

What Does Broadcom Do?
Broadcom booked $30 billion in AI chip orders in a single quarter — against $10.8 billion shipped. This is what they're actually building, and why the backlog keeps growing.

Broadcom (AVGO) does not make products consumers recognize. It does not have a brand that appears in press releases or keynote slides. What it has is position — deep inside the infrastructure stack that every major technology platform runs on. The WiFi silicon in your home router is almost certainly Broadcom. The Ethernet switch at the core of Google’s AI training cluster is almost certainly Broadcom. The custom accelerator chip that runs Meta’s recommendation inference at scale was co-designed by Broadcom. Q3 FY2026 guidance implies an annualized revenue run rate of approximately $118 billion, up 84% year-over-year — which puts it alongside TSMC, NVIDIA, Samsung, and Intel as one of the five largest semiconductor companies on earth. Its AI semiconductor segment alone is tracking toward $64 billion annualized on Q3 guidance, growing 200% year-over-year. That number, as a standalone business, would rank in the global top 10 by semiconductor revenue.
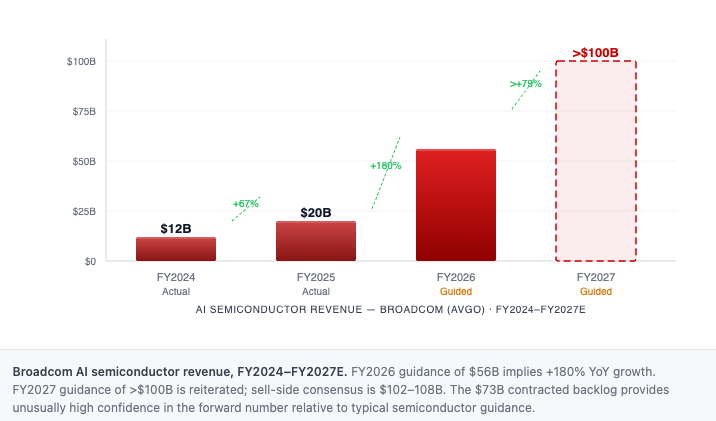
In Q2 FY2026 alone, Broadcom booked more than $30 billion in AI semiconductor orders against $10.8 billion in shipments — a 3:1 book-to-ship ratio that means the backlog is growing nearly three times faster than revenue. The company carries a $73 billion contracted AI chip backlog ($53 billion of which is custom accelerators) and is guiding to more than $100 billion in AI semiconductor revenue for FY2027. At Bloomberg Tech on June 5, Hock Tan described the demand environment simply: “insatiable growth.” We first covered Broadcom’s XPU strategy in depth in 2024 — what has changed since is the scale. This piece is the full update.
From HP’s Lab to AI Infrastructure Backbone: M&A and the “Hock Tan Playbook”
Broadcom’s lineage starts in 1961, when Hewlett-Packard founded a semiconductor laboratory in Palo Alto to supply components for its own test and measurement equipment. That division spun out as part of Agilent Technologies in 1999, then went private in 2005 when KKR and Silver Lake bought Agilent’s Semiconductor Products Group for $2.66 billion — 6,500 employees, manufacturing in Singapore, leading positions in wireless filters, fiber optics, and industrial motion control. Hock Tan, who had just sold Integrated Circuit Systems to IDT, was installed as CEO in 2006.
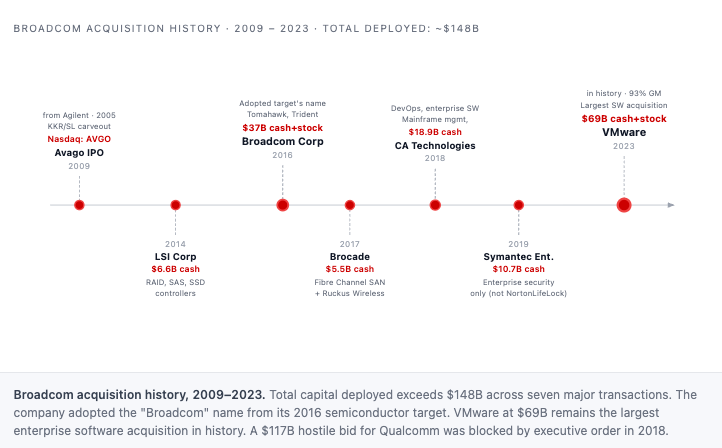
Avago went public on Nasdaq in August 2009 (ticker: AVGO) at roughly a $2.5 billion market cap. Over the following 14 years, Tan ran six major acquisitions that together created the company carrying the Broadcom name today:
LSI Corporation ($6.6B, 2013)
Broadcom Corporation ($37B, 2016, with Tan adopting the acquired company’s name)
Brocade ($5.5B, 2017)
CA Technologies ($18.9B, 2018)
Symantec Enterprise ($10.7B, 2019)
VMware ($69B, November 2023).
Total acquisition capital deployed: over $140 billion. A separate $117 billion hostile bid for Qualcomm was blocked by President Trump in March 2018 on national security grounds.
The logic underlying each deal is consistent — what observers call the “Hock Tan playbook.” Find franchise assets with dominant market share and customers that cannot switch without 12–24 months of re-certification. After close: cut lower-priority R&D, eliminate duplicative sales and marketing overhead, run each of 24 divisions as a fully independent P&L.
The approach generated the loudest backlash of Tan’s career when applied to VMware — some enterprise customers reported license cost increases of 150% to 1,000% as Broadcom collapsed 8,000+ SKUs into four subscription bundles. The playbook worked anyway: VMware software now runs at 93% gross margin. What Tan said at Bloomberg Tech on June 5, 2026 is the most important thing to understand about where Broadcom is today: he has stopped prioritizing M&A, because AI organic growth — $30B booked in a single quarter — is better than any deal he can buy. That is a different kind of statement from a CEO who built a $1.7 trillion company almost entirely through acquisitions.
Financial Overview
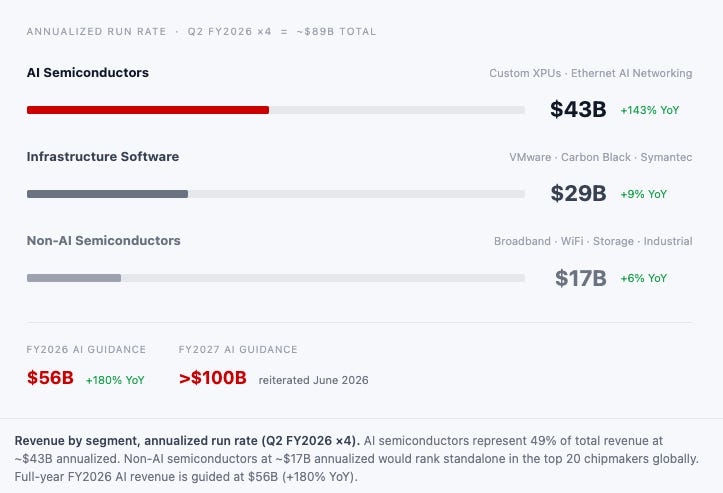
Broadcom’s FY2025 non-GAAP gross margin was 78.6% on $63.9B of revenue — $43.0B adjusted EBITDA (67.3% margin), $26.9B free cash flow. Software-company margins on chip revenue, held by 18,000 patents and $11.0B of annual R&D across 24 product divisions. Q2 FY2026 reset the baseline: total revenue $22.2B (+48% YoY), AI semiconductor revenue $10.8B (+143% YoY), EBITDA $15.2B at 69% — both records. Annualized AI run rate: $43.2B. Q3 FY2026 guidance accelerates to $29.4B total (+84% YoY) and $16.0B AI semiconductor (+200% YoY) — a $64B annualized AI run rate and $117.6B total annualized. Gross margin guides to ~74%, down from 78.6%, entirely mix-driven as higher-volume AI silicon displaces legacy products — not structural compression. $30B in Q2 bookings against $10.8B shipped: demand is running 3:1 ahead of supply. The constraint is capacity, not orders.
Custom Silicon: XPUs for Hyperscalers
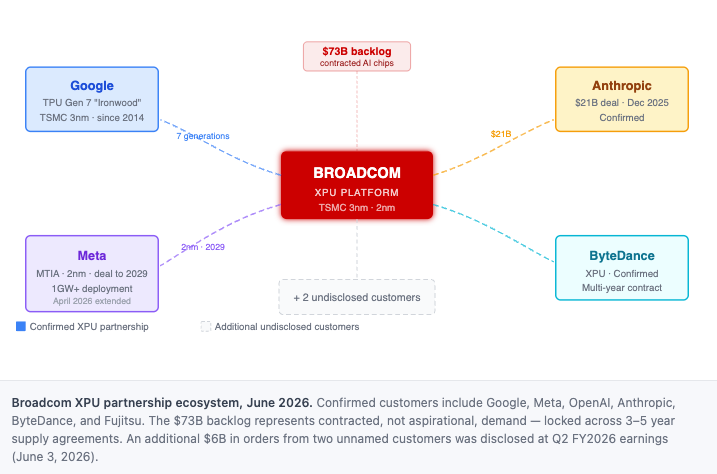
The most valuable thing Broadcom does right now is also one of the least visible to outsiders. It co-designs custom AI accelerators — internally called XPUs — for the largest compute buyers in the world. The process is collaborative and long: Broadcom embeds engineers with a customer’s ML infrastructure team, sometimes for years, and produces a chip tuned to that customer’s specific model architecture, memory bandwidth requirements, and power envelope. The resulting silicon typically outperforms a general-purpose NVIDIA GPU on the target workload by a meaningful margin and at 30–50% lower total cost of ownership, because it is not carrying the overhead of generality. The customer gets a better chip for their specific task. Broadcom gets a multi-year supply contract, premium ASP for the design work, and a relationship that is structurally difficult to exit — because migrating a chip design to a different design house takes 2–3 years and a different foundry partnership can take longer. The company has confirmed six active XPU customers: Google, Meta, OpenAI, Anthropic, ByteDance, and Fujitsu — all on multi-year contracts for what management is describing as “multi-gigawatt” compute deployments.

Google is the longest-standing relationship — seven generations of co-designed TPUs since 2014. The 7th-generation “Ironwood” TPU, built on TSMC 3nm with a dual-chiplet design co-developed with both Broadcom and MediaTek, delivers 4,614 FP8 TFLOPS with 192 GB HBM3E. Ironwood deploys in 9,216-chip pods delivering 42.5 FP8 exaflops of aggregate compute at a TCO Google claims is 44% below an equivalent NVIDIA GB200 server. Meta extended its MTIA partnership in April 2026 through 2029, targeting the industry’s first 2nm AI compute accelerator — integrating four N2 compute dies, one I/O die, and six HBM stacks in a single CoWoS-S package. Meta has publicly committed to “more than 1 gigawatt of custom silicon to start, then multiple gigawatts over time,” implying $30–50B+ of procurement over the contract period at current silicon ASPs.

OpenAI signed a multi-year co-design agreement with Broadcom in October 2025, valued at approximately $10 billion, to produce its “Titan” XPU — a chip internally targeting a 90% reduction in inference cost versus general-purpose GPUs. Titan is fabricated on TSMC N3 with HBM3E, led by a 40-person in-house chip team under VP of Hardware Richard Ho (ex-Google). Mass production is targeted for the second half of 2026; a second generation on TSMC’s A16 (1.6nm) node is in planning, paired with Samsung HBM4 under a separate memory supply agreement. The chip is for internal inference use only, not commercial sale. Anthropic was revealed as Broadcom’s previously undisclosed “$10 billion customer” in December 2025. Anthropic has committed to a $21 billion chip relationship with Broadcom while simultaneously deploying up to one million Google TPU v7 Ironwood units — the largest deal in Google Cloud history — reflecting a multi-vendor compute strategy as its annualized revenue has grown from ~$9 billion in late 2025 to over $30 billion in 2026.
The $73 billion AI backlog — equivalent to roughly 1.5 years of total company revenue — reflects contracted demand across these six design wins. XPU design cycles typically lock in 3–5 year supply commitments, as migrating chip designs between foundry partners and design houses is a 2–3 year engineering project. Broadcom disclosed at Q2 FY2026 earnings that it has booked an additional $6 billion in AI orders from two new customers not previously included in backlog guidance, suggesting the disclosed six-customer figure may expand further by year-end.
The packaging technology underpinning the next generation of XPUs is called 3.5D XDSiP (Extended Die System-in-Package). A single die is constrained by the lithography reticle limit — roughly 800mm². XDSiP breaks that ceiling by bonding multiple compute dies face-to-face via TSMC’s SoIC process, combined with 2.5D CoWoS interposer integration — yielding a single package with up to 6,000mm² of silicon and 12 HBM stacks. The first production XDSiP product shipped in February 2026: four compute dies, one I/O die, six HBM stacks. More than five products follow. This capability is co-developed with TSMC using bonding processes unavailable through any alternative foundry. A competitor cannot replicate it by hiring packaging engineers — it requires years of joint process development on the same nodes. No one catches up in a single tape-out cycle.

On June 9, 2026, the AI XPV Platform was announced — a $35 billion first tranche led by Apollo Global with Blackstone participation to build hyperscale AI data centers anchored by Broadcom-designed XPUs, targeting 20 gigawatts of capacity by 2028 across Fluidstack-operated sites. Anthropic is the anchor tenant, deploying a 1 GW XPU cluster starting mid-2026. What makes this announcement significant is not the dollar figure — it is what the structure reveals about how the AI capital stack is vertically integrating. Anthropic co-designed its chips with Broadcom. Those chips will run in data centers financed by Apollo and Blackstone. The data centers will be operated by Fluidstack. The silicon is fabricated by TSMC. Broadcom sits at the design layer connecting all of it. A foundation model lab that co-designs its inference chip with Broadcom, then deploys it in a privately financed data center built around that chip, has made a 5–7 year infrastructure commitment. That is not a vendor relationship. It is a structural dependency — and it runs in Broadcom’s favor at every layer.
The Competitive Landscape: Marvell, MediaTek, and NVIDIA

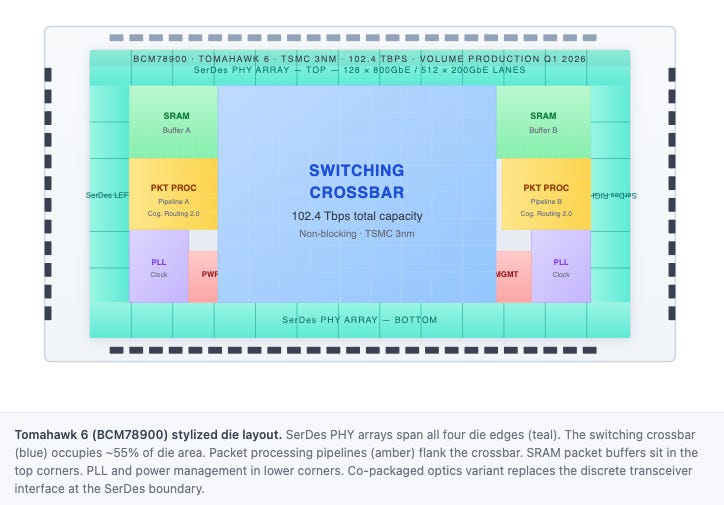
Broadcom and Marvell together control an estimated 95% of the custom AI ASIC co-design market. Marvell is the clear number-two — it co-designs Amazon Trainium and Microsoft Maia, expects AI data center revenue of approximately $11 billion in FY2026 (up from ~$4B the prior year), and had more than 50 new design opportunities across 10+ customers as of early 2026. MediaTek is the less obvious threat: it co-designed Google’s TPU v7 Ironwood alongside Broadcom, targets $2B in AI ASIC revenue for 2026, and is pushing 448G SerDes development ahead of any competitor’s current 224G production. The more direct risk from MediaTek is not a frontal attack — it is Google continuing to diversify its silicon partners across future TPU generations, quietly eroding Broadcom’s share of the most important single XPU relationship. On Ethernet switching, Marvell’s Teralynx T100 — 102.4 Tbps, TSMC 3nm — began sampling in Q2 2026, with volume production targeted mid-2027. Broadcom is already shipping Tomahawk 6 at volume. The lead is 12–18 months on the exact refresh cycle that is happening now.
The sharper version of the bear case is internalization: the possibility that hyperscalers build chip design capability until they no longer need a co-design partner. Amazon has already done this — Trainium runs through Annapurna Labs, an internal design house acquired in 2015. Microsoft’s Maia 200 (140 billion transistors, TSMC 3nm, 216 GB HBM3E) is a fully internal Azure design. Google has the deepest internal chip team of any hyperscaler. The honest read: Google, Amazon, and Microsoft use Broadcom not because they lack chip designers — they have thousands — but because Broadcom has SerDes IP, 3.5D advanced packaging expertise, and production ramp credibility that takes years to build internally. Each XPU generation starts planning 3–5 years before tape-out. The $73B backlog is decisions already made. Whatever a customer decides to do differently in 2030 does not move revenue in the window between now and then.
NVIDIA is the most structurally interesting threat — not as a co-design competitor but as a direct attack on the economic rationale for custom silicon itself. At SC25 in November 2025, NVIDIA introduced Vera Rubin with a public claim of 90% lower AI running costs versus Blackwell. If that holds in production, it narrows the TCO gap that makes a custom XPU worth a 3-year co-design commitment. The ASIC value proposition has historically been 30–50% better TCO on a target workload. NVIDIA is explicitly targeting that number. Analysts project Broadcom will hold approximately 60% of the custom AI processor market by 2027 — but that projection is partly conditional on Vera Rubin underdelivering at scale, as Blackwell underdelivered on its initial dense-deployment training throughput claims. The structural counter: inference workloads are more fixed and more amenable to hardware specialization than training. The inference-focused ASIC pipeline — OpenAI’s Titan chip, Anthropic’s contracted chips — was not commissioned because anyone expected Vera Rubin to fail. It was commissioned because inference economics favor specialization independent of what NVIDIA’s next GPU delivers.
Ethernet Networking Silicon: The Open Standard Play for AI
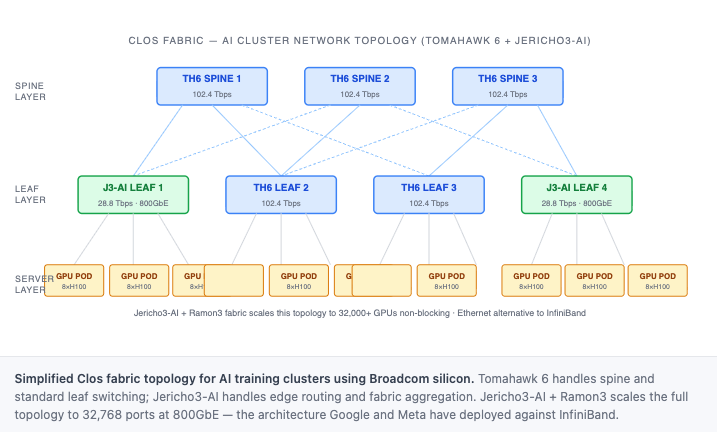
A 100,000-GPU cluster on InfiniBand requires NVIDIA’s Quantum switches, NDR/XDR cables, and ConnectX NICs at every layer — a single-vendor supply chain with a single vendor’s pricing power. Broadcom’s counter-positioning is simple: open. Any OEM chassis, any standards-compliant transceiver, any RDMA-capable NIC. Broadcom supplies the dominant switch ASIC at the center and takes no position on what surrounds it. The market validation is visible at every level: Google’s Ironwood TPU clusters run Ethernet. Meta’s entire RoCE fabric is Ethernet. Microsoft Azure has diversified newer GPU cluster builds away from InfiniBand. And Arista Networks — the dominant hyperscale and enterprise Ethernet switch vendor — builds its AI spine products almost entirely on Broadcom Tomahawk ASICs; Arista’s revenue grew 27% YoY in Q1 FY2026, driven largely by AI cluster switching deployments that run on Broadcom silicon. Each deployment reinforces the reference architecture for the enterprise builds that follow. Broadcom holds an estimated 60–70% merchant switch ASIC share at the center of that architecture, built over a decade against challengers that kept arriving and failing (Innovium, Pensando, Intel Barefoot). No competitor produces 106 Gbps PAM4 SerDes at production yield without years of investment. That gap does not close in a product cycle.






Broadband and Wireless: The Installed-Base Business
The $4.2B non-AI semiconductor segment annualizes at roughly $17 billion — a business that would be a top-20 chipmaker on its own, but is structurally overshadowed by the AI growth rates surrounding it. It is not a growth business. It is a franchise business: high share, high switching costs, low competitive risk. Changing the SoC in a cable modem gateway requires re-certifying with every broadband operator, a process that takes 18–24 months. Nobody does it casually.
Broadcom’s BCM33xx DOCSIS 4.0 SoCs are the primary silicon in the majority of residential and SOHO gateways globally — Comcast, Charter, and Liberty Global are all in active DOCSIS 4.0 deployment. Gateway SoC ASP is $15–25 across a 200M+ global subscriber base; thin per unit, stable in aggregate. Fiber/PON follows the same pattern: XGS-PON chipsets for 10G passive optical networks ship into Tier-1 telco fiber-to-home deployments across North America, Europe, and Asia Pacific. On WiFi, Broadcom and Qualcomm hold an estimated 80% combined share of merchant access-point silicon; second-generation WiFi 7 chips entered volume production in 2026 with 3-link Multi-Link Operation reducing latency ~50% versus prior-generation implementations. None of these markets will 4x in two years. All of them will still exist in 10 years, with Broadcom inside them.

Storage Connectivity and Industrial Semiconductors
Storage connectivity is the least glamorous segment in Broadcom’s portfolio — and one of the most strategically useful to understand, because it illustrates how the company thinks about market position more broadly. MegaRAID controllers and SAS host bus adapters are not growing markets. The companies that buy them — enterprise IT departments, financial services firms, healthcare networks — are not accelerating their storage refreshes. But every server rack that has a MegaRAID controller needs a MegaRAID controller when it fails or refreshes, and the qualification cycle to introduce a competing product into that environment is 12–18 months minimum. Broadcom does not need the market to grow. It needs the installed base to persist. It will.
The strategically interesting product in this segment for AI is the PCIe switch (PEX series). As AI server chassis disaggregate — compute, memory, NIC, and storage as separate modules on a shared PCIe fabric — PCIe switching silicon becomes the internal interconnect that determines bandwidth and latency within a chassis. PCIe 6.0, now in qualification at 64 GT/s, doubles per-lane bandwidth versus PCIe 5.0. Broadcom is the dominant PCIe switch supplier across enterprise and hyperscale; this is no longer a storage story, it is an AI server architecture story. The segment contributes an estimated $600–800M per quarter. The Brocade-derived Fibre Channel portfolio serves financial services, healthcare, and government SAN environments — a declining market generating durable replacement revenue through 2027. Quiet, durable, not going anywhere.
Infrastructure Software: VMware and Beyond

Broadcom acquired VMware in November 2023 for $69 billion. The software segment generated $7.2B in Q2 FY2026 (annualized: $29B, +9% YoY) and encompasses VMware’s virtualization and private cloud stack (vSphere, vSAN, NSX, Aria), the Carbon Black security platform, and the Symantec enterprise security portfolio. The Q2 FY2026 gross margin on the software segment came in at 93% — among the highest reported by any business unit of a major diversified technology company. Annual Recurring Revenue is growing at +17% YoY, with the vast majority of VMware’s installed base now migrated from perpetual licensing to subscription bundles under VCF (VMware Cloud Foundation). VCF 9.1, released in 2026, added native support for GPU and heterogeneous compute orchestration, allowing vSphere clusters to directly provision and manage GPU workloads alongside traditional CPU VMs — a direct response to enterprise hybrid AI infrastructure demands. When asked at Bloomberg Tech on June 5 whether generative AI posed a risk to VMware’s software lock-in, Hock Tan was unambiguous: “We are not seeing it.” Enterprise data centers running VMware-managed HCI are adding AI inference workloads as an additive layer, not replacing the underlying virtualization stack. The strategic logic remains what it has always been: VMware’s private cloud stack runs on hyperconverged infrastructure in the same data centers as Broadcom’s networking chips — account control at both the software and silicon layer, across the same Fortune 500 customer base.
Revenue Trajectory and 2027 Outlook
“Customers are coming to us for Opus 4.7, ChatGPT 5.5, Gemini 3.5 — they’re naming the models and contracting compute now. That’s the insatiable growth we’re seeing.”
— Hock Tan, CEO, Bloomberg Technology, June 5, 2026
In FY2024, Broadcom’s AI semiconductor revenue was approximately $12 billion for the full year. In FY2026, the company is guiding to $56 billion — a 4.7× increase in two years. FY2027 guidance, reiterated at Q2 FY2026 earnings on June 3, is in excess of $100 billion. The single most revealing data point in Q2 FY2026 is not the revenue print but what sits behind it: Broadcom disclosed more than $30 billion in new AI orders booked in the quarter against $10.8 billion shipped. A 3:1 book-to-ship ratio means the backlog is expanding nearly three times faster than revenue. Management disclosed an additional $6 billion from two new customers not previously in backlog figures. The $73B number — $53B custom accelerators, the remainder networking — is a floor, and the floor is rising. What Tan described at Bloomberg Tech is the mechanism: hyperscalers are contracting compute capacity against future model versions not yet in production, with 2–3 year lead times baked in. The chip decisions being made today are for models that will run in 2028.
Broadcom’s FY2025 non-GAAP gross margin was 78.6% on $63.9B of revenue — $43.0B adjusted EBITDA (67.3% margin), $26.9B free cash flow. Software-company margins on chip revenue, held by 18,000 patents and $11.0B of annual R&D across 24 product divisions. Q2 FY2026 reset the baseline: total revenue $22.2B (+48% YoY), AI semiconductor revenue $10.8B (+143% YoY), EBITDA $15.2B at 69% — both records. Q3 FY2026 guidance accelerates to $29.4B total (+84% YoY) and $16.0B AI semiconductor (+200% YoY) — a $64B annualized AI run rate and $117.6B total annualized. Gross margin guides to ~74%, down from 78.6%, entirely mix-driven as higher-volume AI silicon displaces legacy products — not structural compression.
At a ~$1.7 trillion market cap as of June 2026, AVGO trades at 14.5× annualized forward revenue and ~25× run-rate FCF — implying a ~4% FCF yield (~$67B annualized FCF, based on ~57% FCF margins from Q2 non-GAAP operating data applied to Q3 guidance). At 4%, the yield is defensible for a business with 18,000 patents, 93% software gross margins, and a $73B contracted backlog — but it assumes that backlog converts on schedule. The bear case is a 12–18 month delay in XPU shipment ramps from packaging yield failures or TSMC allocation constraints; at 25× FCF, that reprices the stock, not the business. The bull case is that $30B in quarterly bookings is early-cycle — that the eventual compute buildout is larger than the current backlog implies, and the next $73B is already forming.
The structural risks are known and priced. Google almost certainly represents 20%+ of total company revenue — customer concentration is the primary earnings risk. Broadcom has 100% foundry exposure to TSMC; any disruption to the Taiwan supply chain propagates immediately. None of these risks have a near-term catalyst. The contracted backlog is locked. The $30B quarterly booking rate, with two new undisclosed customers, suggests the demand curve is not flattening.
Sources
Broadcom Q1 FY2026 Financial Results (investors.broadcom.com)
The Register: Broadcom Takes a Tomahawk to NVIDIA's AI Networking Empire
Manufacturing Dive: Broadcom–Meta 2nm Partnership (April 2026)
CNBC: Broadcom Reveals Mystery $10B Customer is Anthropic (Dec 2025)
TrendForce: OpenAI Titan Chip on TSMC N3, Second-Gen on A16 (Jan 2026)
TrendForce: MediaTek Doubles 2026 AI ASIC Target to $2B (Apr 2026)
Broadcom: Jericho4 Shipping — Enabling Distributed AI Computing (Aug 2025)
NetworkTigers: A History of Broadcom — HP Origins to VMware and AI
NPR: Trump Blocks Broadcom Takeover Bid for Qualcomm (Mar 2018)