

Why KV Cache and Memory Drive AI Economics
Behind the memory bottleneck in AI infrastructure

When OpenAI cut input token prices last year, the press called it a price war. It wasn’t. It was an architectural pass-through. Anthropic, Google, and DeepSeek had all just shipped the same set of software optimizations—clever new ways to compress, reuse, and manage memory. The underlying cost of serving a token had collapsed, and the only question was who would cut their prices first.
The thing that collapsed is called the KV cache. Understand how it works, and the next five years of AI economics, hardware roadmaps, and infrastructure margins start to make perfect sense.
Two cost lines
Running an AI model (inference) comes down to two cost lines:
The Model Weights (Fixed Cost): These are the model’s “brains,” paid for during the massive training runs and amortized across every request the model ever serves. With enough traffic, weights are essentially free.
The KV Cache (Variable Cost): This is the model’s “short-term memory.” It is paid for in High Bandwidth Memory (HBM)—the ultra-fast, ultra-expensive RAM that sits right next to the GPU. This cost is incurred per user, per word, on every single request. It does not amortize. It scales linearly.
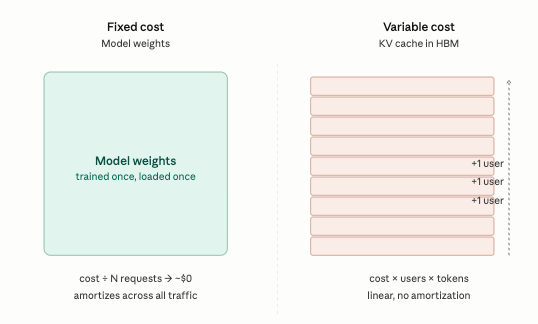
This second line dictates the unit economics of AI. It is also the line frontier labs talk about least, because it destroys their published “price-per-token” the moment a user’s prompt gets too long.
What the cache actually is
Transformers generate text one word (token) at a time. To write the next word, the AI has to look back at every previous word in the conversation. Re-reading the entire conversation from scratch every single step would be incredibly slow, so the model saves its notes in a “Key-Value” (KV) cache in the GPU’s memory.
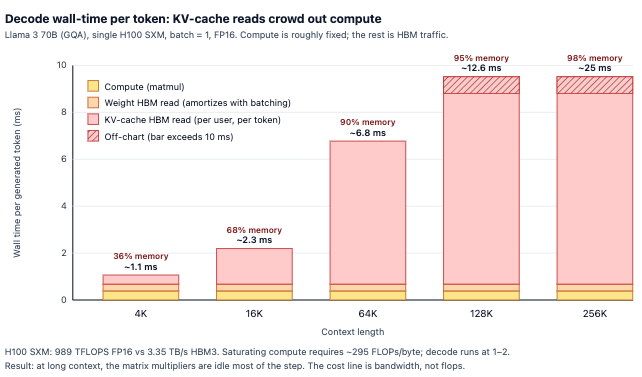
This cache grows with every single word you type or the AI generates. For a large model like Llama 3 70B, a 128,000-token conversation eats up ~40 GB of memory per user. Multiply that by concurrent users hitting the same server, and you hit a memory wall long before you run out of raw computing power.
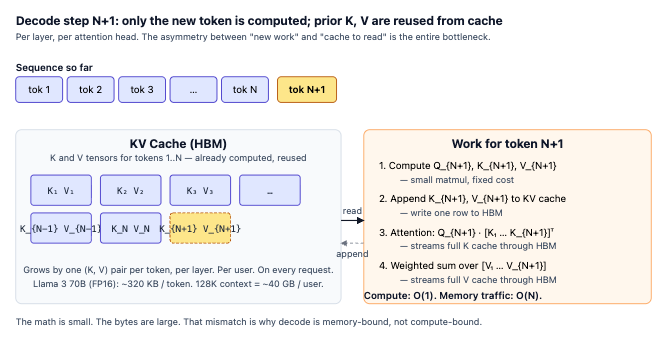
The bottleneck is bandwidth, not compute
People who grew up in the software era expect processor speed (compute) to be the bottleneck. It isn’t.
Modern GPUs like the NVIDIA H100/B200 are incredibly fast calculators, but their memory bandwidth can’t keep up. The math processors spend most of their time sitting idle, waiting for the short-term memory (the KV cache) to be fetched and delivered.
The math is brutal. When generating a response for a long document, the GPU is essentially reduced to a giant memory streamer with a math coprocessor stapled on. The speed limit is entirely dictated by how fast data can move through the HBM. This is why every 2026 accelerator roadmap is aggressively focused on memory bandwidth, not raw processing speed.
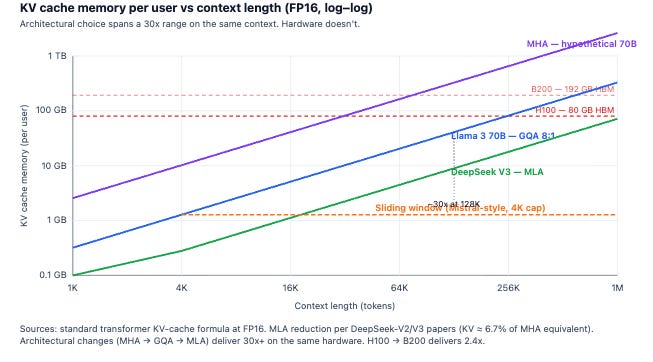
How Long Context Broke the Pricing Model
AI companies publish a single price per million tokens. That price is modeled against short interactions (4K to 8K tokens) where the KV cache is small enough to be a rounding error. Run that same model at 128K tokens, and the cost structure is completely unrecognizable.
Walk through the numbers: An H100 GPU holds the model’s weights and uses whatever memory is left over for the users’ KV cache. At an 8K context, a server might support ~190 concurrent users. At a 128K context, it supports one or two. It’s the same GPU, running the same model, charging the same nominal price—but the actual cost to the provider just skyrocketed.
This is why providers quietly changed their pricing in 2025. “Cached” tokens—where short-term memory is reused across similar requests—now cost a fraction of fresh tokens. The discount looks generous to developers, but it’s actually a confession from the AI labs about their underlying cost curve.
Agents will make this worse. Autonomous AI agents don’t have clean, reusable memory. They constantly replay long, mutating histories as they use tools and browse the web. Anyone modeling enterprise AI margins based on simple chatbots is in for a shock when traffic shifts to agents.
Architecture is outrunning hardware
Look at where the recent gains came from.
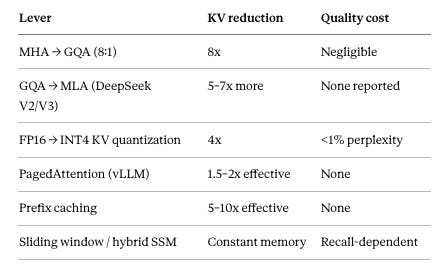
Hardware: An H100 to B200 upgrade yields 2.4x more HBM and 2.4x more bandwidth.
Software: The algorithmic stack has compounded efficiency by roughly 50–100x on the same silicon.
MHA —> GQA (8:1): Grouped-Query Attention reduces memory footprint by forcing multiple “query” heads to share a single “key-value” memory head, cutting the cache size by a factor of eight with almost no drop in intelligence.
GQA —> MLA (DeepSeek V2/V3): Multi-head Latent Attention massively compresses the memory cache into a tiny, dense mathematical space and decompresses it only when needed, yielding extreme cost savings with no reported quality loss.
FP16 —> INT4 KV quantization: Quantization physically shrinks the memory by rounding the high-precision decimal numbers down to smaller, 4-bit integers, trading a microscopic fraction of accuracy for a 4x reduction in size.
PagedAttention (vLLM): Instead of shrinking the data itself, PagedAttention eliminates wasted empty space in the GPU by breaking the cache into flexible blocks, acting like a highly efficient hard drive defragmenter for AI.
Prefix caching: Prefix caching saves the memory state of frequently used text—like system instructions or shared documents—so the model can instantly reuse it across hundreds of users instead of recalculating it from scratch.
Sliding window / hybrid SSM: These alternative architectures cap memory usage at a fixed, constant size by either only remembering the most recent conversation history or compressing the past into a static state, entirely eliminating the linear growth of the cache.
DeepSeek’s Multi-head Latent Attention (MLA) is arguably the most important architectural innovation of the last two years. It essentially compresses the KV cache and decompresses it on the fly, cutting memory usage by over 90% with no loss in quality. Every major AI lab will be forced to ship a version of this in 2026. Leaving that kind of cost advantage on the table while DeepSeek undercuts API prices is not a viable business strategy.
Where the capital flows
High Bandwidth Memory (HBM) is the actual scarcity in AI infrastructure right now. NVIDIA’s pricing power is bounded less by chip manufacturing limits than by how much HBM they can physically buy from suppliers like SK Hynix and Samsung. In 2026, the Big 3 Memory Players will sell over $70B of HBM at >60% margins.
This dynamic creates three durable opportunities and one trap:
Opportunity 1: Alternative Silicon. Startups like Cerebras, Groq, and Etched are betting that the right chip for running AI isn’t an HBM-starved GPU, but a specialized chip designed specifically to eliminate memory bottlenecks. If they capture even a narrow slice of the market—like high-speed AI agents—NVIDIA’s monopoly on serving AI will crack.
Opportunity 2: Memory-Smart Infrastructure. Differentiation in AI hosting has moved from “we have GPUs” to “we manage memory states better than you.” The open-source infrastructure stack (vLLM, continuous batching, prefix caching) is evolving to manage memory intelligently. Running this effectively at scale provides a massive, quiet moat for infrastructure companies.
Opportunity 3: New AI Architectures. We are seeing the rise of new models (like Mamba or Jamba) that ditch the traditional Transformer architecture entirely. Instead of a KV cache that grows linearly with every word, they use a constant, fixed-size memory state. If these models hit the same quality as OpenAI or Anthropic, the expensive, memory-heavy GPU stack becomes optional for a huge chunk of workloads.
The Trap: “GPU-as-a-Service.” Renting out H100s behind a simple API is a shrinking-margin business. Customers can buy raw compute from twenty different providers. The real profit margin lives in the software layer that manages the memory and routes the traffic—neither of which a basic GPU broker controls.
The decisive number
If you take one thing away from this post, make it this: When an AI is reading a long document, the vast majority of its time is spent just moving short-term memory through the hardware. The compute is already paid for. The customer is paying for a memory traffic jam.
That memory traffic is the variable cost of intelligence. It is the line item that dictates who enjoys 80% profit margins in AI, and who scrapes by with 30%. And it is the exact bottleneck that the next wave of tech innovation is coming to solve.
The companies that figure out how to bypass, compress, or outsmart the KV cache will own the unit economics of AI for the rest of the decade. Everyone else is just renting GPUs.
the KV cache as the real variable cost is sharp, this matches the AI infra efficiency we wrote about recently