

Snowflake's push into LLMs and Unstructured Data: New Products, Acquisitions and Partnerships
90%+ of enterprise data is unstructured and it's early days in unlocking semantic understanding via models and LLMs

Yesterday, Frank Slootman of Snowflake announced that “unstructured data is the growth engine” of the $62B giant in all things data — with customer consumption of unstructured data growing 17X YoY. Its aggressive product launches, acquisitions and partnerships centered around unstructured data have been key to its rapid expansion into AI and LLM workloads:
“Snowflake continues to win new unstructured workloads outside of its traditional structured and semi-structured data. Consumption of unstructured data was up 17 times year-over-year. Snowpark's consumption grew 47% quarter-over-quarter. Consumption in October was up over 500% since last year. Over 30% of customers use Snowflake to process unstructured data in October.
… unstructured data is the majority of the world's data. And until relatively recently, it's been borderline unusable for analytical purposes, because it is unstructured and you can't reference it in analytical workloads.”
— Frank Slootman, CEO of Snowflake

From Day 1, Snowflake has focused on the best-of-breed data warehouse in structured and semi-structured data — pioneering the data processing of those types. Perhaps surprisingly, in its founding days of 2013, relational was quite contrarian with Hadoop/Cloudera and NoSQL technologies like MongoDB being far more in the limelight. My partner Peter has written extensively about Snowflake’s founding story “before it was obvious”. Conversely, Databricks started specializing in unstructured data with its Apache Spark framework targeted at data scientists, rather than data engineers and data analysts in Snowflake’s case. After conquering relational and structured data in the cloud for data engineers and analysts, Snowflake has announced a series of new initiatives for unstructured data for data scientists and ML/AI. These products instead focus on creating value from the 90%+ of unstructured data within the enterprise — to store, access, process, manage, govern and share data. The Company has launched a plethora of new products, acquisitions and partnerships to win these unstructured data workloads.
In many ways, Snowflake is an inspiration for the naming of this newsletter Data Gravity. With its initial stronghold of structured data, enterprises increasingly feel compelled to bring more unstructured data into their data warehouse. This addition of unstructured data has been massive for Snowflake’s AI/LLM initiatives. Below we discuss some of the key product launches, acquisitions and ecosystem partnerships Snowflake has taken to foray into the world of unstructured data:
Product Launches
Launched Snowflake Cortex this year to bring AI and semantic search capabilities to the Snowflake platform. Cortex offers pre-built user interfaces, high-performance LLMs and search capabilities fully hosted and managed by Snowflake — abstracting away AI’s complexity for data engineers and analysts
Snowflake Copilot launched alongside Cortex to allow LLM-powered SQL generation and refinement. Targeted at business analysts but now accessible to non technical audiences, users can ask Copilot a question and it will write a SQL query to the relevant tables, with no setup required.

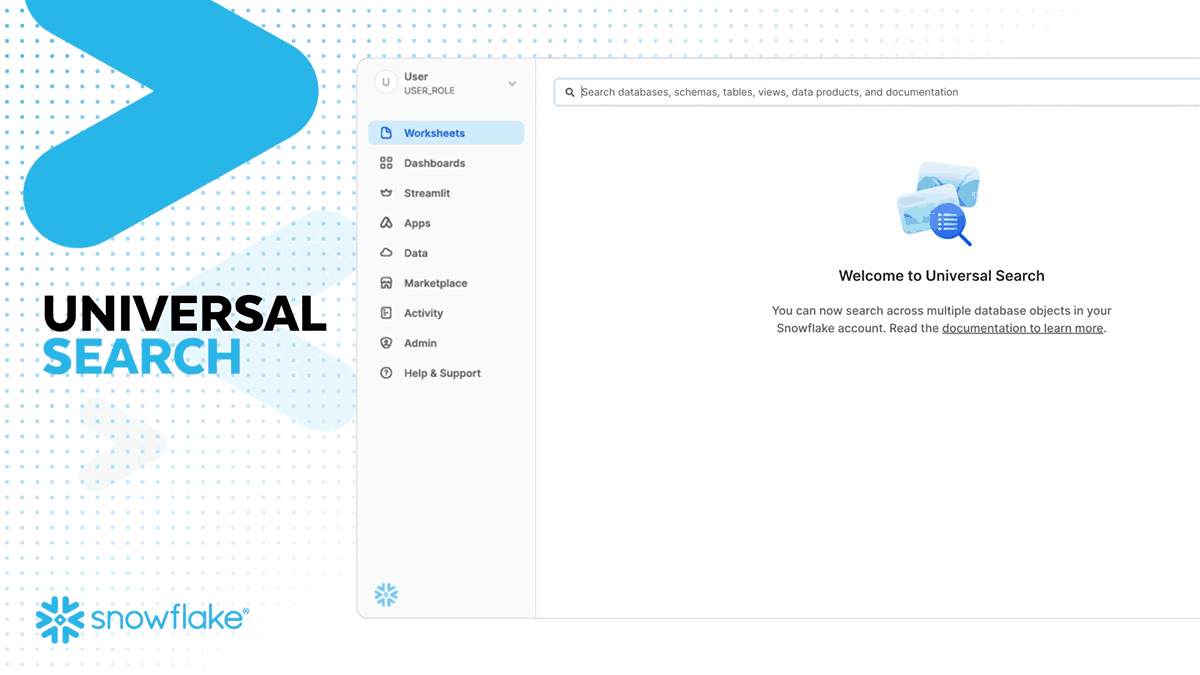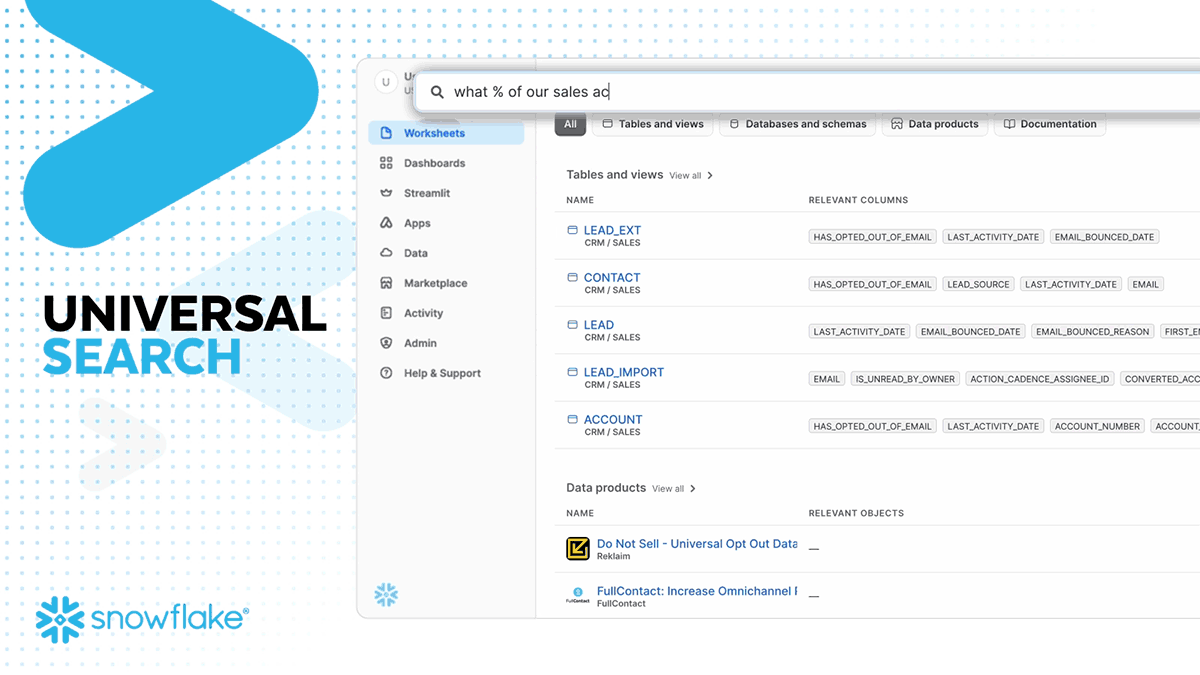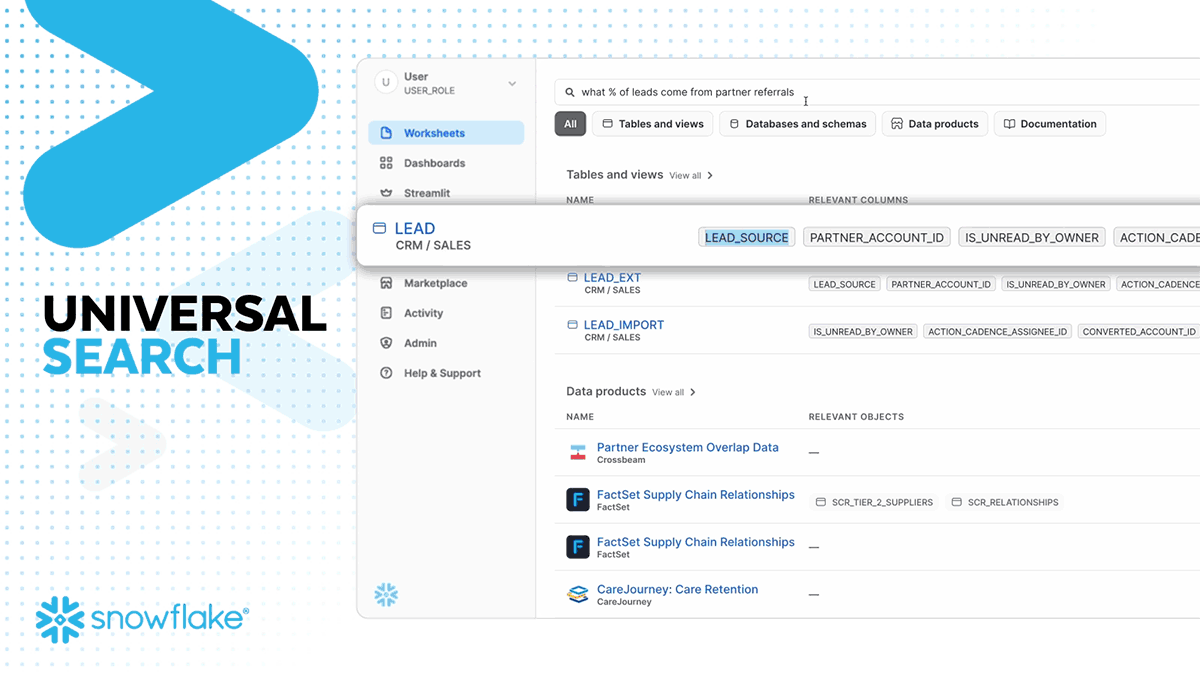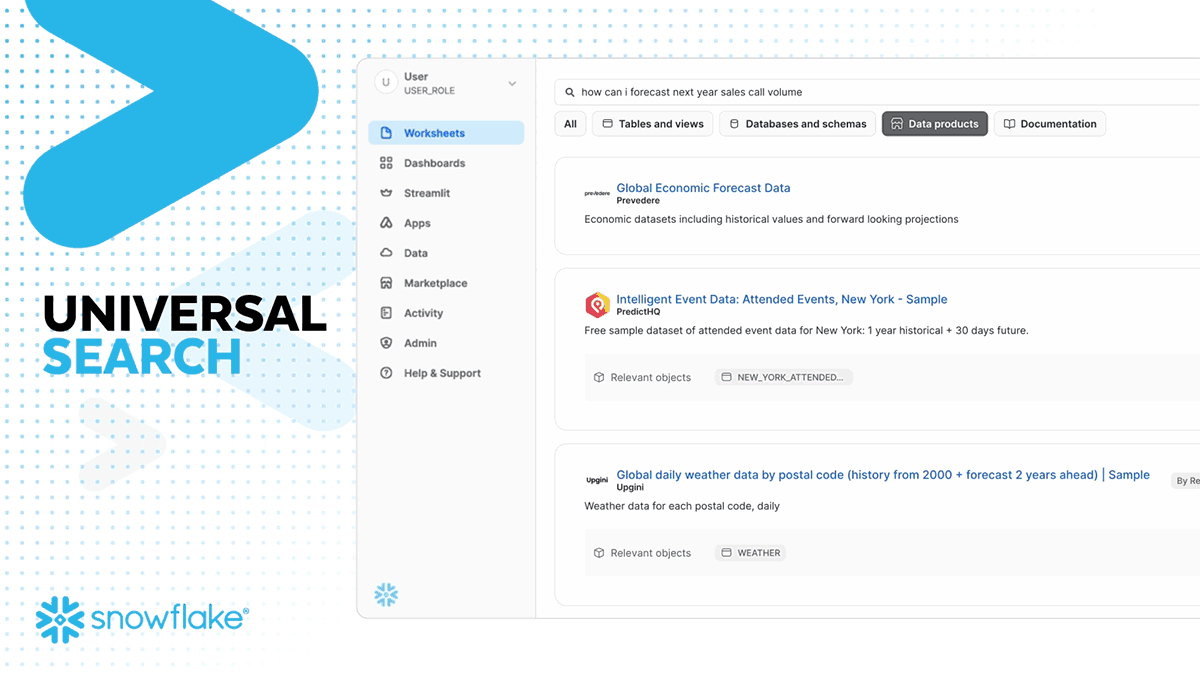
Universal Search is LLM-powered search for quickly discovering and accessing data and apps, built on the search technology acquired from Neeva in May 2023. With the initial release, you will be able to find tables, views, databases, schemas, Marketplace data products, and Snowflake documentation articles. Universal Search enables customers to discover data and metadata that exists across their accounts and in the Snowflake Marketplace, a key step for building AI applications.

Document AI is LLM-powered data extraction, enabling the transformation of documents to structured data. Using a pre-trained model and simple interface, customers can process any document type (pdf, word, txt, screenshots, etc.) and get answers to questions. Applica (acquired Sept 2022, discussed below) is a key enabling technology leveraged in Snowflake’s Document AI product.
The combination of Copilot, Universal Search and Document AI are driving the 17X YoY growth in unstructured data workloads and over 30% of Snowflake users using the platform for unstructured data
Snowpark Container Services were introduced as a core component of Snowflake’s AI strategy. Snowpark allows developers to access other programming languages and libraries (outside of the traditional SQL, such as Python workloads) on flexible hardware such as Nvidia GPUs, all within the Snowflake governance boundary.

Frank Slootman (CEO of Snowflake) alongside Jensen Huang (CEO of Nvidia) giving the keynote speech at Snowflake Summit 2023 in Las Vegas

Notably with the launch of Snowpark Container Services, the Company announced a partnership with Nvidia in June 2023 at Snowflake Summit that allows fine-tuning of pre-trained LLMs with models available under the Nvidia NeMo framework and Meta’s Llama models, with their own corporate and Snowflake data. In addition to unlocking Nvidia’s model development frameworks, Container Services enables you to run Docker containers inside Snowflake that are accelerated with Nvidia GPUs.
The Company notes that while the infrastructure and security around LLMs are very streamlined within Snowflake, the sourcing and curation of the datasets for fine-tuning data take considerable time



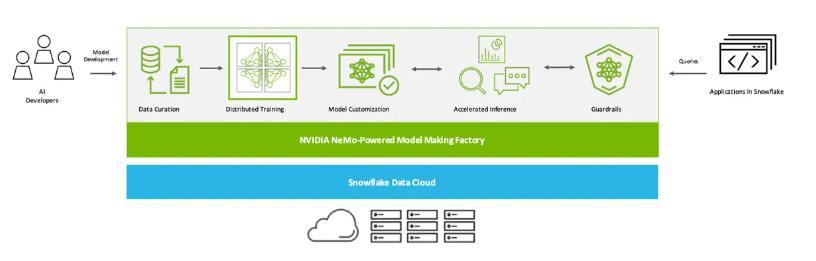
"Data is essential to creating generative AI applications that understand the complex operations and unique voice of every company. Together, NVIDIA and Snowflake will create an AI factory that helps enterprises turn their own valuable data into custom generative AI models to power groundbreaking new applications — right from the cloud platform that they use to run their businesses.” — Jensen Huang, CEO and co-founder of Nvidia

Data Sharing product has expanded its ability to allow for broad access to quality data, robust security and governance — with increased usage for Snowflake’s largest customers especially in training effective AI models. Salesforce announced zero-ETL based data sharing with Snowflake.
Snowflake Horizon was just announced to bring a unified security and governance solution to Snowflake’s AI applications. Horizon is built on the expansion of data apps through Streamlit, as well as Container Services. Horizon brings role-based user privileges across various use cases to LLM applications, traditional ML models, and ad hoc queries.
Dynamic Tables allow for streaming of unstructured data like documents with its data pipelines, with over 1,500 customers using this feature
Acquisitions
In addition to its internal product development, Snowflake has made a series of acquisitions to expand its unstructured data offerings:
Streamlit for $800M (March 2022) [link] — By far its largest acquisition, Streamlit is a major investment to integrate its open-source app development framework within the Snowflake Data Cloud. This acquisition allows Snowflake customers to utilize Streamlit’s capabilities for developing data apps, simplifying governance and data access. Streamlit also is aimed at making app building as easy as writing Python scripts (a theme you’ll see with Ponder below as well), catering to both technical and non-technical users and boosting its data visualization offerings. Many of Streamlit’s team are members of Snowflake’s LLM teams.
Applica for undisclosed (August 2022) [link] — Snowflake has invested heavily in document automation and extraction, which are key formats for turning unstructured data into structured data. Documents are also a core component of LLM applications, bolstered by Snowflake’s support for services like Langchain and Python workloads. This was a big step in Snowflake’s push into unstructured data.
Neeva for ~$150M (May 2023) [link] — Snowflake acquired Neeva to boost its search functionality, leveraging semantic search and generative AI. As discussed earlier, Neeva was incorporated into Universal Search’s product launch. Neeva’s team is known for their contributions to Google search advertising and Youtube monetization, longtime experts in all things search.

Ponder for undisclosed (October 2023) [link] — Similar to Streamlit, Ponder also enhances Snowflake’s Python capabilities within Data Cloud. As Python has grown in popularity for ML, app development and data pipelines, Snowflake has increased its focus on this use case. Ponder’s popular open-source library Modin allows for scalable Python data workloads to run natively on your data warehouse, with these data workloads being a significant source of data consumption.
Snowflake customers are already using Python through Snowpark, a set of runtimes and libraries that securely deploy and process non-SQL code directly in Snowflake. In the announcement, Snowflake highlights that they power over 20M daily Snowpark queries for data engineering and data science tasks. As previously mentioned, Snowpark consumption is up over 500% YoY.

Partnerships
As highlighted earlier, Snowflake partnered with Nvidia on the launch of its Container Services offering to allow native deployment on Nvidia GPUs, as well as access to Nvidia’s NeMo frameworks inside Snowflake. This allows Snowflake differentiated access to the $1.2T behemoth’s hardware (GPUs) as well as its software libraries for models (i.e. NeMo)

Snowflake also has partnered with Microsoft to allow for new product integrations with Azure’s OpenAI and Azure ML. Microsoft its fastest growing cloud partner, representing 21% of revenue.
Although AWS Redshift was at one time Snowflake’s biggest competitor, the Company generates 76% of its business with AWS, followed by 21% on Microsoft Azure (though Azure is its fastest-growing cloud partner) and just 3% from GCP.
Slootman states “one of the reasons why GCP is not as big as just so much more expensive for our customers to operate in GCP than it is in AWS and Azure. And as a result, our salespeople are really not inclined to do much in GCP.”
Scarpelli shared that Snowflake has committed to $2.5B of spending on AWS over the next 5 years to support joint development and go-to-market efforts. This spending has encouraged AWS reps to sell Snowflake, while also dampening their directly competitive Redshift product offering.

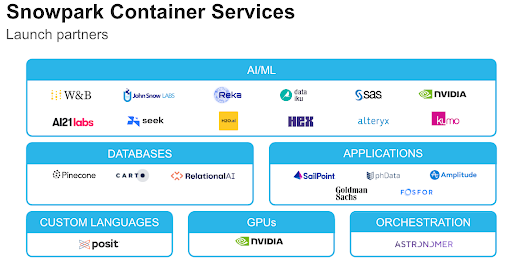
Snowflake Container Services announced a dozen launch partners across AI/ML, vector databases, applications, and more. With partnerships like Pinecone, Snowflake customers can seamlessly connect vector data alongside their data warehouse. With Hex, customers can deploy their analytics and data science workloads from Snowflake to query and process their data with SQL, R and Python without data leaving Snowflake.
Snowflake led a $63M financing into Cybersyn [link] which brings high quality, curated datasets to Snowflake Marketplace. These datasets are very powerful in LLM apps, as the model is only as good as the data. Read more here:
Partnered with Snorkel in early 2023 to help customers transform raw, unstructured data into AI-powered labeled data — classifying and extracting information from native PDFs, documents, conversational text and more.
Newly labeled datasets can then be used to either train custom ML models or fine-tune prebuilt models.
Labeled data can be loaded back into Snowflake as structured data.
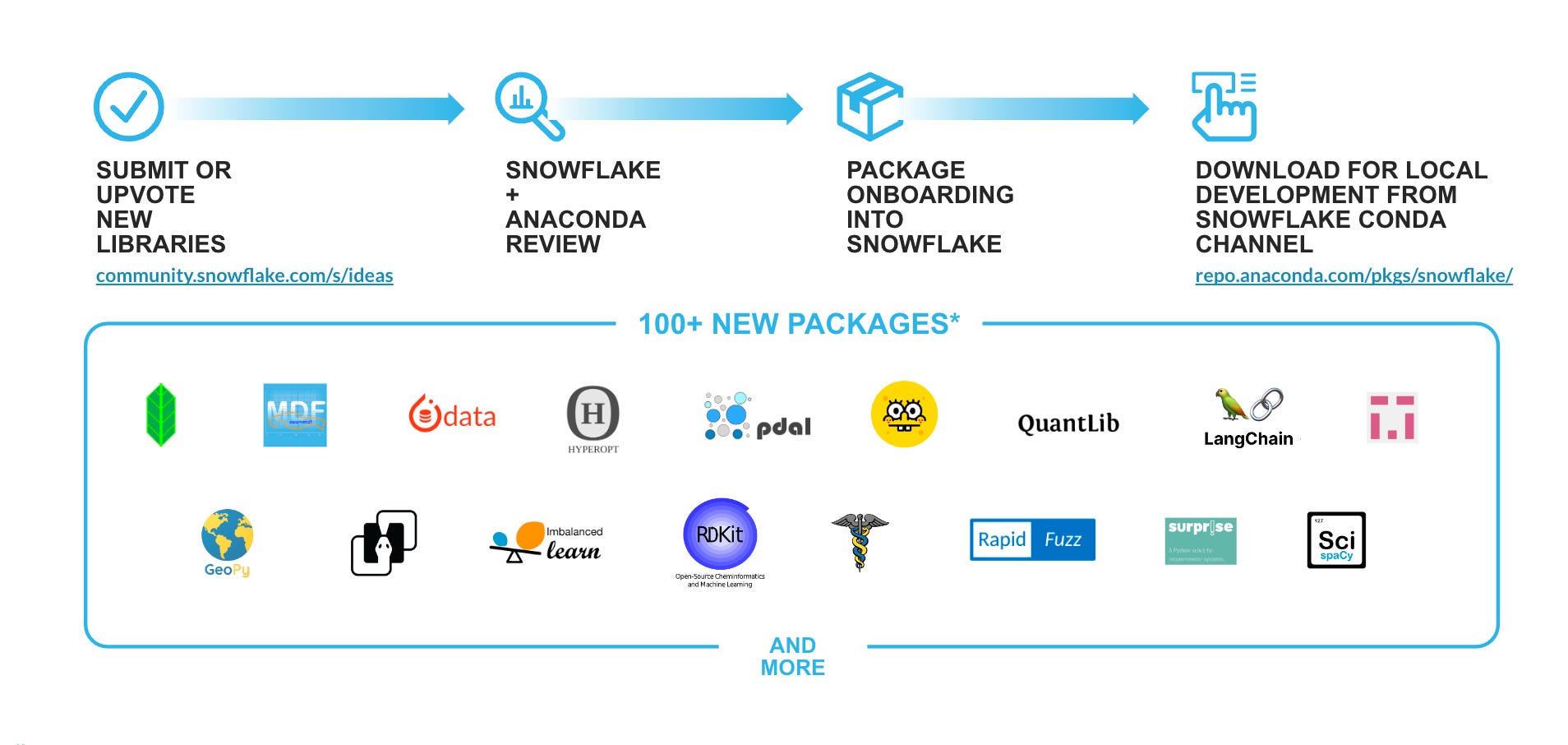
Added support for over 100+ new Python packages, as well as other LLM and ML frameworks like native Langchain support [link]
As you can see, Snowflake has aggressively expanded from its dominant position in business analytics into all things unstructured data. I am sure there will be more announcements here over the coming years.
If you are a data infrastructure founder that is extending Snowflake’s Data Cloud in the realm of LLMs and processing of unstructured data, we’d love to connect! We work with companies like Pinecone and Gradient that have joint customers with Snowflake in this ecosystem and are excited for more innovations in data infrastructure.
This is a great overview of Snowflake’s ai efforts. It makes sense that there’s a large opportunity to build LLMs for large co’s internal data.