

DeepSeek's R1 and AI Infrastructure Economics
Did DeepSeek and its model distillation methods crush the economics of AI training?

Announced last week, DeepSeek's R1 triggered a $600B drop in NVIDIA's market value and a 15-20% decline across semiconductor stocks, while AI application companies saw their shares rise. The core innovation isn't just about cost - it's about how AI models are trained. R1 broke past the limits of human-curated training data by using AI-generated examples verified through automated evaluation. When the model solves a math problem, for instance, the system checks both the answer and the reasoning process. Good examples then feed back into training, creating a self-improving loop.

DeepSeek and Model Distillation?
DeepSeek's R1 demonstrates how smaller companies can reverse engineer state-of-the-art AI models through four key technical approaches: distilling knowledge from existing models like GPT-4, avoiding computationally expensive sparse architectures (like Mixture of Experts), implementing aggressive memory optimizations (especially in key-value caches), and using straightforward reward functions for training. Their most innovative step was using AI-generated training examples verified by automated evaluation functions - breaking past the limits of human-curated data. The benchmarks are impressive:

Source: DeepSeek’s release paper
This threatens to reduce the value of massive AI research investments from companies like OpenAI, Meta, and Anthropic, potentially affecting projects like Meta's $500B Stargate datacenter initiative. Being the first to market made ChatGPT the giant it is today, but it’s extremely expensive: for OpenAI, $7B on training and inference last year. Will the first mover continue to get paid for the research innovation? Or will knockoffs undercut their pricing power?

Put more simply, DeepSeek is the pioneering example of model distillation: the process of creating smaller, more efficient models from larger ones, preserving much of their reasoning power while reducing computational demands. This means top AI research may not be as proprietary as imagined.
Here are the papers:
Technical Progress
DeepSeek claims R1 cost only $5.7M to train - a fraction of what U.S. companies typically spend with OpenAI spending $7B on training and inference in 2024 and Anthropic also in the billions. However, this number needs context. While DeepSeek reports using 10,000 A100 GPUs, industry experts like Scale AI's Alexander Wang estimate they actually used closer to 50,000 NVIDIA Hopper GPUs - putting their true compute usage in line with U.S. companies.
The real advances are in efficiency:
Memory Optimization:
Switched to 8-bit floating point numbers from 32-bit, cutting memory use by 75%
Achieved 93% compression of key-value cache indices, which traditionally consume most GPU memory
These changes enable running large models on standard hardware
Speed Improvements:
Pioneered what NVIDIA now calls "test-time scaling," complementing traditional pre-training and post-training scaling laws. NVIDIA states this is the third scaling law of AI.
Implemented multi-token prediction instead of generating one token at a time, doubling inference speed
Split large models into smaller components that can run on consumer GPUs, rather than requiring datacenter hardware
Optimized PCI-Express for better scaling across multiple GPUs
Performance Trade-offs: R1 matches leading models in reasoning tasks but lags in other areas. This suggests focused training can achieve specific capabilities without massive general-purpose models.
Facts vs. Claims
The counterargument to DeepSeek’s meteoric rise to #1 in the App Store and top of benchmarks is equally compelling: original AI research and massive compute still matter to being truly first, even if that margin is small. Companies that create novel architectures and training approaches will always stay ahead of those who copy them. Copied models inherit the limitations of their teachers and often perform worse on edge cases. But the gap between original and copied models may be good enough for most commercial applications.
Two main claims need examination:
Training Cost: The reported $6M training cost leaves out important details and surely is the low end of estimates. This figure is what caused panic in the US stock market with semiconductor stocks, as investors perceived past and planned AI training spend to be wasteful. The paper itself says this doesn't count "costs associated with prior research and testing." This is like saying a new drug only cost its final production run, ignoring years of research costs.
AI Compute Capacity: DeepSeek says they used 10,000 A100 GPUs, but experts like Elon Musk and Alexandr Wang think they actually used about 50,000 newer GPUs — likely attained through circumventing US export controls (perhaps buying new NVIDIA units through Korea, Singapore, etc.). This matters because it affects how we think about the real costs of AI development.
What DeepSeek means for AI Compute
For companies building or buying AI systems:
Challenging AI training spend:
Hardware waste?: Are initiatives like $500B of Stargate data center buildouts overbuilding if models can be distilled and copied?
Dylan Field of Figma states there are likely order of magnitude improvements to be made in training AI

Better software-based training: Success now also depends more on how you train models, not just how many computers you use. There has been much talk of this with AI startups building data curation tools to cut training spend. DeepSeek’s research is novel and the major US AI companies are already working to fold DeepSeek’s techniques into their models to improve AI training efficiency as well as inference latency and costs.
NVIDIA states there are now three scaling laws: 1) pre-training; 2) post-training; and 3) test-time scaling pioneered by DeepSeek.

More money for inference?: While each AI model might cost less to run, more companies will use AI, likely increasing total computing needs.
Satya Nadella highlights Jevons’ Paradox in AI, noting that as AI becomes more efficient and accessible, its usage will skyrocket, transforming it into an indispensable commodity with ever-growing demand.

More competition in open-source?: Meta had been running away with the #1 open-source model. DeepSeek and Bytedance are challenging this.
DeepSeek's work improves AI development, similar to other recent advances in making AI faster and more efficient. It shows that careful engineering can achieve good results without massive computing resources.
Market Realities and Implications?
The stock market reaction points to a deeper concern: the economics of AI infrastructure might fundamentally change. Tens of billions in AI training are at stake However, it is dangerous to oversimplify a complex topic.
AI Data Center Buildout Won't Stop: Building AI data centers takes years and capacity is still massively underbuilt. Google, Meta, and Microsoft each plan $60-80B in annual datacenter spending.
Longer term data center economics come under question: If training costs drop 95% and returns from bigger models plateau, the massive datacenter buildout plans might need revision.
Training Efficiency in the Spotlight: US model developers are already working to incorporate DeepSeek’s research. Order-of-magnitude improvements in training and inference efficiency are theoretically possible but not yet achieved. Current gains come largely from better engineering of known techniques.
Premium Models vs. Open-Source: Meta has been the market leader in open-source, offering a 10X+ cheaper alternative to OpenAI and Anthropic with premium API-based models. This battle will continue and intensify with Deepseek; we first wrote about it in July 2024 in “Open-source vs. Proprietary Models”.
Export Controls Mayhem: Current restrictions focus on hardware but ignore model distillation via software. DeepSeek effectively copied capabilities from American models like GPT-4, raising questions about the effectiveness of export controls. OpenAI and Anthropic are likely to throw a fit about this — ironically they were the ones accused of IP theft from data providers.
Restrictions on hardware sales are becoming more strict. China likely is buying GPUs via third-party, friendly brokers in nations friendly with the US like Singapore or Korea. Will the US be able to enforce no reselling of GPUs?
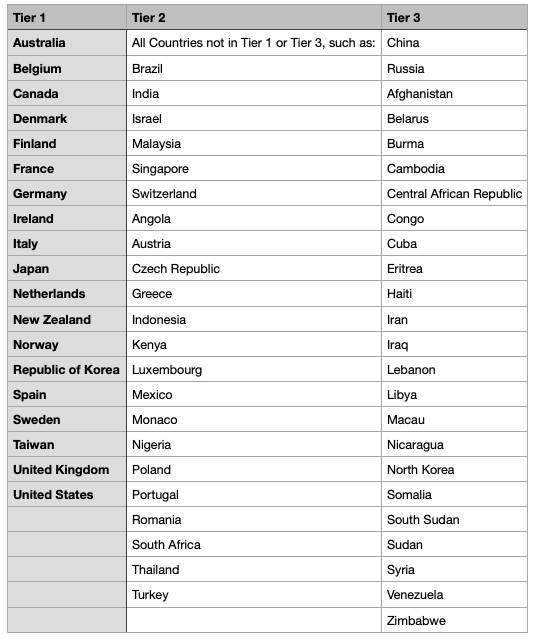
The US just last week put restrictions on GPU supply by country, separated across tiers. Expect restrictions like this to become more intense and like defense technology
More margin in application companies?: While NVidia, Broadcom and semiconductor companies were down 15-20% each, application software companies saw a rise in their stock prices. Efficient open-source models fundamentally change startup economics. When model costs drop from dollars to cents per million tokens and deployment becomes possible on standard hardware, startups can focus their capital on building better products rather than paying for basic infrastructure. This shift could trigger an explosion of AI-powered applications.
End to the AI Oligopoly?: A team of recent graduates achieved what billion-dollar labs couldn't - or wouldn't. This suggests opportunities for smaller, focused teams in resource-constrained environments to innovate in AI. One of the biggest worries of venture investors over the past 2 years is an OpenAI/Anthropic/MSFT/GOOG/Meta oligopoly where only $B+ players can survive. This trend may be fundamentally broken.
Closing thoughts
The DeepSeek release marks an important shift in AI development. While it won't end the need for massive compute resources, it shows how focused engineering and clever training approaches can achieve specific capabilities more efficiently. The true innovation isn't the headline cost number - it's proving that automated training data generation and focused optimization can match brute-force approaches in targeted applications.
All this said, DeepSeek is standing on the shoulders of giants having built on existing research and models. Being first still matters - they needed access to leading models like GPT-4 to achieve their results.

Chris, well done synopsis.