

The Structural Bottlenecks in the AI Data Center Supply Chain
Compute supply is set by the whole system, not any single component—where bottlenecks in power, packaging, memory, and networking dictate who captures value.

AI inference workloads require 10,000–1,000,000x the compute of a comparable SaaS transaction, depending on model size and task complexity. This shifts value from software toward compute supply chain owners, compressing gross margins at the application layer. Hyperscalers are spending a combined $700B in 2025–2026 capex — roughly 5x the 2022 baseline — because AI-native workflows represent a step-function increase in compute demand over the SaaS baseline they replace.
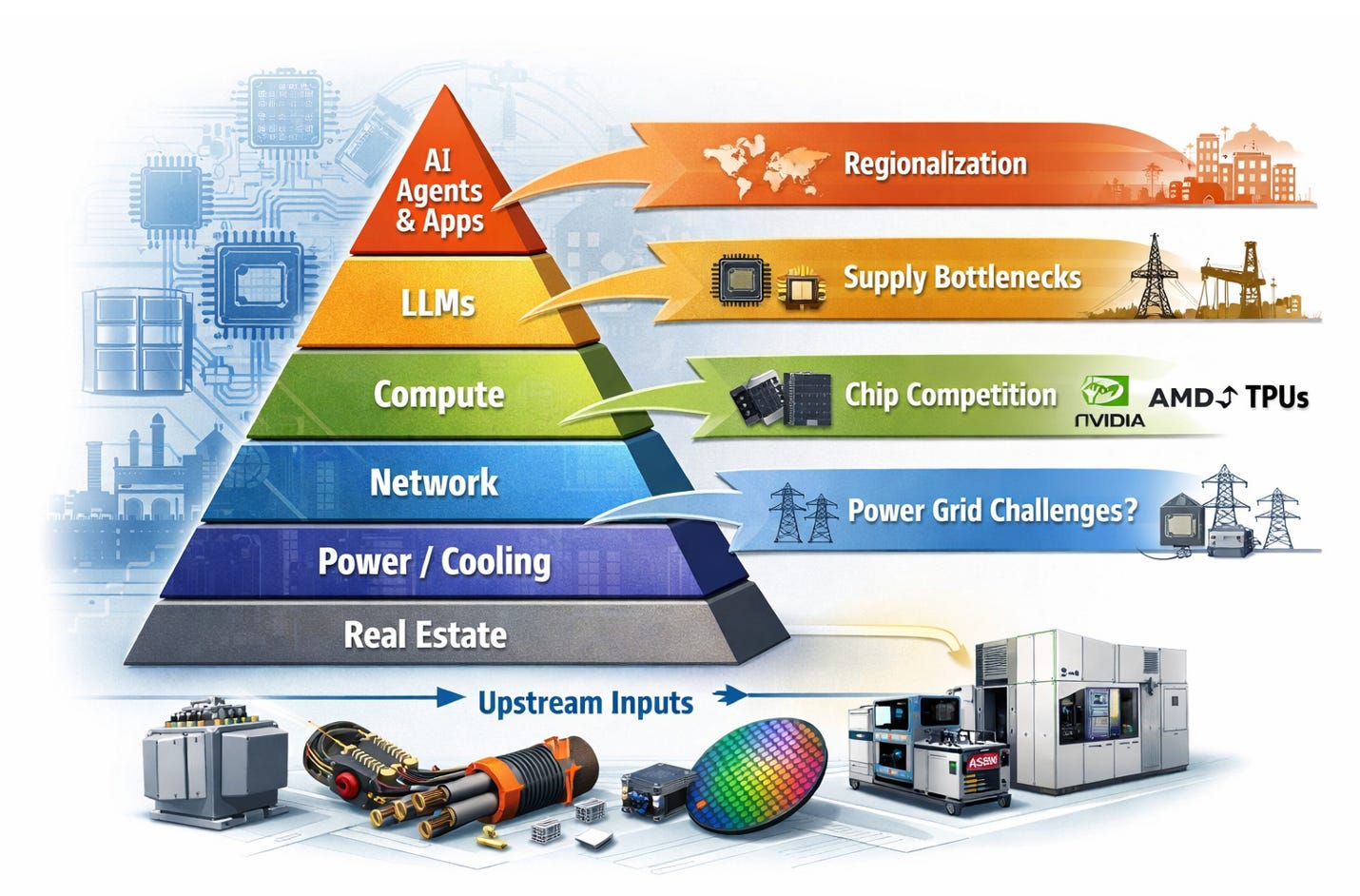
What determines the actual production of compute-hours? Most discussion focuses on GPUs. But compute-hours are the output of a system with 7–10 interdependent inputs. Each layer is tightly coupled. When constraints stack, supply elasticity collapses.
Key Trends
Nvidia sells full racks, not GPUs. The unit of compute has shifted from chip to rack. GPU count per rack moves from 72 (Hopper) to 576 (Rubin) — 8x in one generation. Rack-level memory is scaling faster: GB200 NVL72 at 30 TB HBM3e, GB300 NVL72 at 40 TB, Vera Rubin NVL144 projected at 100 TB — roughly 3x within the Blackwell generation alone. Per-GPU memory follows the same trajectory: H100 at 80 GB HBM3, B200 at 192 GB HBM3e (2.4x in a single generation), with HBM4 at Rubin pushing further. Every layer of the stack — power, cooling, interconnect, cabling — gets redrawn when the reference architecture moves.
The interconnect question is unresolved. Scale-up (within rack) and scale-out (rack-to-rack, pod-to-pod) have diverging physical layer requirements. Copper and AECs remain competitive at short reach on cost, reliability, and power. Co-packaged optics improves bandwidth density at distance but carries a power premium over copper today. Where the crossover lands determines which interconnect vendors are structural winners.
Memory is a primary constraint. HBM capacity growth is outpaced by model size and context length expansion. Supply is concentrated across three vendors. HBM accounts for roughly 35–40% of AI server bill-of-materials cost, making memory economics a system-level concern, not a component-level one. Any component that reduces memory pressure — near-memory compute, KV cache compression, sparsity — commands disproportionate ROI in the current supply environment. Per-GPU memory progression: H100 (80 GB) → H200 (141 GB, 1.76x) → B200 (192 GB, 1.4x) → Rubin (288 GB est., 1.5x) — roughly 3.6x over six years.
ASICs are in production, not pilot. Google TPUs and AWS Trainium are at scale. Each requires its own compiler toolchain, interconnect topology, and systems integration. The infrastructure stack can no longer be optimized solely around NVLink/NVSwitch.
Energy is an architectural input, not an operational variable. Rack power density has increased from 10–20 kW (CPU era) to 100–130 kW (GB200), with 200+ kW expected at Rubin densities. Optical transceivers consume roughly 2–3x more power per port than copper at equivalent bandwidth — a material tax at 200+ kW/rack. Decisions that appear to be performance tradeoffs are simultaneously energy budget decisions.
Scale-Up Clusters: Why NVIDIA’s Architecture Wins on Durability and Efficiency
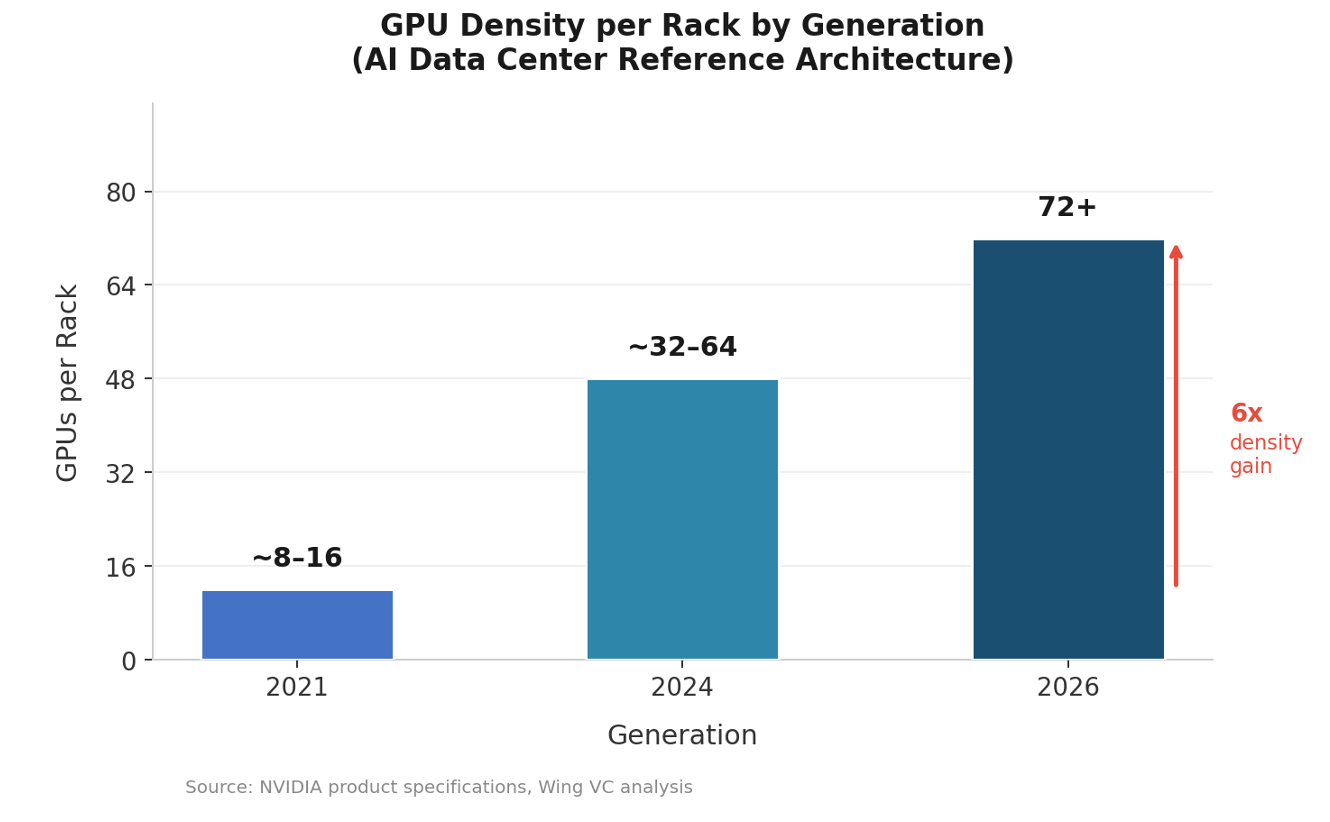
GPU density per rack has increased roughly 6x from 2021 to 2026 — from 8–16 GPUs per rack to 72+ in the GB200 NVL72, with the NVL144 and NVL256 roadmap targeting continued doubling. This is a systematic architectural shift, not incremental improvement, and it compounds into durable cost and performance advantages.
The Communication Hierarchy: Why Staying In-Rack Is Structurally Cheaper
Cluster communication cost and latency increase sharply as data crosses physical boundaries. The hierarchy, from lowest to highest cost: (1) in-package and NVLink — sub-microsecond latency at 900 GB/s per GPU in the NVL72; (2) rack-scale interconnect — copper-viable but bandwidth-constrained; (3) cross-rack networking — where latency and cost increase nonlinearly. Every inter-rack hop adds microseconds of latency, consumes optical transceiver power (~2–3x per port versus copper at equivalent bandwidth), and introduces fabric congestion risk. Larger in-rack clusters reduce total communication overhead and deliver lower cost-per-token at scale. The math is structural.
NVIDIA’s Structural Advantage: NVLink as a Moat
NVIDIA is the only vendor currently able to deliver a validated, high-density scale-up cluster at rack scale. The NVL72 ships with 900 GB/s GPU-to-GPU bandwidth via NVLink 4, 30 TB of pooled HBM3e memory, and a single-rack power envelope of ~120 kW within NVIDIA's reference architecture. Competitors must traverse PCIe or Ethernet for equivalent multi-GPU communication — 10–20x lower bandwidth per link than NVLink at equivalent rack density. AMD's Infinity Fabric does not scale beyond 8 GPUs without external switching. Google TPUs and Amazon Trainium are ASIC-scale designs without a comparable proprietary high-bandwidth fabric. NVIDIA's inference cost-per-token advantage at 72-GPU density is structural, not a function of current market position.
Efficiency and Durability Implications
First, eliminating inter-rack hops removes optical transceiver power overhead — material when each 800G optical port draws ~10 W versus ~4 W for equivalent copper.
Second, unified HBM memory pools across 72 GPUs allow workloads to avoid KV cache eviction and model sharding penalties that dominate inference latency at smaller cluster sizes.
Third, higher GPU utilization: the GB200 NVL72 sustains higher model flops utilization on large-batch inference workloads than disaggregated clusters of equivalent total GPU count, because all-reduce operations stay within NVLink rather than crossing fabric.
NVLink all-reduce is 4–8x faster than InfiniBand at equivalent cluster size. As inference workloads scale, the performance gap between NVLink-based and non-NVLink architectures widens. The NVL72 roadmap to NVL144 and NVL256 compounds CUDA ecosystem lock-in with physical architecture lock-in.
Investment note: The industry-wide push toward larger scale-up clusters requires exponentially more cables, higher signal integrity requirements, and greater pressure on copper and optical interconnect at short reach as GPU density per rack increases. This trend is net positive for high-bandwidth interconnect specialists addressing signal integrity challenges at 72+ GPU densities — including Attotude.
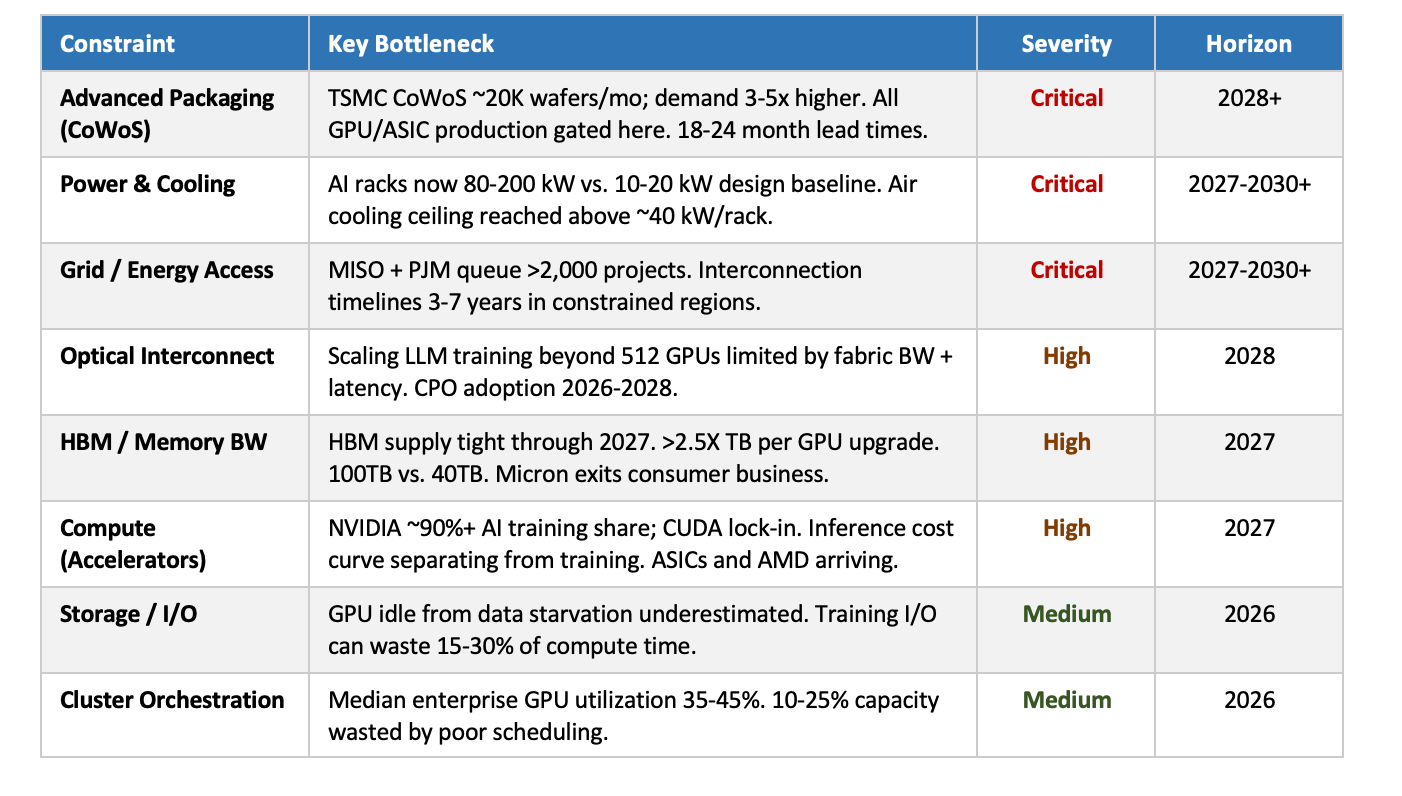
Where we are today: massive shortages
The underappreciated risk is that a single bottleneck shuts down the entire system. Current materials under extended constraint: copper, aluminum, indium phosphide; power and electrical equipment; laser components; HBM memory; CoWoS packaging capacity at TSMC. Most are booked out 2+ years. Removing one constraint shifts pressure to the next layer — which is why aggregate GPU supply numbers mask the actual delivery reality.

Structural Constraints — Severity, Bottleneck, and Timeline
Core Thesis
The AI infrastructure stack is not just GPU-constrained — it is system-constrained. Removing one bottleneck shifts pressure to the next. Companies that own chokepoints in this stack — advanced packaging, power delivery, optical interconnect, laser components — hold structural leverage analogous to what ASML holds in semiconductor manufacturing.
Four structural forces are reshaping the stack:
Slow-scaling inputs versus fast-scaling demand. Power generation and high-voltage transmission scale on decade timelines. Compute demand scales on 12–18 month cycles. The gap between these curves is the primary investment surface.
Layer-specific bottlenecks force architectural transitions. When a layer hits a physical limit, the supplier map is redrawn. Copper-to-optical in networking is the live example — CPO share expected to rise from near zero to ~36% of addressable ports.

Silicon is fragmenting. AMD, Google TPUs, Amazon Trainium, and OpenAI custom silicon are eroding NVIDIA’s training monopoly. Value migrates toward scarcer upstream inputs when the compute layer commoditizes. NVIDIA remains the only vendor selling the full rack.
Compute is geography-bound. Power availability, transmission access, and regulatory environment are making AI infrastructure decisions location-specific. Texas has more planned data center capacity than any other state. Site selection is now a primary capital allocation decision, not a secondary one.
Recent M&A
The M&A velocity in optical and interconnect is the strongest forward indicator of where supply constraints are most acute.
Groq —> Nvidia $20B, inference chip
Celestial AI → Marvell ~$3.25B
Optical connectivity | Enfabrica → NVIDIA ~$900M
Ayar Labs ($1B+ Series D) — likely next optical exit
$4.15B in optical-adjacent exits in under 12 months. NVIDIA’s $2B strategic investment in Lumentum and Coherent (March 2026) is a direct acknowledgment that laser supply — specifically electro-absorption modulated lasers inside every 800G and 1.6T transceiver — is a compute constraint. Lumentum controls 50–60% of global EML supply.
Public Market Exposure — Where to Express Today’s Needs
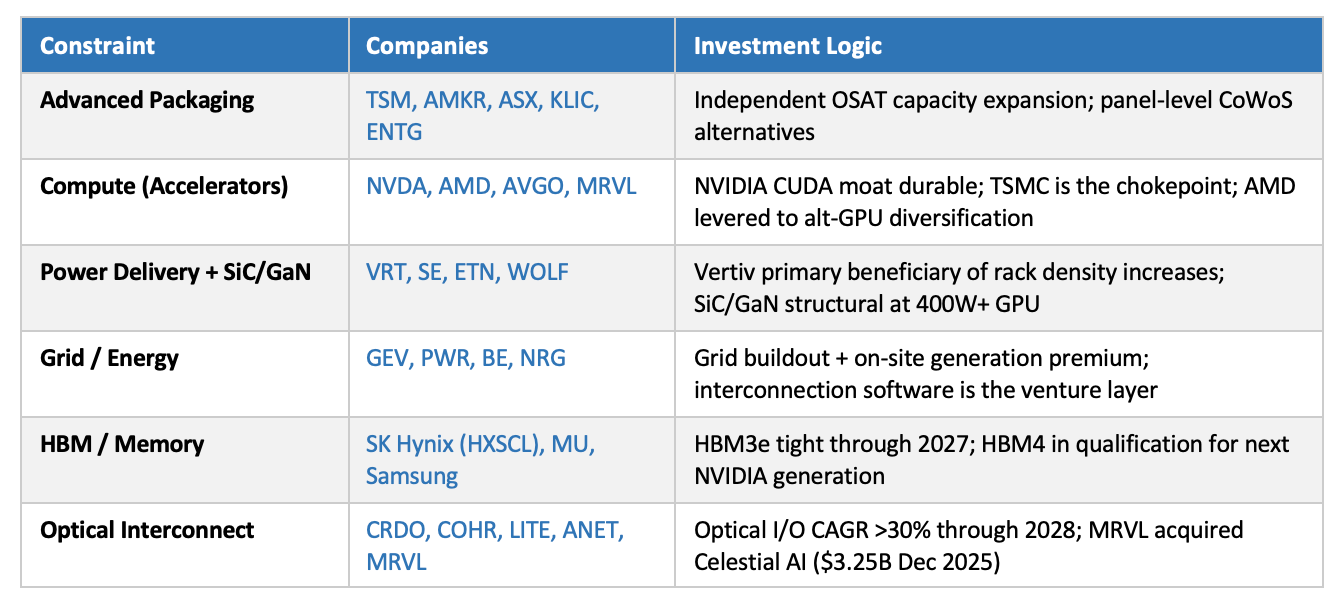
Five Key Structural Observations
1. Optical fabric is the highest M&A velocity category.
$4.15B in exits in <12 months. Ayar Labs ($1B+ Series D) is the next likely event. The laser layer is the least visible and most acute constraint within optical: electro-absorption modulated lasers (EMLs), the component inside every 800G and 1.6T transceiver that converts electrical signals to light, are undershipping demand by ~30%, with all capacity locked under long-term agreements and incremental units priced at a premium. Lumentum controls 50–60% of global EML supply; Nvidia’s $2B strategic investment in Lumentum and Coherent (March 2026) is a direct acknowledgment that laser supply is a compute constraint.
2. CoWoS is the rate-limiting step for everything upstream.
GPU supply, custom ASICs, and AI accelerators all flow through TSMC CoWoS at ~20K wafers/month. Independent packaging alternatives and panel-level interposers are the highest-leverage supply chain investment in this cycle.
3. Power is a software opportunity.
Grid interconnection, energy OS (1,700+ utilities, multiple types of power <> data center), and workload-aware power management are software wedges into a hardware-constrained market. Vertiv captures the hardware layer; the software orchestration layer is open.
4. Inference economics are separating from training economics.
Training is NVIDIA’s domain. Inference is not. Cost/token, memory efficiency, and latency matter, and they are not optimized by training-oriented GPU architectures. Critically, LLM inference, image generation (fal.ai, Flux), and video generation (Runway, Sora) have distinct compute profiles — model-type-specific accelerators may be a more tractable bet than general inference silicon.
5. NVIDIA is vertically integrating; build around it.
Enfabrica (fabric), Mellanox (networking), Cumulus (switching). Companies must build on technology NVIDIA does not control: Ethernet AI fabric, RISC-V, photonics, advanced packaging. Partner, don’t compete.
the bottleneck shift from chips to power to packaging is the one that keeps getting confirmed across the newsletters we track too