

Data Infrastructure in 2025: Platforms vs. Specialization
Platforms are the foundation—but the next generation of infrastructure is being defined by specialization, orchestration, and cost-aware execution.


Data and AI infrastructure are undergoing a tug of war, balancing the convenience of integrated platforms with the flexibility of modular, AI-optimized systems.. Data pipelines have moved beyond analytics and are now the foundation of any AI system. Over the past 10 years, we saw the rise of data platforms like Snowflake, Databricks and BigQuery, as well as Modern Data Stack tools around platforms like dbt, Fivetran, Looker and many others. However, the cost of Snowflake and Databricks remain high—particularly as AI workloads increase demand on compute.[link]:
“Databricks is fabulous if you can afford it… everyone loves Snowflake, but you can run a $60k query pretty easily by accident.” – CIO at F2000
From 2010 to 2022, Data and ML budgets massively grew unchecked, fueled by the Big Data movement and the widespread adoption of scale-out architectures. Now, however, CFOs are demanding greater ROI on AI and data infrastructure spending, leading to a renewed emphasis on cost efficiency and infrastructure optimization. This shift has opened the door for startups developing novel, cost-efficient architectures, making it a compelling investment theme. While large platforms provide convenience, they are often not cost-effective, and specialist vendors are emerging to drive major efficiency gains. Cheaper, workload-specific solutions are now defining the next wave of successful competitors. From foundational data management (compute and storage) to specialized workloads (query engines and geospatial analytics), new vendors are taking advantage of this trend.
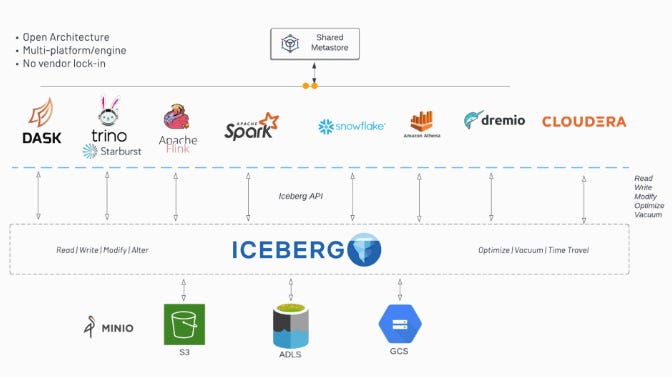
As companies reassess their data and AI spending, a key architectural shift is making cost efficiency more attainable: the decoupling of storage and compute. Traditionally, data warehouses bundled these functions together, forcing businesses to scale compute alongside storage, even when unnecessary. The rise of Open Table Formats (OTFs) like Apache Iceberg [“What is Apache Iceberg?”], Delta Lake, and and even OpenTelemetry [“What is OpenTelemetry?”] are contributing to this unbundling by promoting open interfaces and ecosystem interoperability. These new data formats are breaking down platforms, allowing companies to store data independently and choose the best compute engine for each workload. This shift not only reduces costs but also creates a more flexible and competitive ecosystem where specialized query engines and workload-specific databases can thrive.

With storage and compute now decoupled, companies can optimize compute resources for specific workloads instead of relying on one-size-fits-all data platforms. New query orchestration and execution platforms are emerging to ensure workloads run on the most efficient and cost-effective compute layer with scale-up architectures. At the same time, specialized databases built for log data, time-series analytics, and geospatial workloads are providing lower-cost, high-performance alternatives to traditional warehouses.
As cloud data and compute costs continue to rise, this shift toward modular, workload-specific, cost-efficient architectures is defining the next generation of data infrastructure:
Data Transformation Efficiency – Cutting warehouse transformation costs

Data transformation can be a major cost driver in cloud warehouses, especially when entire datasets are recomputed unnecessarily. SQLMesh and Tobiko Data reduce costs by 50% over dbt by using incremental processing, meaning only changed data is recomputed. This approach reduces redundant queries, lowers compute costs, and speeds up processing without affecting data accuracy.
Specialized Data Types and Workloads:
Observability Data – Manage and query high-scale log and time-series data

Storing and analyzing log and time-series data is often many $Ms per year because warehouses like Snowflake and BigQuery charge high fees for storage and compute. Hydrolix cuts costs by >75% with its compressed storage architecture and only using compute when needed, instead of keeping it running constantly. This allows companies to retain more data and run fast queries at a fraction of the cost.

Geospatial Data – Manage and query large-scale location data

Warehouses are not built for geospatial workloads, making queries slow and expensive. Wherobots and its open-source Apache Sedona provides a cloud-native spatial database designed to handle large-scale geospatial queries efficiently, reducing compute costs while improving performance. By optimizing query execution and resource usage, Wherobots enables faster, cost-effective location analysis.
Queries: Management, Orchestration, and Execution Optimization


Credit: SeattleDataGuy’s What is Apache Iceberg piece
Query Management & Compute Orchestration – Optimizing query execution across engines
Running queries across multiple engines is expensive, and most companies either manually manage it or stay locked into a single vendor like Snowflake. New startups are emerging to automate query routing, selecting the most cost-efficient engine for each workload, reducing unnecessary compute usage. Instead of overpaying for a single platform, companies can distribute workloads more efficiently across different processing engines.
Query Execution Optimization – Moving to scale-up SQL
Running SQL queries in the cloud is expensive, especially when workloads rely on scale-out architectures like Databricks, Snowflake and BigQuery, which distribute queries across multiple compute nodes, driving up costs.
However, hardware advancements and the rise of Python-first workflows are enabling a shift back to scale-up computing, where local machines handle more processing before relying on the cloud. Today, even consumer-grade hardware like MacBook Pros can run 70-billion parameter models (equivalent to GPT-3.5) locally, demonstrating how much compute power is now available outside of large cloud clusters. This shift allows developers to prototype, train, and analyze data on local infrastructure, reducing cloud costs and unnecessary complexity.
Motherduck optimizes costs by running queries locally first (scale-up) before leveraging cloud compute only when necessary.
Similarly, DataFusion (7K+ stars), an in-memory query engine built in Rust using Apache Arrow’s columnar format (detailed below), offers fast, cost-effective SQL execution without the overhead of cloud warehouses, making it well-suited for scale-up processing.
Apache Arrow (15K+ stars) has built a universal connectivity layer for modern data warehouses to eliminate inefficiencies from custom connectors, costly middleware, and manual data movement. Some engines optimize query orchestration by routing workloads (where to run) to the most cost-effective engine, while others enhance execution efficiency (how queries execute) —together, they reduce compute and improve performance.
The article nails the high-end scaling challenges but misses the gritty early-stage realities. As a broke solo founder, I'm living in the trenches where BigQuery’s $5-per-terabyte scan cost and generous free tier are nothing short of survival-grade. At this stage, it’s not about optimization — it’s about optionality. A fully managed, serverless warehouse like BigQuery means I can validate ideas without managing infrastructure or burning cash I don’t have. Is it scalable? Not in the long run. But right now, it’s what lets me move fast with zero DevOps overhead.
The transition from survival to scale doesn’t happen all at once. When some early capital comes in — call it $20K to $30K — I’ll migrate to Snowflake for its auto-suspend compute, efficient concurrency handling, and deeper ecosystem. Paired with orchestration tools like Tobiko or SQLMesh, I can implement incremental processing to cut down warehouse transformation costs. Full-table recomputation is fine when you’ve got a $300K data budget, but not when every dollar counts.
At mid-scale (~$300K in spend), I’ll take a hybrid approach: ClickHouse Cloud for real-time OLAP, Snowflake for curated batch datasets, and Iceberg as the open table format glue. Starburst will handle federation, letting me query across silos and preserve performance. At this point, I'm not choosing tools based on branding — I’m choosing based on query cost, tail latency, and governance overhead. Real-time responsiveness will define user experience for an AI-native platform like Hologram, and ClickHouse blows traditional cloud warehouses out of the water for OLAP workloads.
By the time Hologram reaches hyperscale, there’s no question: the stack goes in-house. I’ll run Iceberg on S3, train on self-hosted Spark, serve real-time workloads through ClickHouse, and archive logs with Hydrolix. Every component is modular, open, and chosen for its economic unit cost per query, per job, and per insight. Governance will no longer be a checkbox — it’ll be a survival need. At this point, I’ll be optimizing down to the DAG level in Tobiko and enforcing lineage, versioning, and reproducibility like a government agency.
What the article got right is the pressure on modern data teams to justify spend. What it missed is the uneven terrain founders have to navigate from zero to scale. The path to intelligent AI infra is modular, staged, and budget-bound. It’s not sexy — but it’s how winners are built.