

2023 Year in Review: The Great GPU Shortage and the GPU Rich/Poor
NVIDIA becomes the 5th hyperscaler to join the $T+ market capitalization club driven by surging demand from clouds, GPU clouds, big tech and AI startups

In the first half of 2023, OpenAI had all the headlines with the rise of ChatGPT. By May however, the spotlight changed towards the lower-level infrastructure powering LLMs: the GPUs. NVIDIA reported its Q1 earnings, highlighting the company’s role as the true backbone of AI in the data center and taking its market capitalization to $1T. It joined elite company of only 4 other tech companies: Apple, Microsoft, Google and Amazon. Today, NVIDIA’s market capitalization is >10X that of all foundation model providers, highlighting the key role its chips play in the data center.
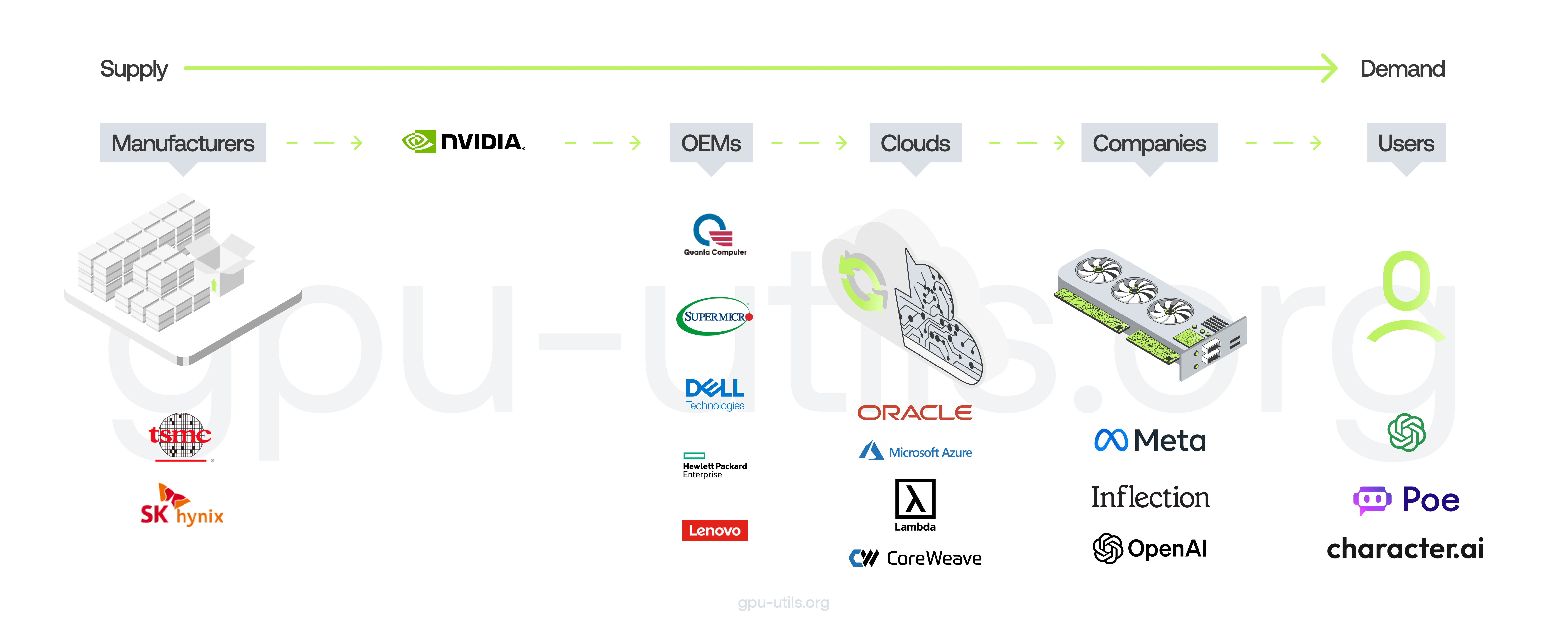
The Journey of GPU Supply and Demand, GPU Utils
Historically, NVIDIA’s largest customers were quite consolidated in the Big 3 Clouds: AWS, Azure and GCP. With the rise of AI came a plethora of new buyers: GPU clouds, Big Tech, other clouds like Oracle, data platforms and AI startups also joined the race to hoard GPUs to train AI models.
Cloud providers rushed to hoard GPUs for their customers who want to run AI workloads and build AI models. GPU clouds joined the race, supported by NVIDIA directly who wanted a more diversified customer base. Big Tech companies like Meta and Tesla massively increased buying for custom AI models and internal research. Foundation model companies like Anthropic and data platforms like Snowflake and Databricks acquired more GPUs to offer to customers building in AI and to support their AI product initiatives.
Even just a couple of weeks ago OpenAI couldn’t get enough GPUs, having to shut off paid signups for weeks while procuring more GPU supply.
“We’re so short on GPUs the less people use our products the better… We’d love it if they use it less because we don’t have enough GPUs” — Sam Altman in this talk
“It seems like everyone and their dog is buying GPUs at this point” — Elon Musk here
While NVIDIA doesn’t specifically disclose who its customers are, there are a variety of public sources and estimates that approximate individual companies. We attempt to do so on H100s as these are the fastest GPU both for inference and training LLMs, often the gold standard best in price-performance ratio. We attempt to approximate NVIDIA’s H100 buyers and scale below:

Estimates from multiple public sources, Omdia Research
Note: This only includes estimates of GPUs fully purchased and owned independently, not the use of GPUs through clouds and GPU clouds
Note 2: public estimates also pin Chinese companies at ~140K total GPUs — across Tencent, Alibaba, Bytedance and Baidu predominantly. With that said, we exclude these companies from our analysis as we don’t focus on that geography and further, there will be export controls on these chips shortly.
The big 4 types of buyers by share are:
1. Clouds (~49%): Microsoft, AWS, Oracle, Google
There are a few main differences between the big clouds in terms of AI workloads involving Networking (Azure and Oracle adopted Infiniband while AWS and Google Cloud have been slower to embrace this standard as they have attempted their own approaches to networking).
Capacity also differs across clouds, as Azure’s H100s are mostly going to OpenAI and AWS/GCP have limited capacity relative to demand and has lots going to Anthropic. Oracle has the most capacity relative to demand (and thus lowest pricing). Oracle was the first cloud to offer A100s and they worked with NVIDIA on an NVIDIA-based cluster.
Estimates say GPT-4 was trained on between 10,000 and 25,000 A100s and GPT-5 will require an order of magnitude more compute.
2. Big Tech (~27%): Meta, Tesla, Adobe, etc.
Meta has a huge amount of GPUs, especially given it is not a cloud provider itself. The Company has its prominent Llama family of open-source models, as well as huge training data sets for internal products like Instagram and Facebook that require capacity. Tesla also has a large amount of internal AI initiatives and models.
3. GPU Clouds (~20%): Coreweave, Lambda, Crusoe, Applied, other data center providers like Blackstone. Read about the rise of GPU clouds.
How have these GPU clouds amassed such a sizable share from practically nothing just a few years ago? We explore this in more detail below. In summary, these players have received priority supply from NVIDIA to improve customer concentration and have raised immense amounts of debt and equity capital alongside multi-year paid upfront customer agreements to fuel their GPU investments.
4. AI Startups and Other (~6%):
OpenAI (mainly through Azure but some owned independently), Inflection (through Azure and Coreweave), Mistral, etc. as well as other private firms like Jane Street, JPMorgan, Two Sigma, Citadel, etc.
NVIDIA is intentionally distributing supply to companies outside the Big 3 Clouds, as each has projects that directly attempt to compete with NVIDIA’s GPUs: AWS Inferentia and Trainium, Google TPUs, Azure’s Project Athena. In June, Microsoft signed a multi-billion dollar deal with CoreWeave to use its compute resources through Azure. Further, a huge amount of investment is coming from private equity firms like Blackstone alongside data center operators like Equinix, QTS and Digital Realty, which we discuss below.
The GPU Rich and the GPU Poor
In one of the best pieces of the year, Semi Analysis coined the terms “the GPU Rich and the GPU Poor” — defining the bimodal distribution of AI compute. A handful of firms have 25K+ A/H100 GPUs where researchers can access 100s to 1000s for projects. These firms mostly are training LLMs themselves or are cloud providers: OpenAI, Google, Meta, Anthropic, Inflection, Tesla, Oracle, Mistral. GPU clouds like Coreweave, Crusoe and Lambda also have large supply.
As shown above with OpenAI’s outages and user signup bottlenecks, even the GPU rich need more GPUs. Most companies are constrained on training resources, even OpenAI who has the most usage and thus inference workloads. Sam Altman says in his interview with Patrick Collison, they’d rather have more inference capacity if forced to choose, but OpenAI is still constrained on both.

Generated with DALLE-E
AI researchers and engineers are increasingly choosing where to work based on how many GPUs they have access to. Meta who has the 2nd most H100 GPUs in the world is increasingly leveraging GPU supply as a recruiting strategy. For training, they want H100s. For inference, it’s much more about performance per dollar. It’s still a performance per dollar question with H100s vs. A100s, but H100s are generally preferred as as they can scale better with more GPUs and give faster training times, and speed / compressing time of training is critical.
H100 is preferred because it is up to 3x more efficient, but the costs are only (1.5 - 2x). Combined with the overall system cost, H100 yields much more performance per dollar (if you look at system performance, probably 4-5x more performance per dollar). — ML researcher
The GPU Poor
Semi Analysis argues that everyone else is GPU poor, struggling with far fewer GPUs and spending significant time and effort to do things that simply don’t advance the ecosystem. They’re underdogs and this isn’t limited to just scrappy startups. Some of the most well recognized AI firms — Hugging Face, Databricks (MosaicML), Together and even Snowflake are in this bucket with <20K A/H100s. These companies have far higher AI research capacity relative to AI hardware — with high ambitions and potential customer demand. They have world class technical talent, but are limited by working on systems with orders of magnitude less capacity. These companies have massive inbound from enterprises on training real models and on the order of thousands of H100s, but that GPU supply is still a huge bottleneck.
The toughest part of GPU investment cycles are that companies must invest hundreds of millions to billions of dollars to develop AI models, even before customers can come. To be clear, many companies and even nation states are even buying GPUs without immediate plans to make their money back (Saudi Arabia, UAE, model developers, etc.). Even the most well funded companies have orders of magnitude less capacity than hyperscalers and model developers with hyperscaler partnerships.
Those with hundreds to thousands of H100 or A100 GPUs are mostly doing significant fine-tuning of large open-source models. Many startups and open-source researchers are fine-tuning smaller models for leaderboard benchmarks with broken evaluation methods that give more emphasis on style than accuracy or usefulness. They lack the depth in pretraining datasets and internet data to be higher quality and make durable advancements to the field. Their most common need is H100s with 3.2Tb/s InfiniBand.
The key takeaway is everyone from Microsoft, Google and Meta to model providers like OpenAI and Anthropic to everyone else in early and late stage startup land is acting as a pipeline of capital to NVIDIA. The “Great GPU Shortage” doesn’t seem likely to change anytime soon, though medium term AMD and Google/Broadcom are likely the most viable alternatives. Again though, engineers prefer NVIDIA and its robust software libraries. NVIDIA is also bolstering its software offerings with its DGX Cloud, offering pretrained models, frameworks for data engineering, vector databases and customization, inference engines, APIs and support for custom enterprise use cases. The public list of customers includes huge enterprises across all verticals like Adobe, ServiceNow, AstraZeneca, Accenture, Shutterstock, Getty Images Amgen and more.
What are the other costs for training and running LLMs?
GPUs are the most expensive component and >70% of total costs. InfiniBand networking is also costly and typically bundled with NVIDIA’s Mellanox offering. Arista is the 2nd most popular choice for networking. System RAM and NVMe SSDs are also expensive. 15% of the total cost of running a GPU cluster typically goes towards power and hosting (electricity, cost of the dataenter building, cost of the land, staff, etc.) — roughly split evenly between power, and the other elements of hosting (land, building, staff).
It’s mostly networking and reliable datacenters. AWS is difficult to work with because of network limitations and unreliable hardware
— Deep learning researcher
Each DGX H100 GPU costs approximately $460K, with 8x H100 GPUs and Infiniband - quite an investment; while 1 HGX H100 with 8x H100 GPUs is between $300K to $380K. H100s are cited as about 3.5X faster than A100s for inference and up to 9X faster for training. Thus, a lot of the hoarding of the latest models is for training needs. It’s unclear how durable this GPU demand will be. Less performant hardware will increasingly be used for inference demand, which should rise over time.

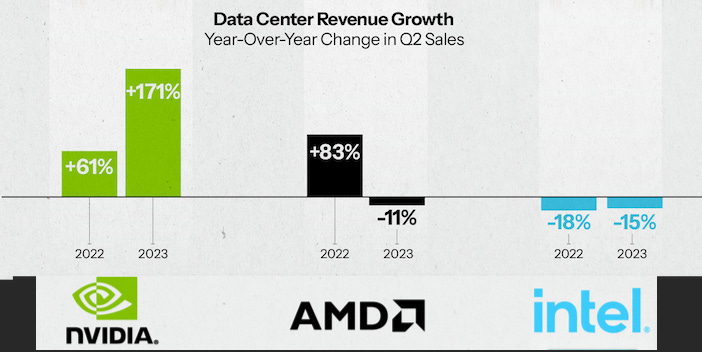
Why aren’t companies buying AMD GPUs?
While AMD’s stock more than doubled in 2023, its data center revenue only grew single digit percentages. Part of that reason is it was in between a 2 year upgrade cycle where it significantly lagged NVIDIA, though it has been losing market share in the data center compared to NVIDIA.
Some quotes from GPU utils that show why companies are buying NVIDIA:
Who is going to take the risk of deplying 10,000 AMD GPUs or 10,000 random startup silicon chips? That’s almost a $300 million investment. – Private cloud exec
Theoretically a company can buy a bunch of AMD GPUs, but it just takes time to get everything to work. That dev time (even if just 2 months) might mean being later to market than a competitor. So CUDA is NVIDIA’s moat right now. – Private cloud exec
How many GPUs are needed for AI models?
GPT-4 is estimated to have been trained on between 10,000 to 25,000 A100 GPUs. GPT-5 will need 50K H100s according to Elon.
Meta has ~25,000 A100 GPUs, which were used on Llama
Stability AI has about 5,000 A100s
Falcon-40B was trained on 384 A100s
Inflection used 3,500 H100s
Who makes the A100s and H100s?
TSMC. While Nvidia has worked with Samsung in the past, for 5nm GPUs they only use TSMC as it has superior practices in these types of chips. Perhaps NVIDIA also works with Intel or Samsung again in the future, but neither of those are happening in the short-term in a way that will address the supply crunch. Production takes 6 months from production to being sold to a customer.
Do startups build their own data centers? Which companies use which clouds?
For building a datacenter, the key potential risks are time to build, whether you have expertise in hardware and the people costs associated with managing this, and the capex intensity. The spectrum from rent to own is: on-demand cloud (pure rental using cloud services), reserved cloud, colocation (buy the servers, work with a provider to host and manage the servers), self-hosting (buy and host the servers yourself). Most companies needing large H100 capacity will do reserved cloud (either with traditional CSPs or GPU clouds) or colocation.
While capacity at major cloud providers ran out earlier this year, companies scrambled for new ways to procure GPUs and partnered with new GPU clouds. These bullets below for each specific company reflect usage of the Clouds above:
OpenAI: Azure and some owned GPU infrastructure
Anthropic: AWS and Google Cloud
Hugging Face: AWS
Cohere: AWS and Google Cloud
Stability AI: Coreweave and AWS
Character.ai: Google Cloud
MosaicML: Oracle and Coreweave
Inflection: Azure and Coreweave
Grok / X.ai: Oracle
Notice the pattern of nearly every foundation model provider partnering up with cloud providers. In 2023, corporate VC represented >70% of all AI investment, highlighting the role of infrastructure in competitive product offerings. Most of these companies are classified as GPU poor.
What’s next — Viable NVIDIA alternatives?
This is the trillion dollar question in AI. Over time, inference will increasingly be price-performance oriented and older hardware will run some AI workloads — though inference demand will rise exponentially.
Semi Analysis believes the most viable alternative over time will be Google’s TPUs built with Broadcom. AMD also released its latest model in December which it claims to be near parity with A100s — we’ll see if this becomes competitive after a sluggish 2023. Microsoft and Amazon are also working on custom chips with Broadcom, though these are not yet in production. Finally, a plethora of startups are working on LLM ASICs (application-specific integrated circuits) — from Cerebras, Groq and SambaNova in the data center to Syntiant, Qualcomm and Mythic for edge AI.
In the short to medium term, NVIDIA seems to be the consensus choice for CSPs, GPU Clouds, Big Tech and AI startups building huge GPU clusters.