

The Inference Unbundling: Why Prefill and Decode Are Splitting the GPU
Different physics, different silicon, different margins. Nvidia/Groq and Cerebras/AWS are the market pricing the split.

Inference is not one workload. It is two — prefill and decode — and they want different silicon. The market is splitting accordingly. Nvidia bought Groq for $20B. Cerebras partnered with AWS Trainium. Both pair a compute engine with a memory engine. The single-accelerator era is ending. Disaggregated inference, as Cerebras frames it in 'The GPU is Being Split in Half', is beginning.

What replaces the single chip is a routed inference stack: each request flows through a FLOPs-rich accelerator for prefill, hands the KV cache to a memory-bandwidth-rich accelerator for decode, and streams the output back. The diagram below is the architecture; the rest of this piece is why the physics demand it and what the market consequences are.
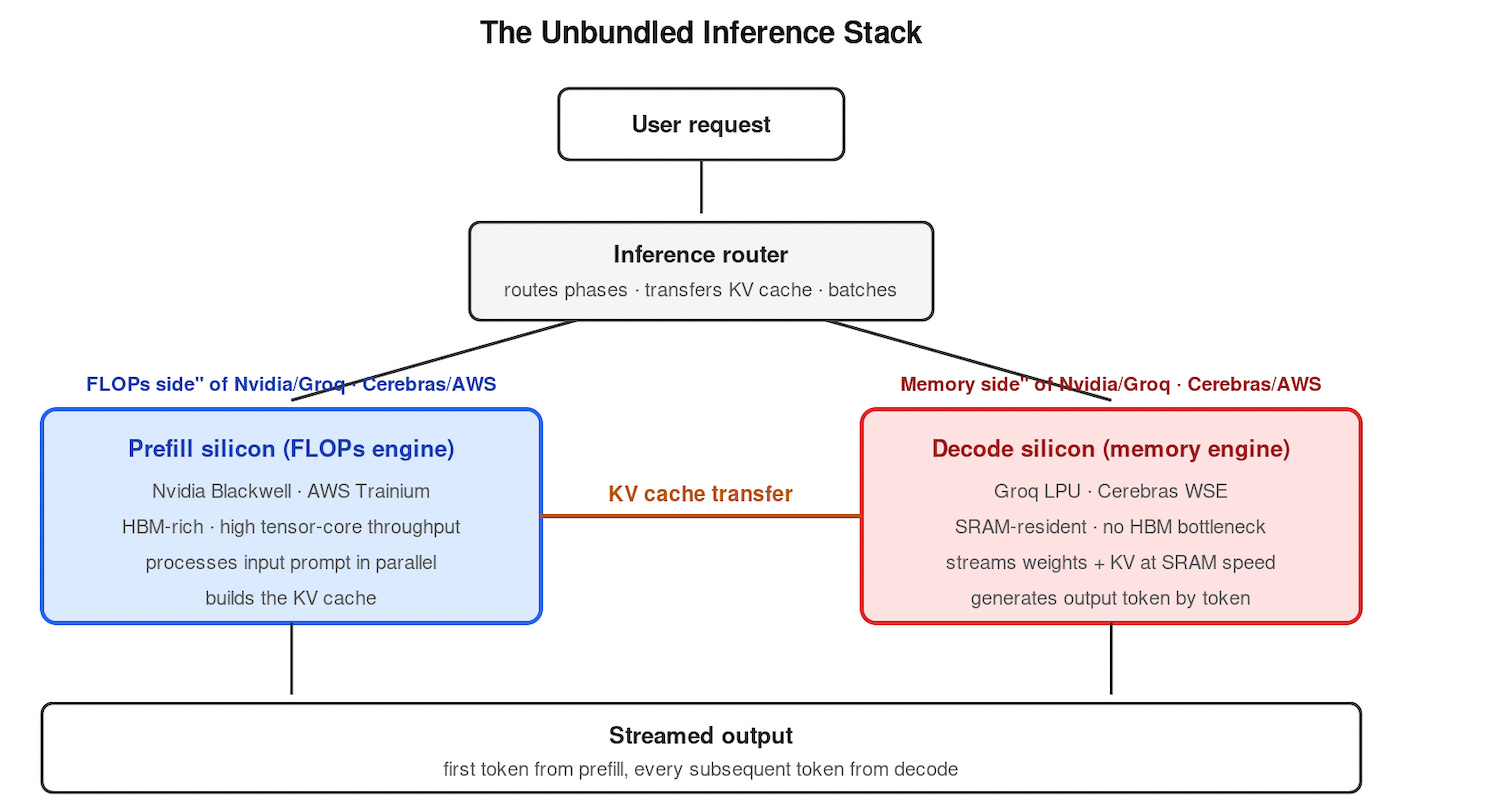
The Two Phases
LLM generation is autoregressive: every output token depends on every token that came before it. That dependency creates two computational regimes.
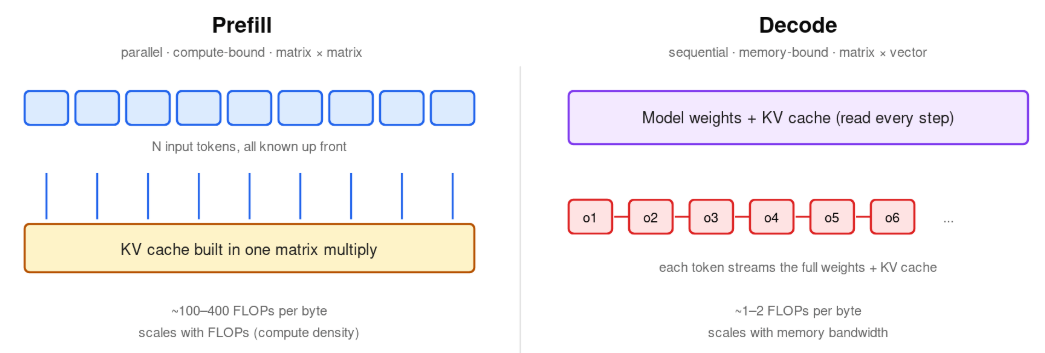
Prefill processes the input prompt. Every prompt token is known up front, so the model computes their key/value vectors in parallel — one large matrix multiply that builds the KV cache. Compute-heavy. FLOPs-bound. High arithmetic intensity, on the order of 100–400 FLOPs per byte read.
Decode generates output tokens one at a time. Each step streams the full model weights and the entire KV cache from memory to multiply against a single activation vector, then appends one new K/V pair to the cache. Bandwidth-heavy. Low arithmetic intensity, roughly 1–2 FLOPs per byte.
Same model. Same hardware. Two different workloads.
The Metrics That Decide Deployment
Two latencies decide whether an inference deployment is usable.
Time to first token (TTFT) is set by prefill. Interactive UX breaks above roughly 3 seconds.
Time per output token (TPOT) is set by decode. Interactive targets sit at 100–300 ms per token, at minimum matching reading speed.
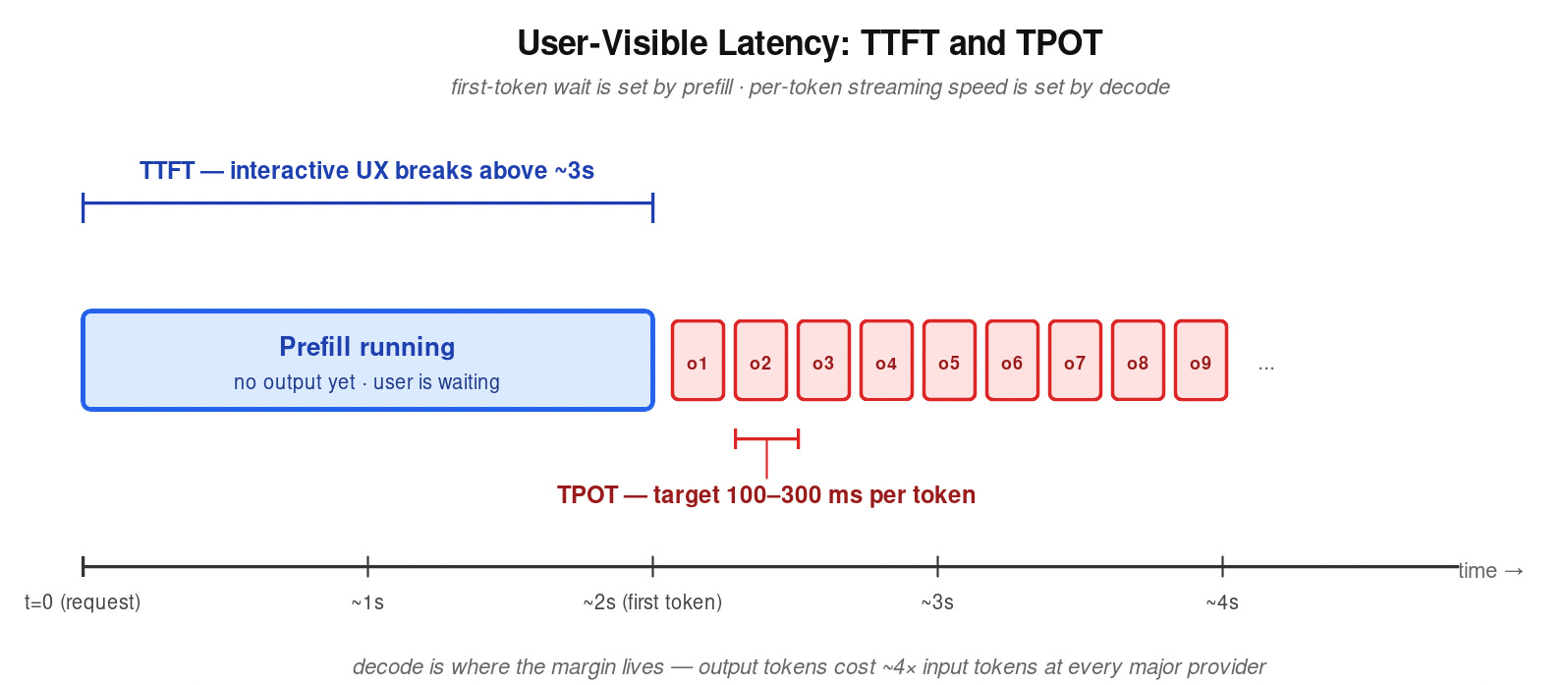
API pricing reflects the asymmetry. Output tokens cost meaningfully more than input tokens at every major provider — GPT-4o lists $2.50 per million input tokens against $10.00 per million output tokens, a 4x premium on the memory-bound phase. Decode is where the margin lives.
Why One Chip Can’t Do Both Well
Modern GPUs are designed around HBM-fed tensor cores. Prefill uses both. Decode uses neither well — the tensor cores idle while HBM saturates streaming weights for a single output token at a time. Plot it on a roofline and the two phases sit on opposite sides of the knee.
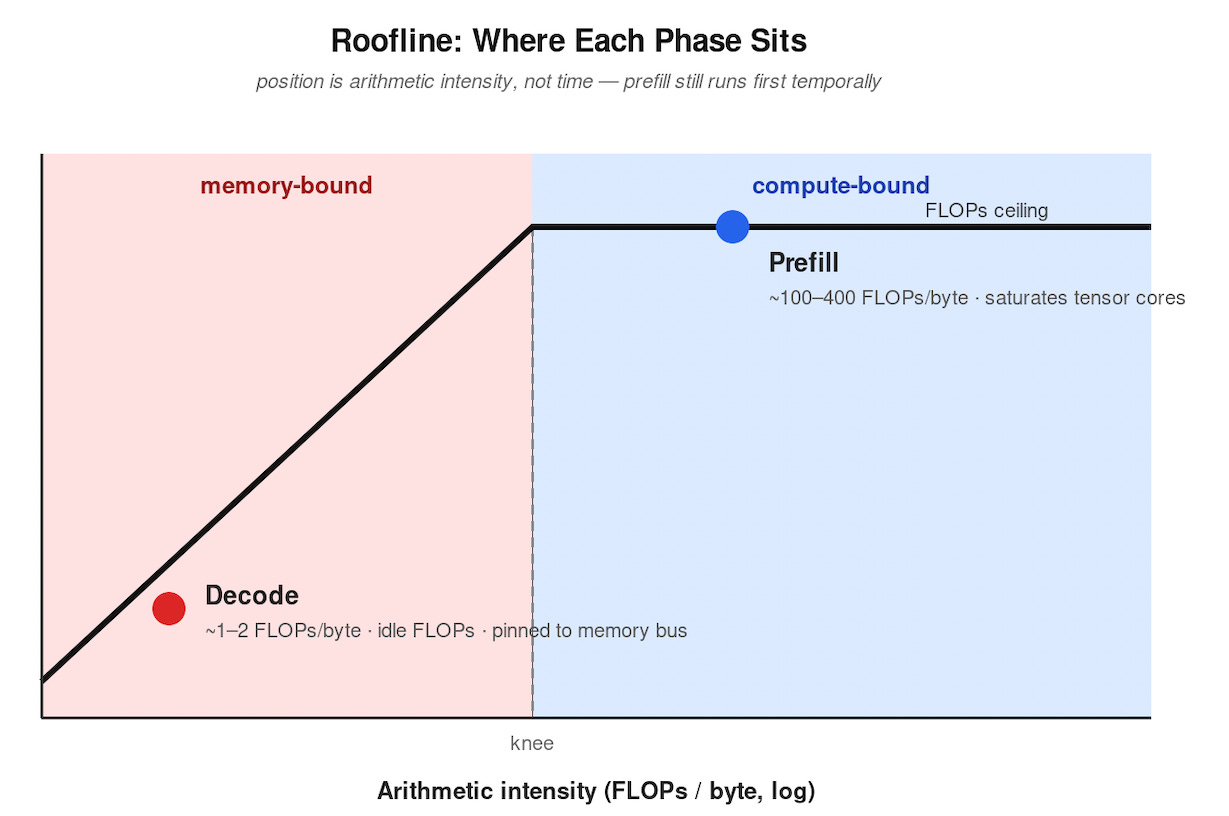
Inference engines have spent the past two years working around this. vLLM’s chunked-prefill scheduler interleaves prefill chunks with decode steps so compute and memory bandwidth saturate simultaneously on the same GPU. TNG Technology Consulting reports the technique increased total token throughput by approximately 50% in their production vLLM deployment serving Llama-3.1-8B (source). The lesson is structural: even on one chip, the operator gets paid to treat prefill and decode as different jobs.
The silicon-level unbundling is the same trick at scale.
Nvidia + Groq: FLOPs Buys Bandwidth
Nvidia owns prefill. Hopper and Blackwell are HBM-rich and FLOPs-rich, and they run the dominant share of frontier-model context processing. They do not own decode economics. HBM is supply-constrained — three vendors (SK Hynix, Samsung, Micron) — and decode burns bandwidth that could otherwise serve training.
The relevant Nvidia HBM specs:

Each generation buys more bandwidth, but the underlying architecture is still HBM-fed tensor cores. Decode still loads the full weight matrix from external memory for every token.

Groq is the architectural opposite. No HBM. The LPU runs entirely from on-die SRAM, which is faster per byte than HBM by at least one order of magnitude and is not bottlenecked by the HBM3e supply chain. The chip does not win on raw FLOPs. It wins on bandwidth-per-dollar, where bandwidth is the constraint — i.e., decode.

Acquiring Groq lets Nvidia route prefill to Blackwell and decode to LPUs over high-bandwidth fabric. The HBM bus stops being the bottleneck on output-token economics. Nvidia’s HBM exposure on inference workloads tightens. The strategic prize is freeing HBM supply for training, where it has no substitute.
Cerebras + AWS: SRAM Meets Trainium

Cerebras is the wafer-scale extreme. The WSE-3 is a single 46,225 mm² die — roughly 57x the silicon area of an H100 — with 44 GB of on-chip SRAM. A 70B-class model and its KV cache fit on-die. Decode runs at SRAM speed. Cerebras has built its commercial pitch around sustained tokens-per-second on memory-bound inference, and the architecture maps directly onto the decode workload.
What Cerebras lacks is fleet-scale prefill capacity. CS-3 systems are scarce, capital-intensive per unit, and optimized for memory-bound work. Long-context prefill — increasingly the dominant workload as agentic and reasoning models drive context windows toward 1M tokens — needs cheap, abundant FLOPs.
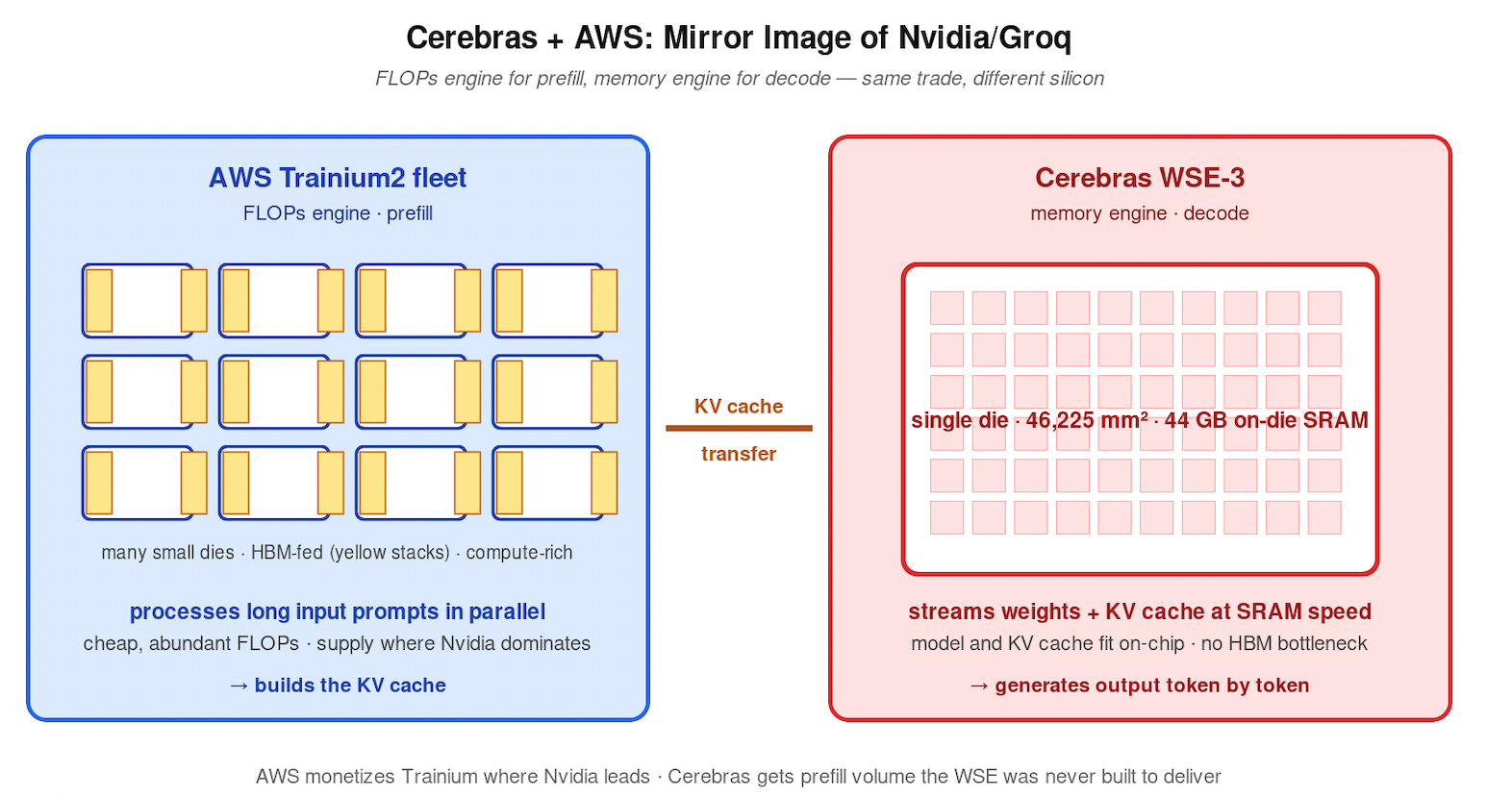
AWS Trainium fills the gap. Trainium2 is a high-FLOPs, HBM-equipped accelerator built for compute-bound work. The integrated Cerebras–AWS stack runs prefill on Trainium fleets, hands KV state to Cerebras CS-3 systems, and serves decode at wafer-scale bandwidth. AWS monetizes Trainium silicon on a workload where Nvidia GPUs already dominate. Cerebras gets the prefill volume the WSE was never designed to deliver.
Mirror-image strategy to Nvidia/Groq, same underlying thesis.
The Economics
Three forces make the unbundling structural rather than a clever optimization.
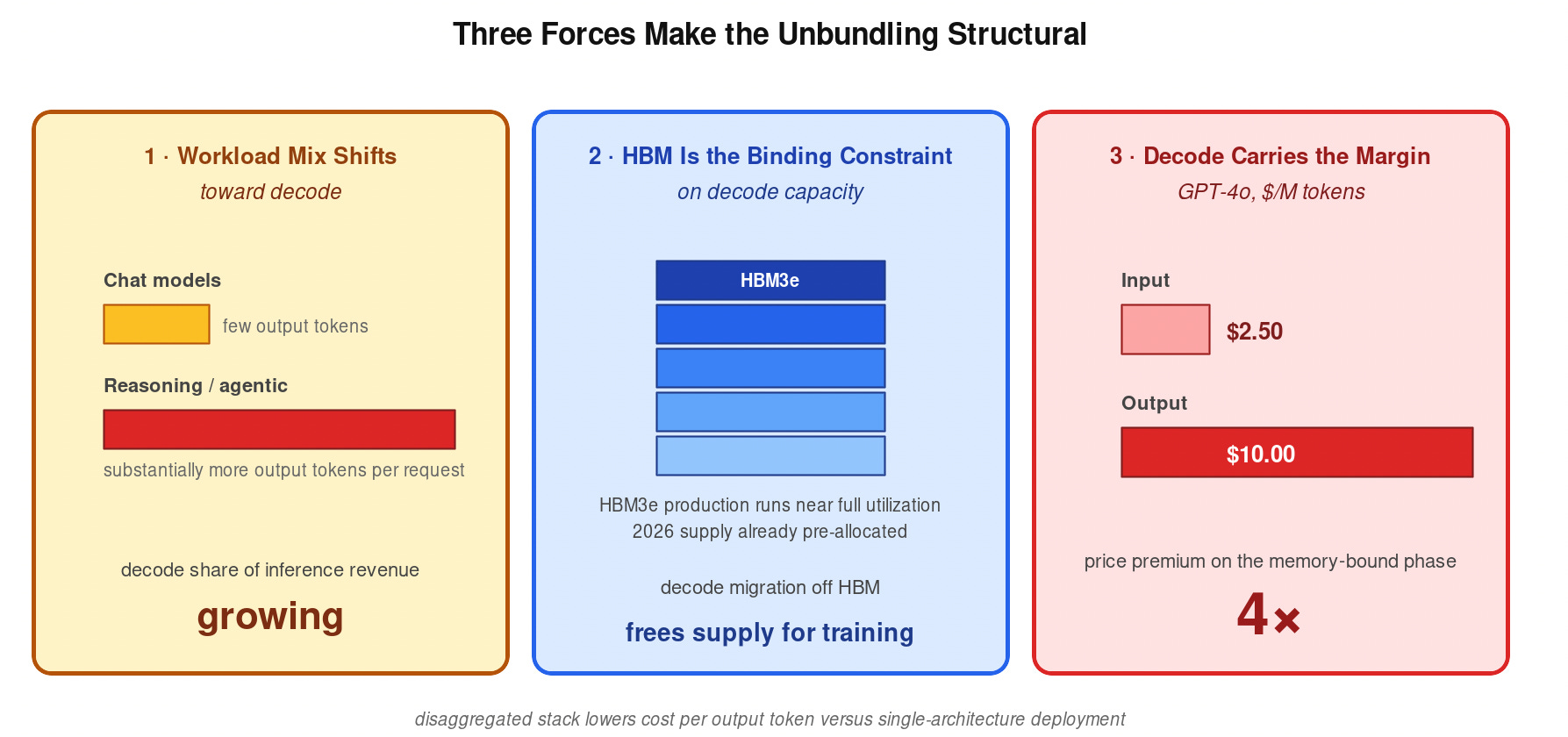
Workload mix is shifting toward decode. Reasoning and agentic models output substantially more tokens per request than chat-style models did 18 months ago. A growing share of frontier-model inference revenue comes from decode rather than prefill.
HBM is the binding constraint on decode capacity. HBM3e production runs near full utilization, with 2026 supply already pre-allocated. Any decode workload that migrates to SRAM-based silicon frees HBM for training and prefill, where the alternatives are worse.
Decode carries the margin. At a 4x price premium over input tokens, decode is the gross-margin lane. Operators serving decode on lower-cost silicon capture the spread directly. A disaggregated stack lowers cost per output token versus a single-architecture deployment — the exact figure depends on workload mix, but the sign is unambiguous.
What This Changes
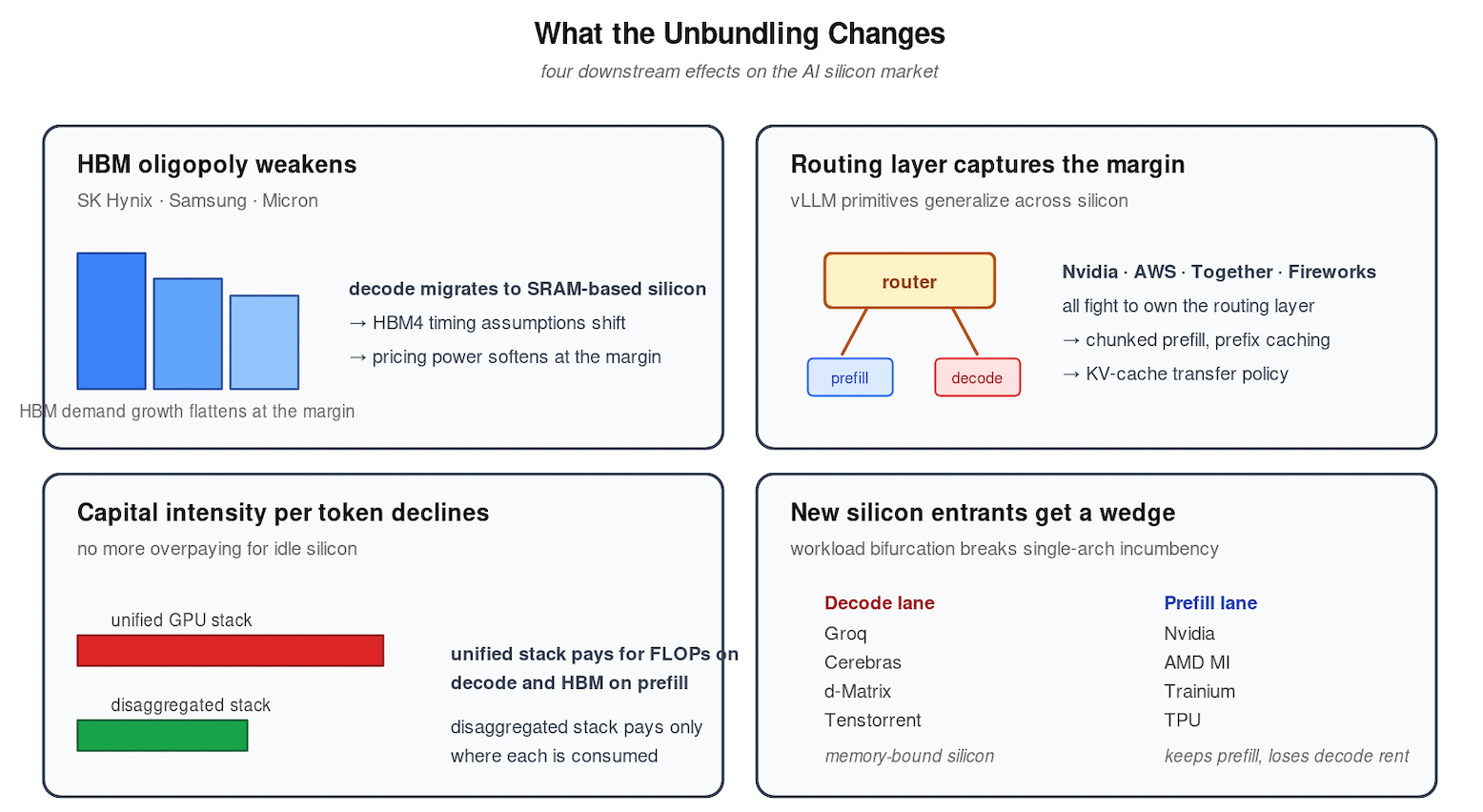
The HBM oligopoly’s pricing power weakens at the margin. Decode migration off HBM-dependent silicon slows HBM3e demand growth and reshapes HBM4 timing assumptions.
Inference orchestration becomes a control point. The router that decides which phase runs on which silicon — and tunes batch size, chunk size, and KV-cache transfer policy — is the new margin layer. The technical primitives already exist inside vLLM (chunked prefill, prefix caching, KV-cache offloading). The step from “interleave on one GPU” to “route across heterogeneous accelerators” is small. Nvidia (Dynamo, post-Groq), AWS (Bedrock + Trainium + Cerebras), and independent inference platforms (Together, Fireworks, Baseten) will fight for it.
Capital intensity per token declines. A unified GPU stack overpays for FLOPs on decode and overpays for HBM on prefill. The disaggregated stack pays for each only where it is consumed.
New silicon entrants get a clearer wedge. The single-architecture incumbency advantage erodes when the workload itself is two distinct workloads. Memory-bound silicon (Groq, Cerebras, d-Matrix, Tenstorrent) gets a defensible decode lane. Compute-bound silicon keeps prefill but loses its decode rent.
Bottom Line
Prefill and decode are different physics. Different roofline regimes. Different cost structures. Different margin profiles. Inside a single GPU, scheduler-level disaggregation already pays. Across silicon, Nvidia/Groq and Cerebras/AWS are the same trade — pair a compute engine with a memory engine, route the workload, capture the spread.
The single-accelerator era is over. The routing layer owns the margin.