeter, and others.
Since, Apache Iceberg has received widespread adoption from leading companies such as Netflix, Apple, LinkedIn, and Adobe. Its open standards have been embraced by numerous data platforms, including Snowflake, Databricks, and Cloudera, demonstrating its effectiveness and versatility in the industry.

Strategic Importance of Iceberg to Databricks
The acquisition of Tabular by Databricks is a strategic move that enhances Databricks' data lakehouse capabilities and strengthens its competitive position. By bringing together the original creators of Apache Iceberg and those of Delta Lake, Databricks will be the owners of the two leading open source lakehouse formats. By bringing Iceberg and Delta Lake together, Databricks aims to eliminate limitations caused by format incompatibility, allowing users to work seamlessly across different lakehouse formats. While the future trajectory of Apache Iceberg remains to be determined, the integration of Tabular is a step towards more open data formats — “in the long term, by evolving toward a single, open and common standard of interoperability” (Databricks)

We will see other data platforms reactions to Databricks owning the two leading open table formats. Snowflake recently unveiled Polaris, an open catalog implementation for Apache Iceberg. Snowflake may choose to fork Iceberg to ensure its continuity as an open format in a democratic format.
Conclusion

Databricks' acquisition of Tabular, specializing in open table formats through Apache Iceberg, marks a significant enhancement to its data lakehouse platform. This move will enhance Databricks’ ability to manage large-scale data storage and analytics, particularly in optimizing AI workloads. The improved data retrieval and processing capabilities will make it easier for AI models to access and analyze massive datasets, leading to faster and more accurate insights. By consolidating the strengths of Apache Iceberg and Delta Lake, Databricks is positioning itself at the forefront of open data formats and the future of data architecture.