

The History of the GPU and Insights on the Future of AI Compute
Historical and forward looking perspectives from Raja Koduri on the future of Hardware / Software for developers

Raja Koduri is one of the leading minds on the history of the GPU and the future of AI compute. He directly shaped the past having spent 13 years at AMD, 4 at Apple and 6 at Intel leading various graphics processing and accelerated computing initiatives. This week, he presented at Stanford on the history of the GPU architecture from 1990’s to now. Much is similar to his 2020 presentation “No Transistor Left Behind” Hot Chips 2020 keynote — which is absolutely worth a listen.

Summary:
This presentation delves into the GPU industry's journey, addressing not just technical metrics like picojoules per flop but also industry dynamics
Koduri provides insights into GPU architectures from a workload perspective and discuss emerging architectures like accelerating Python and in-memory computing
In a 2020 keynote at the Hot Chips conference at Stanford, Koduri predicted that by 2025, data centers would need zetaflops of AI processing power, requiring a thousandfold increase in computing capability. This prediction is being realized, as evidenced by massive orders for Nvidia's GPUs by major tech companies.
How we imagine the hardware-software library (simple)


Software
Instruction set architecture (i.e. CUDA)
Hardware
The reality of the AI compute stack: much more complicated, Swiss-cheese full of holes in the middle that create huge performance issues

FW IP & Bios
Drivers
OS
Virtualization/Orchestration
Low level Libraries
Middleware frameworks and runtimes
Applications
Services and solutions
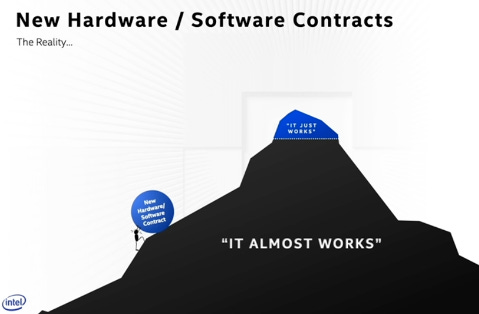
In the Hardware / Software Contract, pay attention to the whole system software stack — not just CUDA but drivers, memory, bandwidth, etc. (first image above)
The boring parts will kill your startup
The exciting parts will work
Building chips that work in different environments more challenging than it appears appears — no vendor outside of Nvidia works on more than 5% of the models on Hugging Face out of the box
Nvidia works on over 80% of models out of the box
Venture capital investments in AI hardware have been substantial, with $20 billion invested since 2016. However, the return on these investments has been challenging, with total revenues of these companies being less than $100 million.
Meanwhile Nvidia will do >$30B of quarterly revenue in the coming quarters.
It is deceptively hard to build hardware the operates with the full software stack. Despite $20 billion in funding for various startups, Nvidia, with a focus on the same AI challenges, has outperformed them, achieving $30 billion in quarterly revenue.
The boring parts = Nvidia’s moat; not just CUDA
Why do CUDA GPUs dominate AI?
80%+ of models on Hugging Face work out of the box on CUDA / Nvidia
All other chip architectures (CPUs, AMD, startups, TPUs, ASICs) — no single one has even reached 5% coverage
All the models are Python or Pytorch — you don’t find that much code related to hardware. More complicated than it appears under the hood
Model Developer / AI / Data Scientist perspective on GPUs — what impacts their hardware experience as developers?
Programming flexibility
Very large models
Memory bandwidth
Interconnect bandwidth
Compute
Memory Capacity
Node Scaling
CPUs —> offer best programming flexibility and memory capacity
GPU —> High flexibility, high memory bandwidth, high interconnect Bandwidth, Compute
Nvidia has the best coverage of all vectors

The History and Evolution of GPUs:
Initially, GPUs were primarily used for gaming.
Many industry analysts proclaimed the death of Nvidia and GPUs as they lacked enterprise applications
GPUs survived numerous other predictions of obsolescence, from being deemed irrelevant for enterprise applications to facing threats from mobile technology and Google's TPU
The integration of graphics into chipsets by Intel marked a significant industry shift
IEEE 32-bit floating point in 2005 mapped CPU to the GPU
The journey of modern GPUs began around 2002, standing on the shoulders of giants from Silicon Graphics, Pixar Renderman, AMD and others
Pixar Renderman was the inspiration for the GPU software model
Invented a mass market parallel computing paradigm
Data is exceeding our ability to understand and process

The evolution of GPUs has been intertwined with the development of the entire software stack, from boring but necessary components to significant innovations like Tensor Cores.
The hardware-software contract is crucial, with Nvidia achieving dominance by maintaining a stable and pervasive contract over time.
GPUs work on Vectors, a key driver of performance

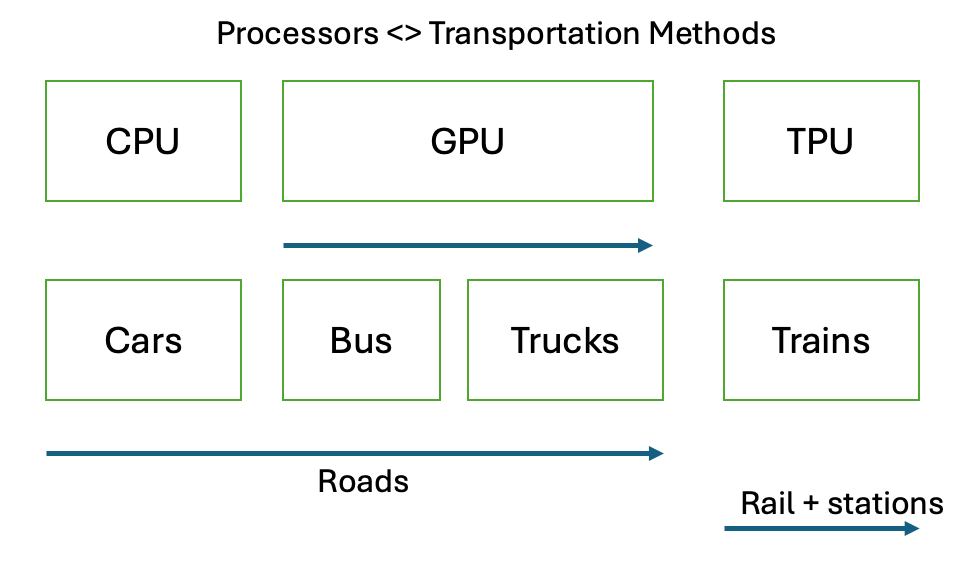
Processors <> Transportation Analogy:
The hardware architecture debate = religious debates. There are analogies to transportation methods which are workloads.
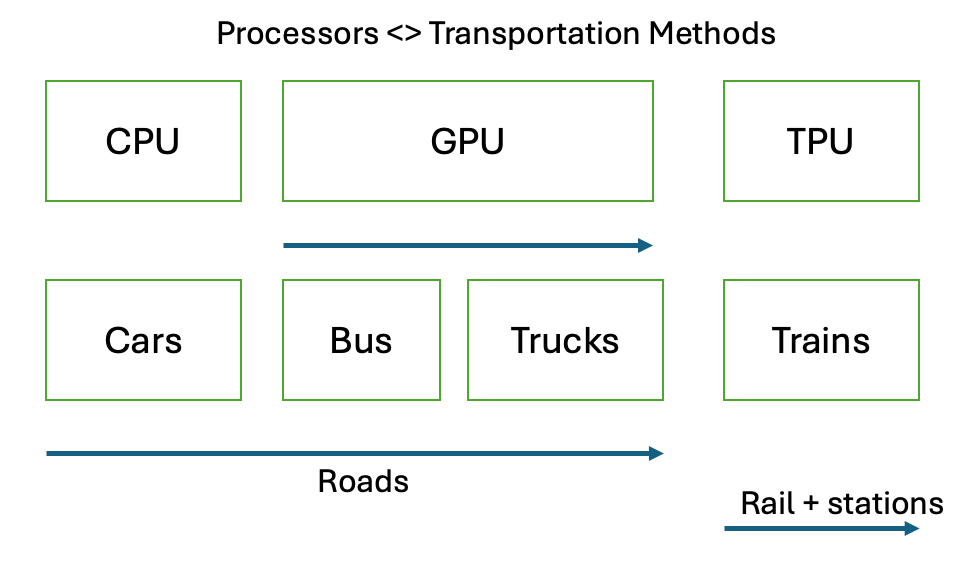
CPUs vs GPUs vs. TPUs <> Cars vs. Bus vs. Trucks vs. Trains
Cars and buses work on same infrastructure (roads) — with some inconvenience of bus stops
If the bus stop is right next to your home, you’re lucky
18-wheelers on big highways also on the same highway and infrastructure
Trains are on different infrastructure (stations and rails)
But if you can get to station, runs great
We are a mix of all transportations, none absolutely better and each have pros/cons
In Europe or Japan, more trains
CPUs (cars) are very flexible, not very performant. They work on Scalar.
For one person, I could pack 3 more passengers in a car. Like a CPU, can pack a few workloads in and it’s flexible.
If I had a bigger group (Bus/truck), I would take a different method of transportation for my workload
Without a good group size, GPUs are very inefficient and require a certain station
When adding Tensor GPU (Matrix) — that is more like a train and a different architecture altogether than GPUs
Getting more train-like efficiency for specific workloads
How do you get developers to your infrastructure or your “stations”?Nvidia brought more bus stations to the developers, which now rivals the x86 CPU developer ecosystem

In the future, I will say I want to go to Stanford — I don’t really care how I get there, care about efficiency
Software will define the routing of the workload
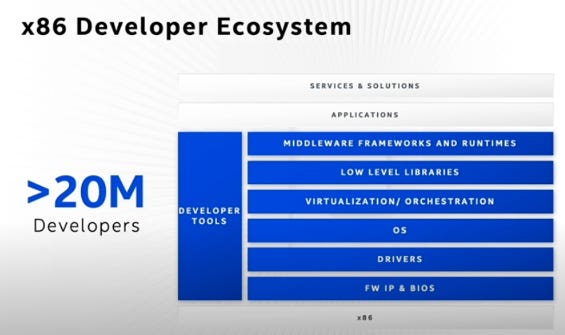
The Hardware <> Software Developer Ecosystem:
In sitting next to AI programmers and data scientists — how they work is very different even though overlapping terminology
Performance in semiconductors means speed, but in AI it means quality and the model converging the results they want to achieve
AI programmers care about speed too but performance quality is far more important
Hardware engineers care about speed far more

The Future of AI Compute —> 100M+ AI Developers
Innovations with memory that work with Python ecosystem will likely be the next disruption
Python has become the defacto programming language of choice for AI
If LLMs and transformers are here to stay, they are way more memory and bandwidth bound than any other workload I have ever seen
Compute is the easy part that continues to progress, memory is the hard part
Huge amount of startup opportunity to solve this problem [In-memory and near-memory computing IP]
Cost of GPU and AI Compute comes down ~16X by 2027
3 key performance vectors:
Cost per GPU —> $40K to ~$10K (4X improvement)
PJ per flop —> improves 2X
PJ per bit —> improves 2X
16X improvement in compute cost