

Neoclouds and Why AI Compute Demand has Outgrown Hyperscaler Balance Sheets
Demand is compounding faster than any balance sheet — including trillion-dollar hyperscalers — can absorb

RPO backlog data reveals a market so demand-saturated that even Azure’s $625B in AI-era commitments (+1,150% over pre-AI baseline) is insufficient. Microsoft, the largest infrastructure spender in the world, has spent the past year scrambling for capacity through deals with CoreWeave, Crusoe, Nebius, and NScale. When the market leader grows backlog by 1,150% and still cannot self-supply, the structural implication is clear: no single provider can meet AI compute demand at current growth rates. Supply constraints, pricing dynamics, and the emergence of purpose-built AI cloud providers are redrawing the map in real time.
The severity of the supply-demand mismatch is visible not just in procurement data but in production reliability. Anthropic — among the most compute-intensive AI companies in the world — operates below 98% uptime, a figure that would be disqualifying for any enterprise software vendor. AWS S3 targets 99.99%; Salesforce and Workday routinely exceed 99.9%. Anthropic’s reliability ranks among the lowest of any major software service, not due to engineering failure but due to compute scarcity. It’s reported that much training resources in 2026 will be diverted to keep inference online, ultimately slowing model releases.
Despite concerns that further generations of Nvidia hardware would cause heavy depreciation on older models like H100s, prices have hardly come down and even become more scarce over time:
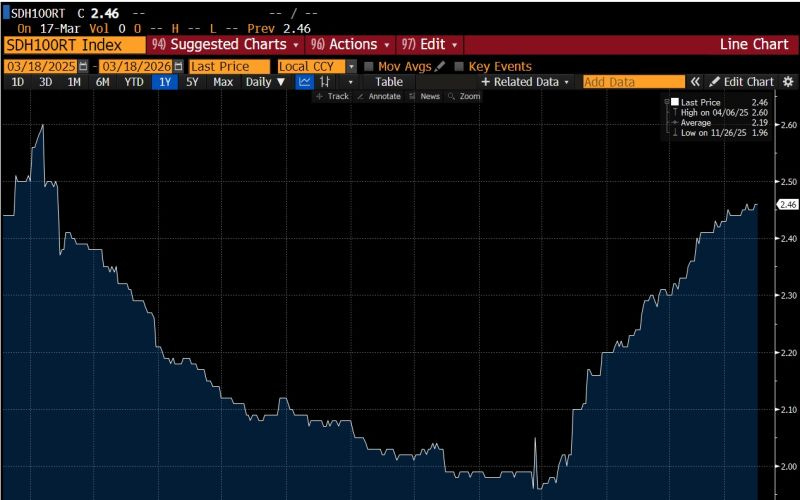
Frontier AI labs are diversifying their compute base. The most consequential shift is not a single provider’s growth — it is the pattern of AI labs actively decoupling from single-cloud dependency. OpenAI is diversifying away from exclusive Microsoft reliance toward OCI, which absorbed a material portion of its recent backlog growth. Anthropic is expanding beyond AWS and GCP into FluidStack, Crusoe, and Oracle. These are strategic decisions by the two largest AI labs to distribute infrastructure risk across providers. OCI’s backlog growth is real, but its concentration in OpenAI creates bilateral risk: OpenAI has extended itself aggressively across multiple infrastructure commitments and may restructure obligations if its own revenue trajectory compresses.
Even Microsoft cannot keep up. Azure’s $625B AI-era backlog represents +1,150% growth over its pre-AI baseline — and it is still not enough. Microsoft has spent the past year signing capacity deals with CoreWeave, Crusoe, Nebius, and NScale, sourcing a rapidly growing percentage of incremental compute from third parties. This is not a strategic pivot — it is a supply constraint forcing structural dependency.
The neoclouds are real, though still small. CoreWeave, Nebius, NScale, FluidStack, and Crusoe entered the table from zero, combining for $131B in new commitments — enterprise-scale, multi-year GPU reservations from customers and hyperscalers alike who cannot build fast enough to serve demand internally. In practice these remain small relative to the $100B+ investments made by hyperscalers. Today neoclouds represent 10–20% of capex in AI data centers; hyperscalers account for 80–90%.
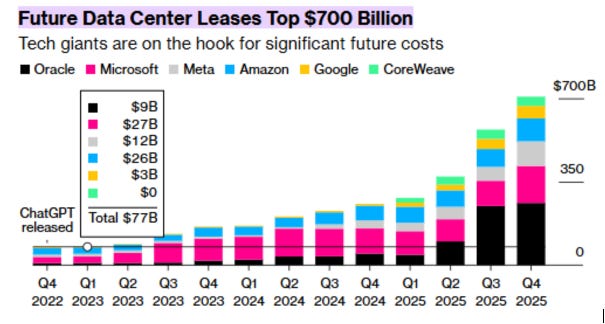
The Capital Ceiling
The four largest hyperscalers — Microsoft, AWS, Google, and Meta — are collectively committing approximately $700B in AI infrastructure capex in 2026, a figure that approaches or exceeds 100% of their operating free cash flow and creates negative overall free cash flow. Boards impose discipline; buybacks, dividends, and core business investment compete for the same capital.
The hyperscalers will not reduce capex programs, but they are unlikely to materially exceed the FCF ceiling on a sustained basis. The marginal dollar of new capacity will not come from Microsoft or AWS — it will come from neoclouds financed by private credit, infrastructure funds, and sovereign capital. They entered the commitments table from zero not because hyperscalers are retreating, but because hyperscalers cannot grow fast enough to serve demand at the margin.
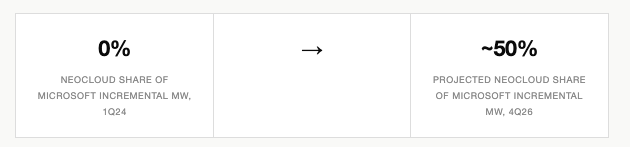
In less than three years, Microsoft transitions from a fully self-supplied infrastructure operator to one sourcing roughly half its incremental compute from third parties. For Microsoft, CoreWeave is not a partner — it is a crutch. For CoreWeave, Microsoft is not a customer — it is validation that the largest infrastructure spender in the world cannot meet its own demand.
Why This Is Structural, Not Cyclical
Compute-hours are produced by a chain of interdependent inputs. The binding constraints have migrated from silicon to physical infrastructure: power availability, high-voltage transmission, transformer manufacturing (lead times: 2–4 years for large units), cooling, and grid interconnection. Demand scales on 12-to-18-month cycles; electrical infrastructure scales on decade-long ones.
That mismatch is structural scarcity. When one constraint is relieved, pressure shifts to the next layer serially — GPU supply exposes the power bottleneck; power exposes transformer lead times. The result is geography-bound compute: AI infrastructure is forced into specific regions by power availability, land, water access, and regulatory environment. OCI and CoreWeave have been structurally more aggressive on power procurement than AWS and Azure at the margin, and the backlog data reflects it.
Networking follows the same pattern: copper interconnects are hitting limits at 10,000-plus GPU cluster scale, forcing a transition to co-packaged optics (CPO) that collapses a supplier tier and elevates a new set of component manufacturers into structurally critical positions.
Implications
Every hyperscaler is growing — and none are growing fast enough. These are extraordinary growth rates by any historical standard. Yet neocloud backlog emerged from zero in the same period. The demand signal is not that hyperscalers are failing; it is that AI compute demand is scaling faster than even trillion-dollar balance sheets can absorb. GCP’s +382% growth suggests Google is executing better on AI-native positioning than its installed base would imply.
OCI is the most important cloud story to watch — and possibly the most exposed to ROIC failure before any neocloud is. Oracle recently eliminated approximately 30,000 employees, inconsistent with scaling into a large build commitment. A reported Texas site failure raised delivery timeline questions. Most consequentially, Larry Ellison has reportedly pledged Oracle equity as collateral against personal debt tied to a significant media acquisition, creating forced-selling exposure and board independence risk at exactly the moment the company requires sustained capital discipline.
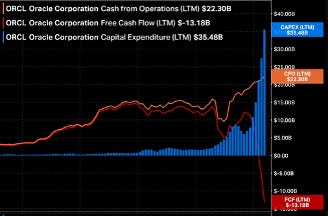
Oracle (ORCL) — LTM Cash from Operations: $22.3B / CAPEX: $35.5B / Free Cash Flow: -$13.2B. Source: Bloomberg
The conventional risk framing treats neoclouds as the fragile capital structures and hyperscalers as the durable ones. In OCI’s case, that framing may be inverted. A purpose-built neocloud with no founder pledge overhang, no legacy workforce to restructure, and no unrelated media liability may be a more reliable 5-year counterparty. OCI’s backlog growth is real; whether Oracle has the organizational and financial architecture to deliver it is an open question.
Neoclouds are the marginal capacity provider. CoreWeave’s $41B, Nebius’s $20B, and Crusoe’s $20B are the overflow valve for a market growing faster than any single balance sheet can absorb. The neocloud capital structure — private credit, infrastructure funds, sovereign capital — is purpose-built for exactly this role.
Regionalization is the next structural theme. AI infrastructure is geography-bound by power availability, data sovereignty, and national industrial policy. NScale ($14B valuation) is the primary neocloud partner for Microsoft and OpenAI in Europe. Neysa is executing the same playbook in India. The Middle East and Latin America are next — sovereign AI programs, abundant energy, and governments subsidizing local infrastructure to avoid permanent compute dependency on US providers. Expect regional neocloud champions in each geography, underwritten by hyperscaler offtake agreements and sovereign capital.
Risks
Risk 1 — Proprietary Silicon at Scale
The one credible path by which hyperscalers recapture internal workloads from neoclouds is success with custom ASICs. AWS (Trainium/Inferentia) and Google (TPUs) are the only hyperscalers with viable proprietary silicon in production today — but at relatively small scale relative to their total compute footprint. Microsoft, Oracle, and Meta have no viable ASIC. OpenAI is working with Broadcom on custom silicon but is at minimum three years from meaningful production. Meta’s response is instructive: rather than build internally, it has committed to AMD at scale — reportedly one of the largest GPU procurement agreements in the MI300X generation — wagering that a third-party accelerator can substitute for internal silicon. Until AWS and Google demonstrate ASIC scale that materially reduces neocloud dependency, the ASIC threat remains a 5-year risk, not a present one.
Risk 2 — Demand Deceleration
The one scenario in which neoclouds face existential pressure before hyperscalers do is a rapid cooling of frontier AI demand — a world in which model capability improvements plateau, enterprise adoption stalls, or capital markets withdraw from AI infrastructure financing. Neoclouds carry the most concentrated exposure: GPU lease obligations are fixed, cost structures are capital-intensive, and there is no diversified revenue base to absorb a demand shortfall. Hyperscalers, by contrast, can redirect capacity to general cloud workloads and absorb losses within broader P&Ls. A demand collapse would reprice neocloud equity and debt simultaneously, and several newer entrants — underwritten on aggressive utilization assumptions — would face covenant stress before a single hyperscaler earnings call reflected the problem.
The evidence does not support near-term cooling. Anthropic and OpenAI are not experiencing outages because they are poorly run — they are experiencing outages because demand is outrunning every unit of capacity they can procure. These are rationing events in a supply-constrained market. GPU depreciation curves have proven slower than prior hardware cycles; H100 utilization rates have remained elevated and secondary market pricing has held above what prior GPU generations sustained at equivalent ages. Until the outage pattern reverses, a demand deceleration severe enough to threaten neocloud economics remains a tail risk, not a base case.
I look forward to your articles! Insightful to read, easy to understand.