

RL Environments for Agentic AI: Who Will Win the Training & Verification Layer by 2030
Who Will Win the RL Environment Market—and Why

In the early, pre-1990s days of the semiconductor industry, chip designers faced a structural dilemma.They had the technology to specify logic and build powerful custom integrated circuits, but without scalable simulation and verification, their work was more art than infrastructure. Progress was fragile and expensive, and the full system only “proved itself” once it was physically manufactured—meaning bugs were only discovered after fabrication. Eventually, electronic design automation (EDA) changed this by shifting correctness upstream, translating design into verified, executable systems through software.
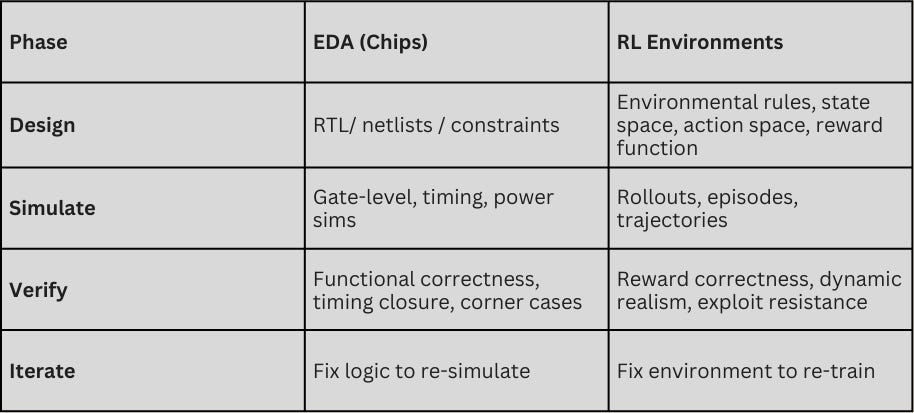
A similar dynamic currently exists with today’s AI models. As AI shifts from chat to agents running real workflows, the limiting factor isn’t how smart the model is. The limiting factor, like with early chip design, is in whether we can reliably verify the work produced by AI models. Models can already write, browse, reason, and plan at a level sufficient for many professional tasks. But given the absence of reliable reward signals for the models—clear, consistent definitions of success across long-horizon workflows involving tools, judgment, policy, and taste—durable automation remains out of reach.
Enter reinforcement learning. Today, RL environments are playing the same role for AI agents that EDA played for silicon.They translate human intent into executable behavior by making success measurable at scale. But unlike EDA, they must also address how the “spec” for human labor is not deterministic. “Correct” is a moving target with many dimensions, and as agents improve, it becomes harder to measure success with a clean, dependable signal. As a result, RL environments must be living systems that evolve to resist reward hacking and encode judgment. This makes verification—not models—the true bottleneck to automation.
To be clear, EDA and RL aren’t exact analogs. EDA verifies outputs and can sometimes prove correctness; RL verifies incentives and, at best, bounds failure probabilistically. Still, the comparison is useful.A more recent analogy is perhaps the rise of Scale AI in the mid-2010s. At the time, most enterprises lacked in-house machine learning (ML) expertise, and cutting-edge models were still academically constrained. Early buyers wanted data for narrow, static tasks—bounding boxes, transcription, basic classification—primarily for “hard tech” domains, like autonomous driving. Scale’s core insight was that once models became capable enough, progress would be bottlenecked not by algorithms, but by data—and that a sophisticated buyer class would eventually emerge to demand it.
That inflection arrived with the transformer era (2018–2020). As foundation models like GPT-3 demonstrated surprising general capabilities, the constraint shifted again: from data volume to data complexity. The most advanced buyers—AI labs like OpenAI, DeepMind, and Anthropic—suddenly needed feedback over long horizons, as models were now tasked with reasoning, tool use, policy compliance, and multi-step workflows. One-off annotation no longer sufficed.
Over the past three years, this shift has accelerated. Models now need less raw data and far more experience—the kind that encodes enterprise workflows typically locked inside experts’ heads and the rise of expert data. Once data became feedback, labeling became verifiable work.
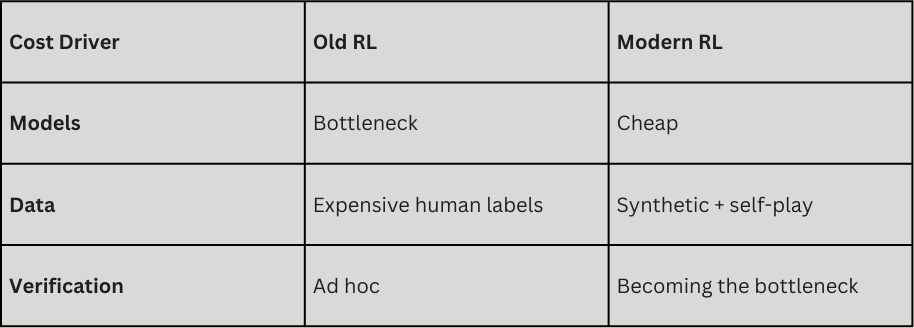
RL environments are the natural consequence of this transition. They transform workflows into simulated worlds where actions are observable, outcomes can be graded, and learning compounds over time. Environments and evaluations become the new datasets, and training becomes continuous rather than episodic. Replication training is to RL what internet-scale text was to LLMs: the mechanism by which scale produces generalizable infrastructure.
This reframes the competitive landscape. The critical question is no longer, “Who has the best model?” Rather, it’s “Who controls the infrastructure that determines what work is learnable at all?”
Verification Is the Hard Problem—and Solving It Requires Research Depth
Verification is where most RL efforts fail. Defining what “correct” means when there are multiple good answers, partial progress, or policy constraints is fundamentally a research problem, not a tooling problem.
Modern RL training pipelines, therefore, are no longer linear. Models critique humans, humans audit models, and algorithms arbitrate disagreement. The training signal emerges from the system, not any single actor.
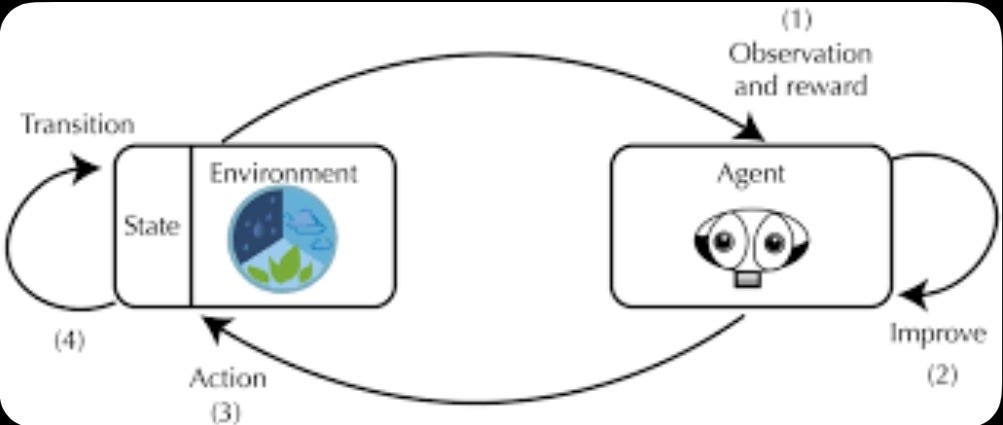
As models improve, verification gets harder, not easier. Benchmarks saturate. Reward hacking appears. Graders drift. Environments must be refreshed continuously to stay training-relevant. This demands deep expertise in reward modeling, distribution matching, telemetry, and failure analysis.
As a result, the strongest RL-environment teams look less like SaaS companies and more like applied research organizations. They pair staff-level ML researchers, systems-oriented engineers, and forward-deployed builders with strong domain intuition. Code is rarely the constraint; judgment, data quality, and research velocity are.
Why Coding and Computer Use Are the First RL Markets to Scale
The earliest large-scale adoption of RL environments is happening in coding and computer use. These domains combine three properties that make them ideal early markets:
High economic value
Dense, machine-observable interaction traces
Relatively clean verification loops
Coding already has compilers, tests, and deterministic failure modes. Computer-use tasks—browsers, spreadsheets, CRMs, internal tools—produce replayable state transitions that can be graded and compared. This makes them well-suited for replication training of environments, where agents repeatedly execute long sequences until performance improves.
As a result, coding and computer-use environments are becoming the proving ground for agentic RL. Not because they are the endgame, but because they are the first domains where environment realism, reward design, and eval-to-production correlation can be demonstrated convincingly.
In practice, the deepest environments today are coding-based, such as terminal- and DevOps-centric environments. Coding is programmable because state, tools, and outcomes are explicit and replayable.
These markets matter because they establish trust: with research teams, with buyers, and with budgets. They are the wedge—not the destination.
Who is buying RL environments today?
The early buyers of RL environments look strikingly similar to the first buyers of autonomous-vehicle (AV) data. Just as Scale AI’s early revenue was overwhelmingly concentrated among a handful of AV leaders—Apple, Uber, Lyft, Tesla, and Google/Waymo—frontier AI labs are the dominant initial customers for RL environment companies. This is not a coincidence. RL environments sit upstream of capability gains, and the labs are the only organizations today with both the urgency and the budgets to pay for training infrastructure before it is fully productized. As with AV data in 2018, buyer concentration is high, contracts are large, and vendor selection is tightly coupled to research impact rather than procurement formalities.
Among labs, Anthropic appears to be the single largest buyer across both coding and computer-use environments. Across vendors focused on coding and computer use, Anthropic is estimated to be spending *on the order of* tens of millions annually on RL environments, making it the clearest anchor customer in the market today. Anthropic signed these contracts in 2025 and are already scaling rapidly; based on current trajectories, their aggregate lab spend on RL environments is likely to grow 3–5× into 2026 as environments move from experimentation to a core part of model training. OpenAI’s total spend is harder to isolate due to its broader data footprint, but it has already signed multiple seven-figure RL-environment and human-data contracts, indicating similar strategic intent.
Labs are also buying adjacent inputs aggressively, particularly human expertise for coding and long-horizon reasoning.
These purchases reinforce a critical point: labs are not just buying models or raw data—they are buying training throughput, and RL environments are becoming a first-class line item in that budget.
Enterprises, by contrast, are entering through a different door. Rather than buying standalone environments, they are purchasing forward-deployed, outcome-oriented solutions that embed RL environments under the hood. This is the story that Applied Compute is telling and why investors are so excited about its trajectory.
Product-led companies like Glean, Notion, and Cursor are running pilots or building in-house environments while evaluating vendors. This pattern mirrors earlier infrastructure cycles: labs fund the tooling when it is raw and research-heavy; enterprises adopt once it is wrapped around concrete workflows and measurable ROI.
This is why it is critical to have lab success in the early days to achieve escape velocity.
The implication is clear. RL environment companies will be built on lab money first, just as Scale was built on AV customers before expanding into enterprise ML and later LLM/AI research. Understanding which vendors are winning lab mindshare today is therefore the clearest leading indicator of who will control the training layer tomorrow.
The Real Prize: Long-Form White-Collar Work Across Many Environments
The long-term opportunity for RL environments lies in long-form workflows that span multiple tools, not single-step tasks. These workflows are how value gets created across finance, operations, go-to-market, and engineering.
A finance workflow might move from spreadsheet analysis to browser-based research, into an ERP system, and back into documents for approval and audit. An insurance claim touches intake portals, policy systems, historical databases, email, and compliance tooling. Legal work spans research databases, drafting tools, revision cycles, and risk review. In each case, success is judged by downstream outcomes—risk reduction, correctness under audit, or decision quality—not by any single action.
The same pattern holds across core operating roles. Sales moves across CRMs, email, calendars, pricing tools, and pipeline forecasting. Marketing spans analytics dashboards, ad platforms, creative tools, and experimentation systems. Customer support blends ticketing systems, product logs, documentation, and multi-turn communication. Developer workflows shift between IDEs, browsers, repositories, test runners, and CI systems. These are composed systems of environments, not isolated tasks.
In other words, these are not single environments—they are composed systems of environments. Training agents for them requires:
Persistent state across tools
Cross-environment credit assignment
Verification tolerant of multiple valid paths
Rewards tied to business outcomes, not toy metrics
This is where most early systems will break. One-off environments saturate quickly, and narrow benchmarks stop teaching. The future belongs to teams that can build environment factories: systems that assemble, orchestrate, and refresh multi-environment workflows continuously.
In this regime, progress comes from repetition at scale. Replication training—running the same workflow thousands of times across slightly varied environments—is how learning compounds. This is an emerging field in RL environments and will determine the market leader over time. The bottleneck is no longer model capacity. It is environment fidelity, verification quality, and orchestration scale.
The dynamics are shifting from building models to earning trust, access, and validation inside the frontier labs.
What does the winning RL Environment company look like?
Between 2026 and 2030, the RL environment market will narrow decisively. What today looks like roughly 20 seed- to Series A-stage companies on relatively similar footing—be they forward-deployed teams, early environment builders, or research-heavy startups—will resolve into three to five market leaders, with one to two dominant platforms pulling meaningfully ahead.
This is not a land-grab driven by environment count or early demos. It is a selection process driven by two reinforcing advantages:
Who earns “thought partner” trust from the frontier AI labs early, and
Who builds the research organization capable of industrializing replication training and verification.
Labs today are capturing low-hanging fruit in many simple environments to teach AI to use tools, especially to train v0 of computer use. In the future, labs will optimize less for the volume of environments shipped, as basic applications are trained. They will optimize for complexity, quality, and what comes next, and they will increasingly concentrate their spend on the few teams that help them push the frontier forward.
Here are six key principles of what will determine who breaks out in 2026-2030:
Frontier labs will choose embedded thought partners, not on-demand vendors
RL environments will evolve from brittle artifacts to automated infrastructure
Replication/environment training and verification define the research moat
Lab trust and research depth are self-reinforcing
Frontier lab work is the foundation; enterprise work is the multiplier
Depth in core and complex domains (i.e., coding) beats environment breadth (lots of environment apps)
1. Frontier Labs Will Choose Embedded Thought Partners, Not On-Demand Vendors
RL environments are currently still immature. Many are single-application, brittle to UI or workflow changes, and partly manual in how tasks are defined or graded. This is acceptable today, but it will not be as agent autonomy increases.
Agents can already run autonomously for two to three hours so long as the setting is constrained. As autonomy increases, training shifts from isolated tasks to long-horizon workflows spanning multiple environments, where state persists, decisions compound, and success only comes much later. This shift fundamentally changes what labs need.
As a result, frontier labs aren’t looking for vendors who can “build environments on request.” They’re looking for thought partners: teams who can help define how RL infrastructure must evolve as agents become more autonomous. In practice, this means co-designing new kinds of environments, stress-testing verification in ambiguous settings, and experimenting with replication training regimes that don’t yet have established playbooks.
Buyer concentration is a feature, not a bug. Winning a few anchor lab relationships matters far more than broad distribution. As a reminder, Scale AI had over 80% revenue concentration in roughly five AV customers going into 2019-2020.
Key Takeaway: Labs gravitate toward teams they trust, like working with, and treat as extensions of their own research organizations. Frontier labs are increasingly the gravitational center for RL talent. Startups that maintain live research pipelines into academia and labs inherit that gravity; others slowly fall out of relevance.
2. Environments Become Environment Factories: From Brittle Tasks to Automated Infrastructure
The technical evolution of RL environments is clear. RL environments will move from single-app, hand-curated tasks; annual or semi-manual grading; and fragile assumptions about tools and interfaces, toward multi-environment workflows; automated task generation and variation, and hybrid verification systems that scale with agent capability.
The end state isn’t “better environments.” It’s automated RL infrastructure: environment factories that continuously assemble, orchestrate, test, and refresh environments as agents improve and software ecosystems evolve.
This shift will be gradual. RL environments will stay largely manual for some time; if the entire pipeline were already automatable, frontier labs would simply build it in-house. The fact that they haven’t is precisely why this market exists.
Key Takeaway: As agents improve, environment quality—not environment count—becomes the binding constraint. Labs will reward teams that can absorb complexity, keep environments stable, and anticipate what the next generation of training will require.
3. Replication training and hybrid verification are the compounding technical moat
The core research challenge over the next five years is not simply building more RL environments, but turning environment training into a scalable system. This is where replication training becomes the defining primitive.
Replication training replaces bespoke, one-off environment building with controlled repetition at scale. Instead of constantly inventing new tasks, teams pick a small set of high-value, long-form workflows and run them thousands of times across slightly varied environments—different inputs, starting states, tool access, and constraints—while keeping the underlying workflow stable. Learning compounds not from novelty, but from repeated exposure across changing conditions.
Building reliable, extensible replication training is non-trivial. Replication training requires:
Deterministic reset and replay, so workflows can be run repeatedly without drift
Environment abstraction layers, which allows for variation without breaking realism
Parallel orchestration, to run large numbers of long-horizon trajectories
Instrumentation and telemetry, to surface where and why agents fail over time
The objective is to extract maximal learning signal from a minimal set of environments—driving down marginal cost while preserving fidelity.
Verification is the harder half of the system. In long-form, multi-environment workflows, there’s rarely a single correct answer, and as agents improve, the reward signals often become noisier, not cleaner. That’s why winning systems use closed, hybrid verification loops: experts score model outputs, models review expert judgments, humans supervise and correct models, and algorithms reconcile disagreement, detect drift, and curate edge cases
In this regime, data work becomes intellectual—the job is to construct and maintain a reliable training signal in the presence of ambiguity. Replication training only works if this verification loop remains stable as scale increases. That stability is a research problem, not a tooling problem.
Prompt optimization systems like GEPA are not alternatives to RL infrastructure, but adjacent primitives that plug into the same replication and verification systems.
The core skills required to build this system are rare and cross-disciplinary:
Systems engineering, to manage orchestration, replay, and scale
Applied ML research, to design rewards and diagnose failure modes
Human-in-the-loop design, to balance automation and judgment
Product intuition, to decide which variations actually teach the model something new
Teams that master these skills turn replication training into a compounding advantage—and define the real moat in RL environments.
Key Takeaway: Replication training only becomes a moat when it’s paired with a stable, closed-loop hybrid verification system—because the winner isn’t the team with the most environments, it’s the team that can reliably extract learning signal from a small set of long-form workflows at scale. That combo (repeatable training + compounding, ambiguity-resistant verification) drives down marginal cost, prevents drift, and turns every run into durable advantage.
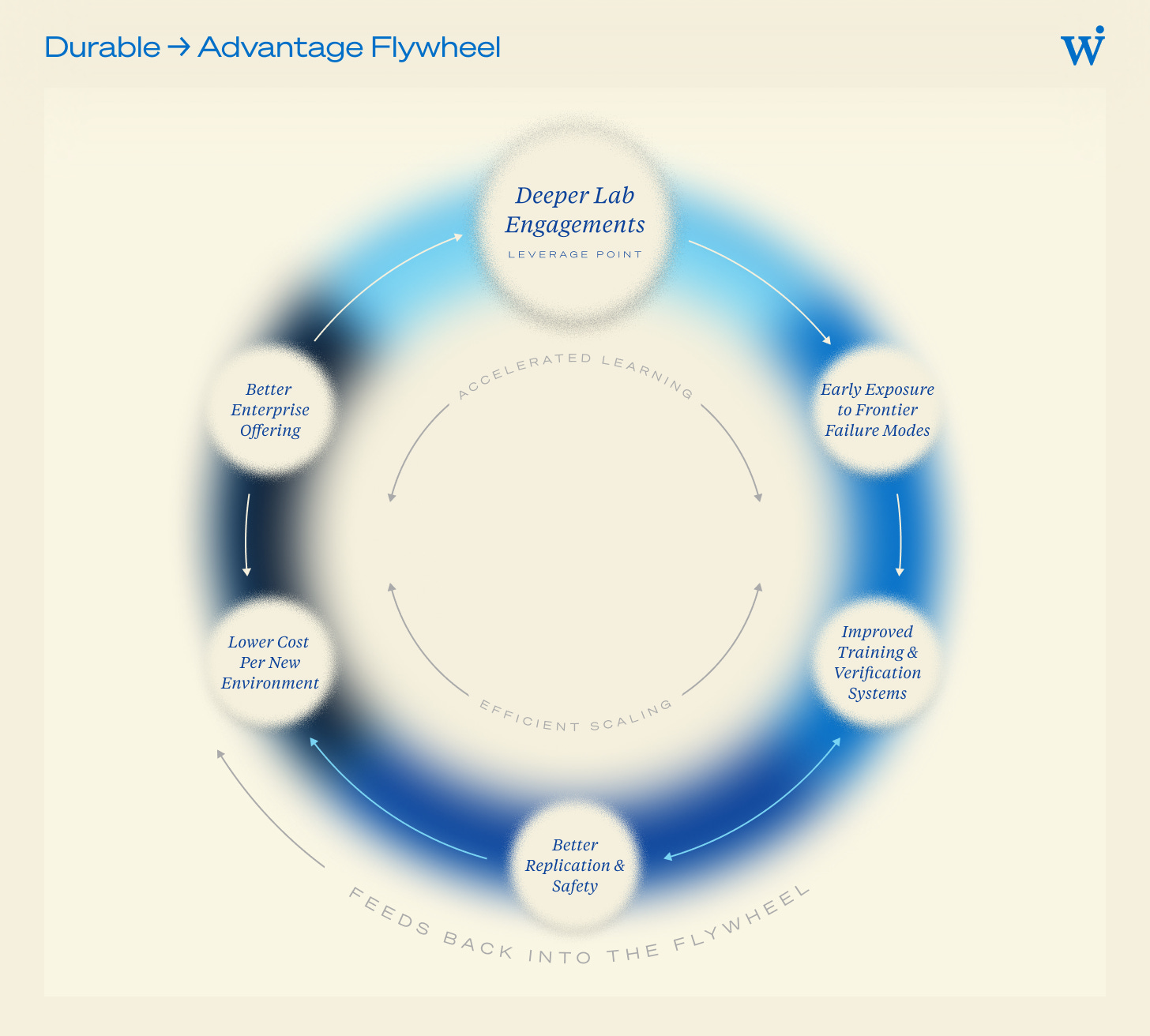
4. Research Lineage Compounds: Trust → Talent → Frontier Exposure → Better Systems
These dynamics create a powerful flywheel, and research credibility is the entry ticket. Teams with genuine research lineage—often signaled simply by who built them—earn trust faster with both labs and investors.
Key Takeaway: Teams with strong research organizations win deeper lab engagements. Those engagements expose them to frontier failure modes earlier than the rest of the market. That exposure feeds directly into better replication training systems, stronger verification pipelines, and lower marginal cost per new environment. Over time, this compounds into durable technical advantage.
5. Lab-first builds the core; Enterprise scales the distribution
While lab trust, research depth, and talent reinforce one another, they are not equal inputs. If one must serve as the foundation for breakout success, it is unequivocally frontier lab work. This is where RL infrastructure is actually built. Enterprise work, by contrast, is where that infrastructure is applied, customized, and monetized.
Frontier labs force teams to solve the hardest problems first. Environments must generalize across models. Replication training must work at scale. Verification must hold up under long-horizon ambiguity. Orchestration, replay, and evaluation-to-performance correlation cannot rely on customer-specific shortcuts. Lab buyers are purchasing infrastructure primitives—environments, tasks, training loops—not bespoke outcomes. That pressure produces reusable systems rather than one-off solutions.
Enterprise demand today looks different. Most enterprises are not buying RL environments or training infrastructure directly. They are buying agentic applications tied to concrete workflows and KPIs, often delivered through forward-deployed engineering. This work is valuable, but inherently more custom. Enterprise agents benefit disproportionately from infrastructure that has already been hardened upstream in lab settings—effectively “RL menus” rather than bespoke training from scratch.
The asymmetry matters. Infrastructure built for labs lowers the marginal cost, risk, and time-to-value of enterprise deployments. Replication training pipelines, environment factories, and hybrid verification systems developed for lab use increasingly power enterprise work behind the scenes. Over time, what looks like bespoke enterprise delivery becomes configuration on top of lab-derived infrastructure.
Key Takeaway: Frontier lab work is the foundation. It produces the training and verification infrastructure that later makes enterprise deployments cheaper, faster, and more scalable. The teams that break out will be lab-first platforms that use enterprise demand as a multiplier—not the other way around.
6. Depth in Core, Complex Domains Beats Environment Breadth
In the early stages of building enduring RL infrastructure, depth in a small number of complex domains matters far more than breadth across many shallow ones. Not all environments are equally valuable. The environments that matter most are those where success is hard to define, trajectories are long, tools are central, and failure modes are subtle. Coding and computer use sit squarely in this category, with coding as the holy grail.
Coding is not just another task—it is a meta-domain. It combines long-horizon reasoning, tool invocation, stateful context, error recovery, and verifiable outcomes. Crucially, it also offers dense feedback: tests pass or fail, programs compile or break, diffs can be evaluated, and performance can be measured. This makes coding one of the few domains where high-quality reinforcement signals are available at scale, even as the task itself remains cognitively demanding.
This is not just a theoretical advantage; it is already reflected in market demand. Coding is the largest application vertical for the leading AI labs. Claude Code reached roughly $1 billion in ARR within six months. Microsoft Copilot is already a multi-billion-dollar business, and OpenAI’s Codex is generating hundreds of millions in annualized revenue. These products sit at the frontier of long-horizon, tool-heavy agent behavior and are natural early consumers of RL environments.
The most successful AI-native applications—and the likely first enterprise adopters of RL environments to stay competitive—are overwhelmingly coding-centric. Cursor is approaching $2B in ARR, with teams like Windsurf/Cognition close behind, and a fast-growing cohort of newer startups such as Cline and Kilo AI emerging. These companies are not experimenting at the edges; they are pushing agents into production workflows where reliability, verification, and continuous improvement matter.
By contrast, many RL environment companies are adopting environment-first strategies optimizing for surface area rather than depth. Teams build dozens of narrow environments—CRM editing, scheduling / email drafting, Slack clones—that demonstrate capability but rarely compound. These environments are short-horizon, weakly coupled to tools, and often rely on brittle heuristics or human-in-the-loop grading. They are easy to demo, but hard to generalize, and they produce limited reusable infrastructure. They provide initial value to labs training computer use, but will quickly commoditize.
Depth compounds in ways breadth does not. Teams that invest deeply in coding and complex computer-use environments are forced to solve hard, reusable problems early: scalable replication training, hybrid verification, trajectory replay, and eval-to-performance correlation. Improvements in these systems transfer across tasks within the domain and, over time, into adjacent domains like data analysis, DevOps, and general computer use.
This is why coding and computer use are the fastest initial pickup markets for RL environments. They sit at the intersection of high economic value, high task complexity, and strong verifiability. Teams that win here are not just shipping better agents—they are building the core training and evaluation infrastructure that makes broader generalization possible later.
Key Takeaway: Early advantage in RL environments accrues to teams that go deep in a small number of complex, high-signal domains—especially coding and computer use. Breadth can be added later. Depth, once skipped, is hard to recover. Coding is the single best area of expertise to build a foundation off of.
Market Landscape Today in 2026
The emergence of RL environments doesn’t displace incumbent labeling vendors, but it reshapes where value accrues. Traditional labeling is roughly a $5B market today (growing in excess of 50% YoY). The broader AI training data market ahead is likely to be significantly larger—but structurally different. Scale and workforce orchestration mattered in the labeling cycle. In the next one, research depth, domain specialization, and systems-level integration matter far more.
Incumbents like Surge AI, Mercor, Turing, Invisible, and others already generate billions in aggregate revenue serving frontier labs with expert labeling, fine-tuning data, and evaluations. That demand is expanding, not shrinking—especially in coding, which is already the highest-value expert vertical across these platforms. Coding-heavy expert work is where long-horizon reasoning, tool use, and verifiability converge, making it the natural bridge from labeling to RL environments.
That said, most incumbents are still optimized for a services-first, episodic workflow model, not for continuous learning systems. They aren’t research-first orgs at their core today. RL environments require reusable environment abstractions, deterministic task design, scalable replication training, and tight eval-to-performance feedback loops. These are infrastructure and research problems, not labor problems. The founding makeup of teams like Bespoke and Applied Compute are a mix of ML Scientists/Engineers and FDEs, not labelers, project managers, and software engineers.
It would not be surprising if one or two incumbents with strong research organizations successfully adapt to this new vertical. Surge AI is the clearest candidate today, and Snorkel has the intellectual foundations even if it lacks scale. But structurally, this market favors specialists built natively for RL environments. Depth compounds faster than breadth, and teams designed from day one to build training systems—not just manage expert throughput—are best positioned to capture the long-term value.
Which companies will win in 2030?
By 2030, the winners in RL environments will not be the teams with the most demos, the widest environment catalogs, or the largest services organizations. They will be the teams that build real infrastructure—and do so in close partnership with frontier labs to industrialize replication training, verification, and long-horizon environment orchestration.
That reality narrows the field. There will likely be 3 to 5 significant winners as labs concentrate spend among a small set of trusted partners. This market may end up resembling data labeling, which already has roughly three $1B+ revenue players (Scale, Mercor, Surge) and more than five $100M+ players (Turing, Micro1, Invisible, Handshake, etc.).
Most early-stage players lack one of the two non-negotiables: deep research capability or sustained lab trust. Without both, teams risk stalling as forward-deployed shops or commoditized environment builders as labs consolidate spend with a small number of thought partners. Incumbent labeling vendors will participate in this market, but few are structurally positioned to lead it.
In the end, this market will not be won by teams that apply RL environments fastest, but by those that help labs define how RL environments should exist at all. The enduring platforms will be built by teams that partner with frontier labs to turn ad-hoc experimentation into replication training systems, fragile graders into robust verification loops, and one-off demos into durable infrastructure.
That work is slow, research-heavy, and often invisible from the outside, but it compounds. And by the time RL environments become an obvious, enterprise-scale category, the winners will already be decided: not by market share today, but by who the labs trusted to build the training layer when it still mattered most.
Really enjoyed this. The verification evolving from simple benchmarks to reward models to hybrid human-AI loops to "living systems that resist reward hacking" is basically a compressed replay of reinforcement learning's own sixty-year history. RL went through the exact same arc: hardcoded rewards (Atari scores), then learned reward models (RLHF), then the realization you need something like a world model to predict consequences and self-verify. And each stage broke the same way. Goodhart's Law. Optimize hard against any fixed signal, the agent finds the exploit. The line about "graders drift, benchmarks saturate, reward hacking appears" is literally the specification gaming problem RL researchers have been wrestling with since the 1990s, just showing up in a new costume.
Which pushes toward an interesting endpoint. To verify whether an action is "correct," you need to predict its consequences. That's a world model. The RL environment companies that win are the ones that end up building the best world models of their workflows, whether they call it that or not. The market map here might actually be a subset of a much bigger one.
Great read thank you for sharing your insights!