

The Future of Data Labeling: From Stop Signs to AI Specialists
How Scale's dominance in self-driving positioned the Company to win in AI model training data and how recruiting specialists is the future of data labelling

Between 2018 and 2022, data labeling was dominated by a gig economy model, epitomized by Scale AI. Workers earning pennies per task labeled billions of images of stop signs, crosswalks, pedestrians, deer, and other objects critical to autonomous vehicles and computer vision systems. At its peak, Scale AI was reportedly processing over 100 million labeled data points per month, enabling a generation of supervised learning systems to outperform human perception in narrow domains.
This “assembly line” approach to data labeling treated data as a mass-produced commodity — harvested at low cost and with minimal context, much like a raw industrial material.
That era is decisively over. However, building the huge business Scale did enabled the company to win this new era.

Data as a Bottleneck: A New Recruitment Challenge
Modern frontier models, particularly LLMs and multi-modal systems, have far surpassed the ability of basic crowd-sourced labels to train them. Instead, models now require high-context, domain-specific, and sometimes real-time feedback to stay competitive.

Instead of labeling dogs and cats, these systems must now learn:
How to interpret legal briefs
How to reason through medical diagnoses
How to code correctly across dozens of frameworks
How to explain financial statements
This means recruiting specialists — coders, financiers, lawyers, doctors — who can supply precise, context-rich annotations. Managing these highly paid, scarce human resources is no longer a simple “click to hire” task. Instead, coordinating them has become one of the hardest problems in modern machine learning operations.
👉 One estimate from a major AI vendor suggests that expert annotators cost 20–40× more per hour than generic crowd workers.
Data as a Strategic Moat
As model architectures increasingly converge — everyone has a transformer, everyone scales to billions of parameters — the competitive edge has moved squarely to data pipelines. Data, alongside compute, has become the defining moat.
A remarkable illustration of this comes from Anthropic. In 2025, Anthropic physically destroyed millions of print books to scan them into digital training sets, then won a lawsuit defending that mass digitization as legal under fair-use doctrines (Ars Technica). This bold, even destructive, strategy demonstrates how desperate top labs are to build defensible data advantages.
Today, the largest AI companies are spending $1–2 billion per year on human-in-the-loop reinforcement learning and other data-collection pipelines. That spend is only growing, with some forecasts suggesting data-labeling budgets could double by 2027, reaching over $10B annually across the top 10 labs. Today this number is about $5B.

Vendor Fragmentation and Neutrality
Previously, major players like OpenAI, Anthropic, Google, ByteDance, Apple, and xAI leaned on one or two major data-labeling partners — often Scale AI — to run their pipelines. But after Meta’s enormous $15B investment for a 49% stake in Scale AI, the landscape fractured. Rivals, worried about vendor lock-in and neutrality, have diversified their labeling partners:

Micro1 (engineering and healthcare-focused labeling)
Turing (specializing in complex RL workflows)
Surge (high-quality human reinforcement learning feedback)
Datacurve (niche coding domain experts)
These vendors have carved out specialties, providing higher-skill annotation for coding tasks, legal reasoning, and financial audits. Instead of treating data labeling as a single interchangeable commodity, labs are now orchestrating entire supply chains of human expertise across multiple providers to minimize risk and optimize for data quality.
👉 Think of it like diversifying your suppliers in a geopolitical crisis — with the supply being domain experts that capture nuanced reasoning of domain experts.
Research Speed as the Differentiator
In today’s AI competition, the rate of experimentation and iteration has become the critical differentiator. Reinforcement learning workflows — guided by expert supervision through authentic, real-world scenarios — have become central to staying competitive. The labs that can design, test, and refine these loops fastest will dominate.
Companies like Turing have built advanced orchestration platforms, often called “RL gyms,” to manage these cycles at scale. These systems coordinate human labelers, evaluation frameworks, and live experiments, dramatically shortening iteration times. In practice, this can let a lab validate and adapt three times as many hypotheses in the same window, sharply improving their odds of discovering breakthroughs.
The lesson is clear: in startups, speed to achieving product–market fit determines winners in startups; in AI, it’s the speed of adapting data to a model’s needs that sets leaders apart. The entire research engine must move quickly and flexibly, turning high-quality expert feedback into tangible model gains faster than rivals. That agility is increasingly the deciding factor in who stays ahead.
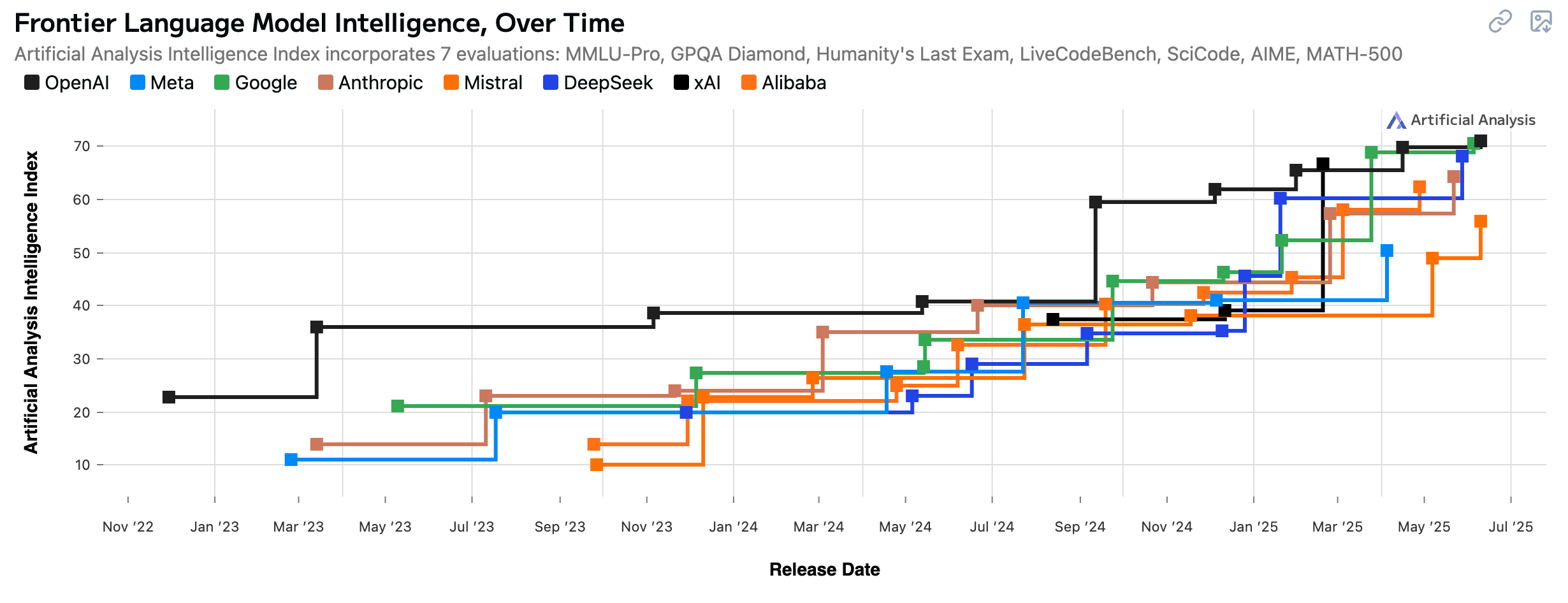
Source: Artificial Analysis [link]
Outlook: Domain-Specific AI is built on Data Strategy
If the 2010s were defined by breakthroughs in model architecture, and the early 2020s by scaling billion-parameter transformers on vast GPU clusters, the late 2020s will be dominated by data strategy — especially for domain-specific AI companies. In these more specialized areas, where models must understand legal reasoning, medical decision-making, or advanced coding tasks, data is no longer just fuel — it is the moat.
Proprietary, high-quality data will be the ultimate barrier to entry
Domain experts will be the most constrained and valuable resource
Research velocity — the ability to quickly iterate on high-signal, domain-relevant data — will define competitive advantage
The field has moved beyond simple tasks like labeling stop signs, now prioritizing richly detailed expert reasoning with deep contextual nuance. Managing and coordinating specialists, compressing reinforcement learning loops, and building truly defensible data pipelines will separate the leaders from the laggards.
For founders and investors, the lesson is clear: owning the right data — the rarest, highest-impact, domain-specific data — is what will define the next generation of winners in AI.
Checkout https://www.hirecade.com/hire-data-annotator
Expensive but much better data quality!