

The RAG Revolution: The Future of Computing
Covering RAG101 and discussing the implications up and down the stack of moving to retrieval plus generation-based computing

This is one of the great observations we made. We realized that deep learning and AI was not a chip problem; it’s a reinvention of computing problem. Everything from how the computer works, how the software works, the type of software it will write, the way we develop software today using AI and creating AI is fundamentally different from the way before. Every aspect of computing has changed.
The vast majority of computing today is a retrieval model, meaning when you touch your phone — some electrons go to a data center somewhere and retrieves a file, goes back to you. In the future, the vast majority of computing will be retrieval plus generation model. — Jensen Huang, CEO and Co-Founder of Nvidia

As Jensen alludes to, computing has historically architected around retrieval-based computing — searching an existing database or repository of information to find answers or resources that match a given query. Retrieval-augmented generation (RAG) [perhaps better thought of as Retrieval + Generation based computing] combines the concept of retrieval-based computing with generative models. While retrieval-based computing focuses solely on finding existing information from a database, RAG extends this by using the retrieved information as a foundation upon which generative models can build a richer answer — allowing for the creation of new, contextually relevant answers that are informed by the retrieved data. This synthesis creates more nuanced and informed outputs that can better adapt to complex queries or tasks.
History of RAG
The roots of the RAG technique date back to at least the early 1970s. Researchers were working on question-answering systems that use natural language processing (NLP) to initially access text in narrow topics such as soccer. While the concepts behind this type of text mining remained fairly constant over the years, the emergence of machine learning engines changed the usefulness and popularity of these techniques.
In the mid 1990s, the Ask Jeeves service (now Ask.com) popularized answering with its mascot of a suited up valet driver. Prior to Google, users asked questions to the information retriever and it performed similarity search on topics.

Similarly, in 2011 IBM’s Watson became a TV celebrity in 2011 when it beat two human champions in the Jeopardy! game show. Watson used information retrieval tooling in its AI system that was based on RAG. While LLMs and ChatGPT emerged much later, Watson was an early example of the promise of RAG in AI systems — fetching answers on the fly that made the system the first computer world champion.

What is RAG?
See RAG101 for Enterprise by Gradient.ai

RAG is the AI framework used to improve the quality of LLM generated outputs by connecting the model to external sources of data to supplement the data that the LLM was trained on. Simply put, RAG blends the best of both worlds from retrieval-based and generative systems. Instead of generating responses from solely the LLM, the retriever fetches relevant documents that contain domain specific context and uses this data to guide the response generation.
How does RAG work?
See RAG101 for Enterprise by Gradient.ai
The way the retrieval system works combines information retrieval with text generation.
Information Retrieval: Helps the model gain context by pulling in relevant information from a vector database.
Text Generation: Uses the added context to provide a more accurate and relevant responses.
To pull the most accurate context from a vector database to implement RAG, an embeddings model is used to generate vectors. Embeddings translate natural language elements—such as words, phrases, or entire documents—into vectors composed of real numbers, typically spanning hundreds or thousands of dimensions. This process converts textual information into a numerical format that captures various aspects of relevance, facilitating computational handling of language concepts.


Embeddings represent concepts and words with numbers that are geometrically similar. For example, an embeddings model may not understand that “cat” and “dog” are both pets, but it can determine that they have high semantic similarity and classify them together with other animals that are common pets. Embeddings (also referred to as vectors) are used to interpret queries with enough context to accurately pull relevant information from a vector database and retrieve the answer. The query is then used to match the relevant embeddings in the vector database based on similarity.
Setting up RAG
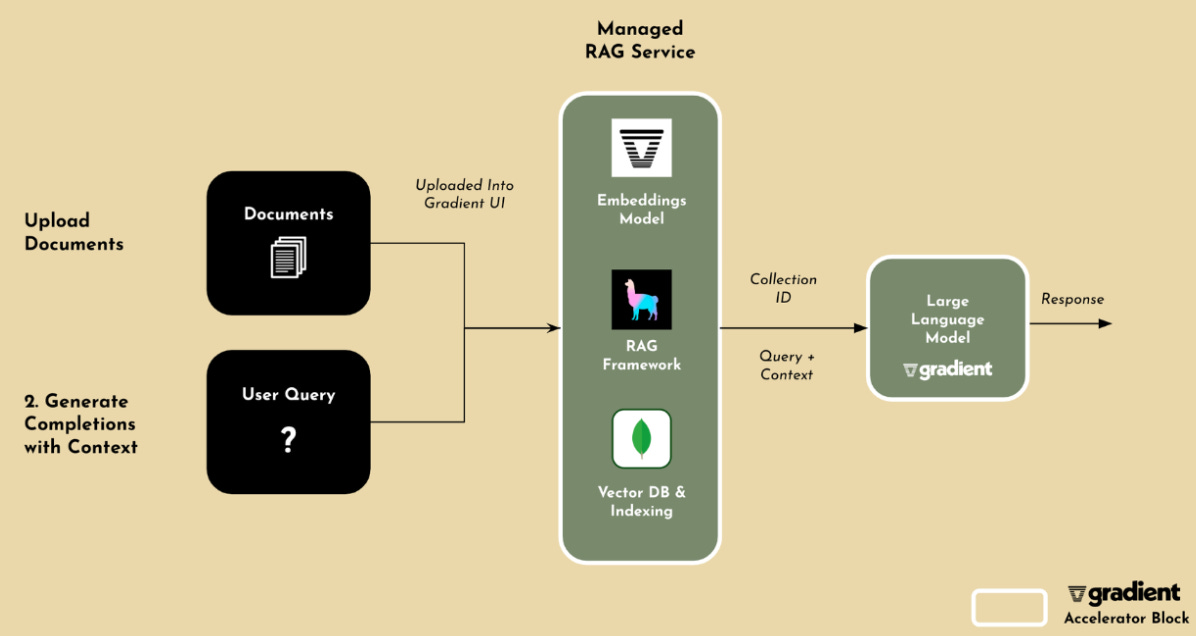
Identify your enterprise data sets — Depending on your use case of the LLM application, you will select your enterprise corpus of data. Many use LlamaIndex as a framework here. Common data sets include Salesforce, Zendesk, etc. customer support tickets for customer support bots, documentation and PRs for developer bots, and legal documents for legal apps.
Setup an Embeddings Model — Embeddings models turn your enterprise data into vectors to be leveraged by the LLM for similarity search. Voyage AI is a popular embeddings model provider that has topped benchmarks for performance, started by Tengyu Ma of Stanford. Hugging Face offers a host of open-source embeddings models. OpenAI also offers an embeddings model but it is quite pricey.
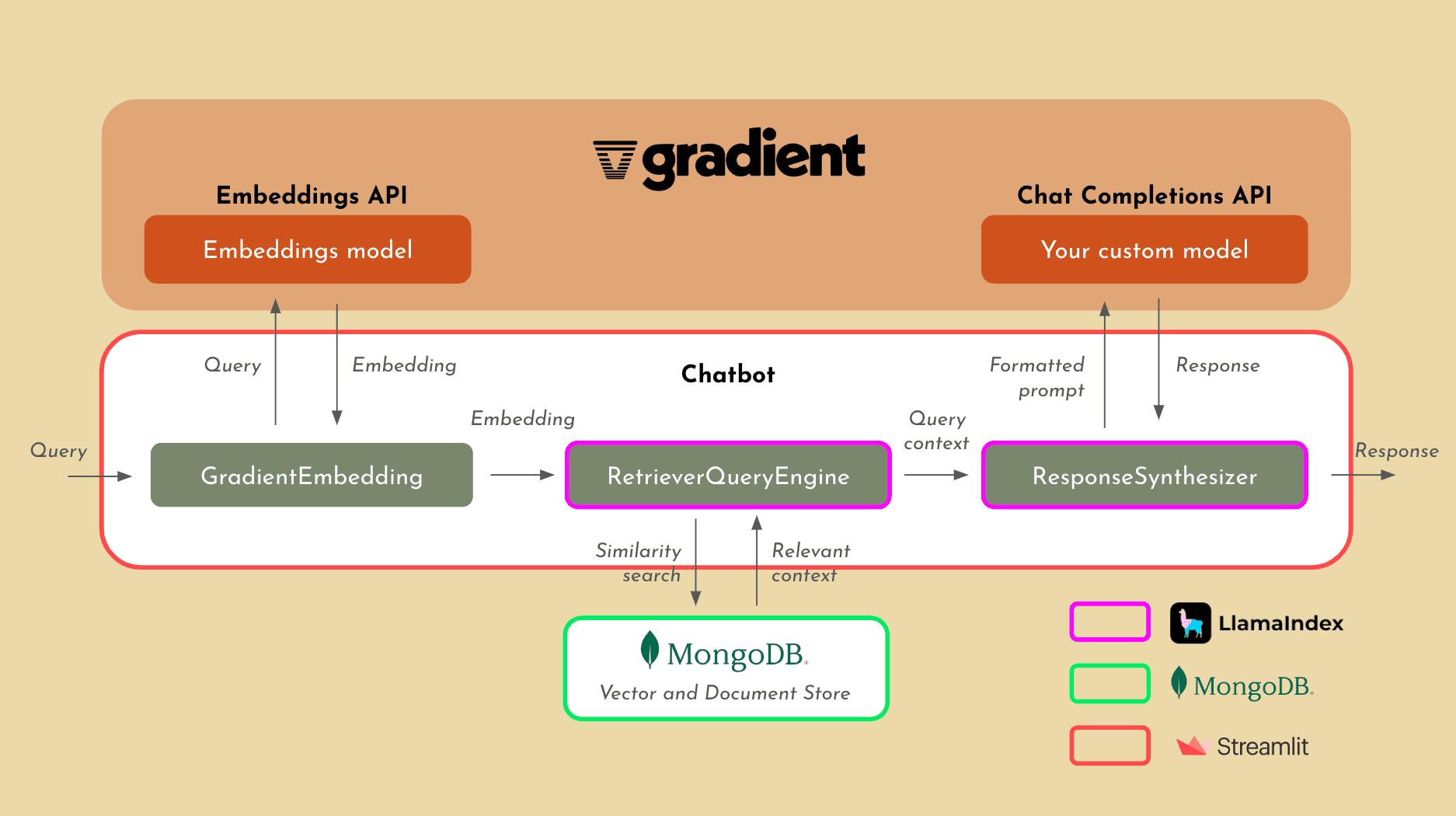
Store embeddings in a Vector Database — Store the embedded internal datasets of vectors in a vector database. The emergence of vectors as a the defacto data type for AI motivated Peter from Wing to lead the seed round into Pinecone in fall of 2020, far before the emergence of ChatGPT and LLMs. Pinecone has become by far the most popular vector database, though a slew of lighter weight open-source options exist. Gradient also works with MongoDB on their vector DB offering.

Pinecone developer documentation, https://www.pinecone.io/learn/retrieval-augmented-generation/
Input a user query — RAG inputs a user query from plain text as a statement that needs to be answered or completed.
Retrieval (RAG) —
Retrieval: With the user query, the retriever searches the vector database to find “chunks” of information that are semantically similar to the query. This relevance matching called similarity search is made possible by embeddings or vectors as a data type. The relevant chunks from text or documents are then used to provide additional context to the LLM.
Generation: The linked query and retrieved documents together are inputted into the LLM, essentially enriching the original query with relevant information. The retrieved text or documents are then linked with the original query. The output or response is given to the user.
“Users who are looking to build custom AI applications can leverage Gradient’s Accelerator Block for RAG to set up RAG in seconds. Users just have to upload their data into our UI and Gradient will take care of the rest. That way users can leverage all of the benefits of RAG, without having to write any code or worry about the setup.” — Tiffany Peng, VP Engineering Gradient
RAG addresses the data challenges of pretrained LLMs
While LLMs are trained with vast amounts of data, users have highlighted inaccurate answers and the issue of hallucinations — inaccurate or nonsensical responses. LLMs are “stuck at a moment in time” (when they are trained) and RAG brings them to the present. Simply put, RAG blends the best of both worlds from retrieval-based and generative systems. Instead of generating responses from scratch, RAG fetches relevant documents that contain domain specific context and uses this context to guide the response generation. In some ways, RAG is a bit like research and finding the right data sources before sharing an output.
Challenges of RAG
RAG is an exceptional way to improve the quality of LLM outputs, but it can introduce substantial complexity by increasing the surface area and infrastructure developers have to maintain in building an AI application. RAG requires:
A technical team with knowledge of AI in both coding and architecture
Proper software infrastructure (a vector database, an embeddings model, data frameworks, and data infrastructure)
Financial resources
Research and planning
Time to develop the solution
Compliance and security, especially around data
Gradient recently launched Accelerator Blocks for RAG, creating a library of building blocks for AI use cases. This streamlines configuration, planning and components for AI applications by integrating best-of-breed tooling from vector databases to embeddings models and data infrastructure in one.

Further Improving RAG-based AI applications
If you are looking for further ways to improve your RAG tooling for AI applications, here are some strategies to consider from Gradient:


Gradient connects to your data sources to host all your AI models in one place, streamlining all the infrastructure around your data. Simply bring your vector database full of your enterprise data and you are ready to RAG:

In addition to speed and time-to-market, other benefits of a managed RAG offering are:
Host models in one place
Keep your data in your private environment and maintain full ownership over your AI models around SOC2, HIPAA, GDPR compliance
Reduce AI development costs
Use developer friendly tools and APIs
Maintain access to the latest tooling around LLMs
Beyond RAG: Other approaches to LLM optimization
When developing AI applications, remember it's often more effective to deploy several smaller models rather than a single, large model to meet all your needs. This approach typically delivers better performance and efficiency while also minimizing costs. Some key questions to consider:
Will the amount of knowledge in a pre-trained model suffice or will I need new information sources after training?
Is my use cases a standardized task or is it domain/company specific task?
Do I have unlimited training data or do I need to provide examples?
Does the task require context outside a foundation model such as new information?
Platforms like Gradient support multiple approaches to improving model outputs, such as RAG, fine-tuning and prompt engineering.

Integrating RAG with fine-tuning significantly boosts the effectiveness and dependability of LLMs. RAG equips LLMs with the capability to pull information from external databases, enabling them to use the context for in-context learning, which amplifies the model's intrinsic training. However, if a pre-trained LLM falls short in tasks like document summarization (such as for medical or financial reports), simply adding more documents for context might not rectify the problem. In such instances, fine-tuning becomes essential, as it tailors the model to excel in specific tasks by teaching it the required skills. While either method alone might occasionally suffice, combining contextual understanding through RAG with the precision of fine-tuning generally yields superior results, crafting responses that are both relevant and accurate.
RAG as the future of computing
RAG represents the future of computing by blending the strengths of retrieval systems with advanced generative capabilities, enabling machines to produce contextually rich and informed responses. In many ways, think of RAG as Retrieval + Augmentation. In a post-retrieval era, RAG's ability to dynamically leverage external knowledge bases for real-time information synthesis offers a transformative leap in how AI systems understand, interpret, and generate content. This fusion not only enhances the relevance and accuracy of outputs but also paves the way for more adaptive, intelligent, and efficient computing solutions.
 uses semantic search to retrieve relevant context")
Source: Pinecone Developer Documentation, https://www.pinecone.io/learn/retrieval-augmented-generation/
The critical nature of RAG in information retrieval across all software applications represents a massive opportunity in computing for those powering these AI computations. From vector databases and LLMs to the hardware vendors like Nvidia and AMD powering AI inference workloads, computing demands are a step function higher than retrieval-based system.