

The Next Verifiable RL Domain Is Security
The picks-and-shovels layer for AI cyber is the RL environment. Whoever industrializes it first wins the next decade of attacker-defender economics.

Reinforcement learning produces superhuman agents wherever the reward signal is cheap, fast, and verifiable. Coding and math fell first: SWE-bench scores moved from single digits in 2023 to 60%+ in 2025; AIME accuracy went from ~15% to 95%+ over the same window. The driver was the same in both domains — a programmatically checkable outcome (tests pass, proof verifies) that could be generated at scale.
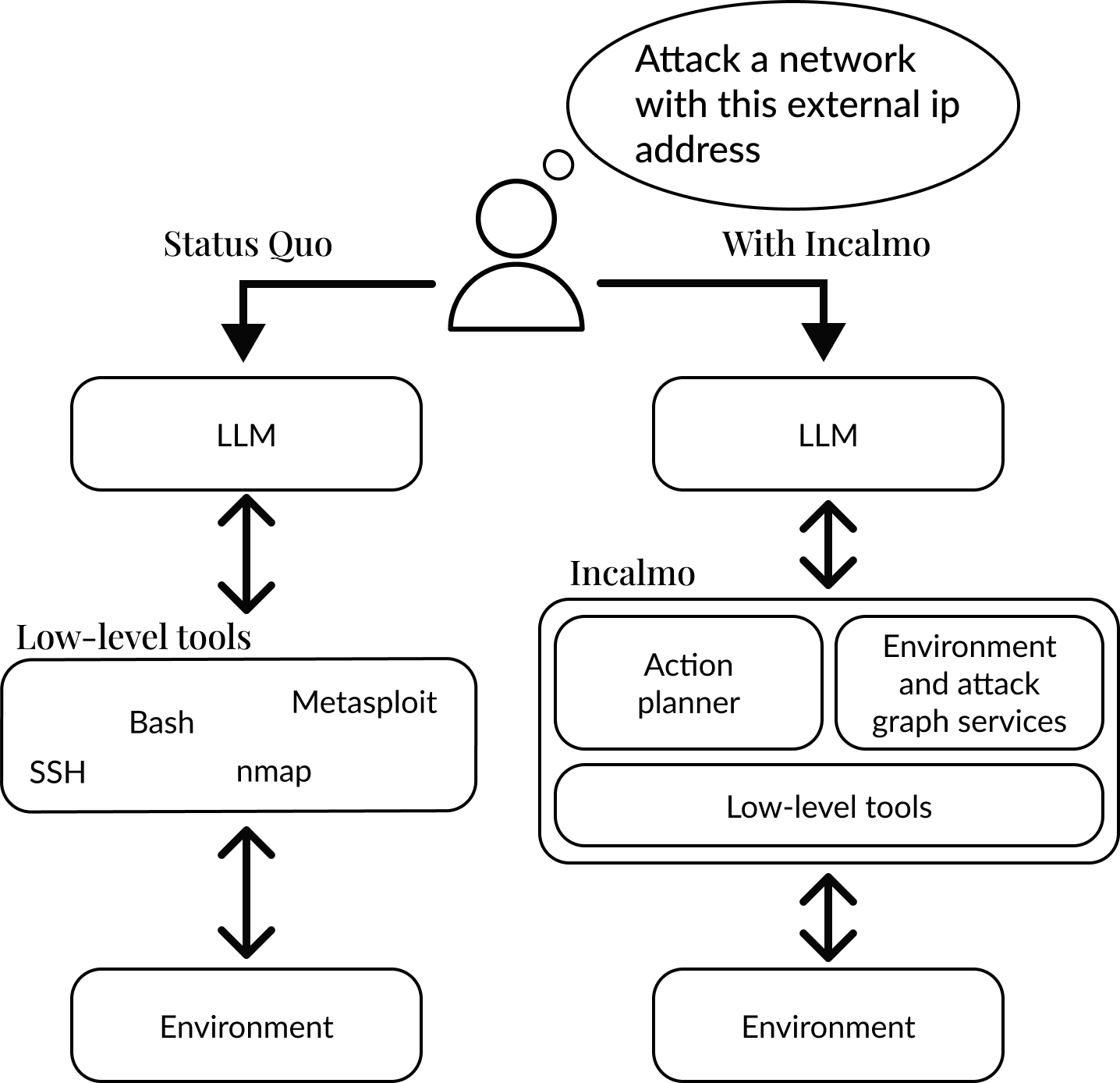
Security has the same structure. Did the exploit land? Did the agent reach the flag? Did the defender detect and contain it before exfiltration? Binary, automatically verifiable, and infinitely repeatable in a sandbox. The missing ingredient has been the environment infrastructure to produce these signals at scale. That is now being built. Anthropic is already publishing research with companies like Incalmo on breaching systems with AI.

The Drone Parallel
Cost asymmetry has become the defining strategic problem of kinetic warfare:

A $20K munition forcing a $4M interceptor breaks defense economics. The industrial response — Anduril, Epirus, directed energy programs at the primes — is fundamentally a race to push defense cost-per-engagement toward $1–$10 (lasers, microwave, EW).
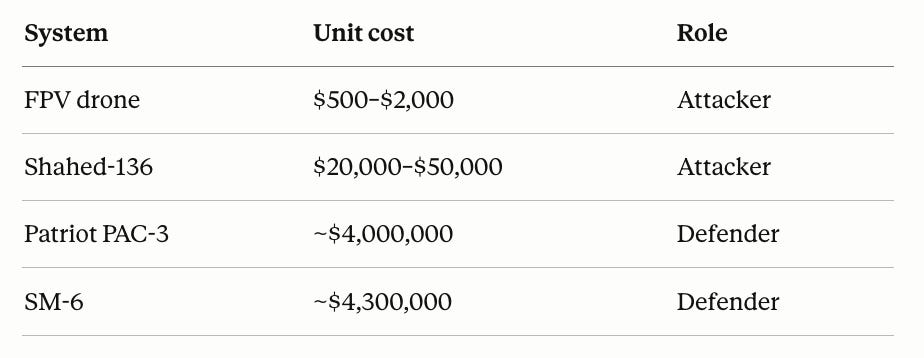
Cyber is the same problem with worse asymmetry:
AI attacker compute per engagement: $10–$100
Average enterprise security spend: $5M–$50M+ annually
Average breach cost (IBM 2024): $4.88M
Open-source attacker tooling: $0
How do you stop a $10 autonomous exploit without spending $1M per incident? That is the question the next decade of security spend will be organized around.
What Is Different From Drones
Three things make the cyber version harder:
Software has no kinetic bottleneck. Drone attackers need factories. Cyber attackers need a checkpoint and GPUs.
The defense surface is unbounded. Airspace is finite. Modern enterprise attack surface — identities, SaaS, supply chain, model weights, agent tools — is not.
Attribution is weak. Deterrence-by-punishment underwrites kinetic doctrine. It does not apply in cyber.
The implication: the AI defender must be cheaper, faster, and more autonomous than its kinetic equivalent. A human SOC analyst at $200K fully loaded handling 10–20 investigations per day cannot match an attacker running thousands of episodes per hour.
The Training Bottleneck
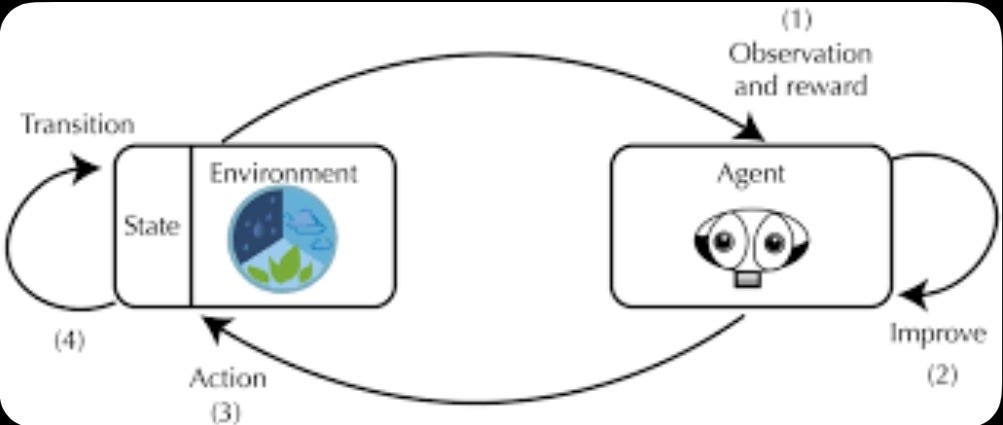
You cannot RL-train an agent in production. The analog to a unit test or a proof checker is a sandboxed environment with realistic topology, verifiable objectives, adversarial structure, and parallel scale — thousands of episodes per hour. This is the picks-and-shovels layer for security RL. Whoever supplies the environment captures economics from every downstream model.
Implications
Offensive AI commoditizes faster. Assume open-source parity with commercial tooling within 24 months.
Defensive AI consolidates around whoever owns the best environment. That is where the training data lives.
Legacy SIEM/SOAR is structurally mispriced. A 6 figure/year log platform cannot defend against a $10/hour autonomous attacker. Expect a generational vendor reset within 36 months.
Capital flows in order: environments first, defender models second, deployed agents third — mirroring how drone-defense capital rotated from platforms to payloads to fire control.
Summary
Verifiable-reward RL fell math and code in under 24 months. Security has the same reward structure and a larger economic surface. The drone analogy gives the cost curve; the lesson is that whoever industrializes the reward environment first determines who wins the next decade of the attacker-defender game.
Extremely well written and insightful. The comparison with drone economics is spot on and obviously timely.