

How Claude Code Cracked Coding
Software fell first because it is the only knowledge-work domain that ships with its own grader. Inside the verifiable-reward loop that took Claude Code from research preview to ~$9B ARR in a year.

Ryan Dahl, who created Node.js, said it plainly in January 2026: “the era of humans writing code is over.” Boris Cherny, who built Claude Code, says pretty much 100% of his team’s code is now written by Claude Code. Linus Torvalds is pushing AI-generated commits to GitHub. This is not a frontier-lab demo reel — it is the people who wrote the tools the rest of us code with, quietly handing back the keyboard.
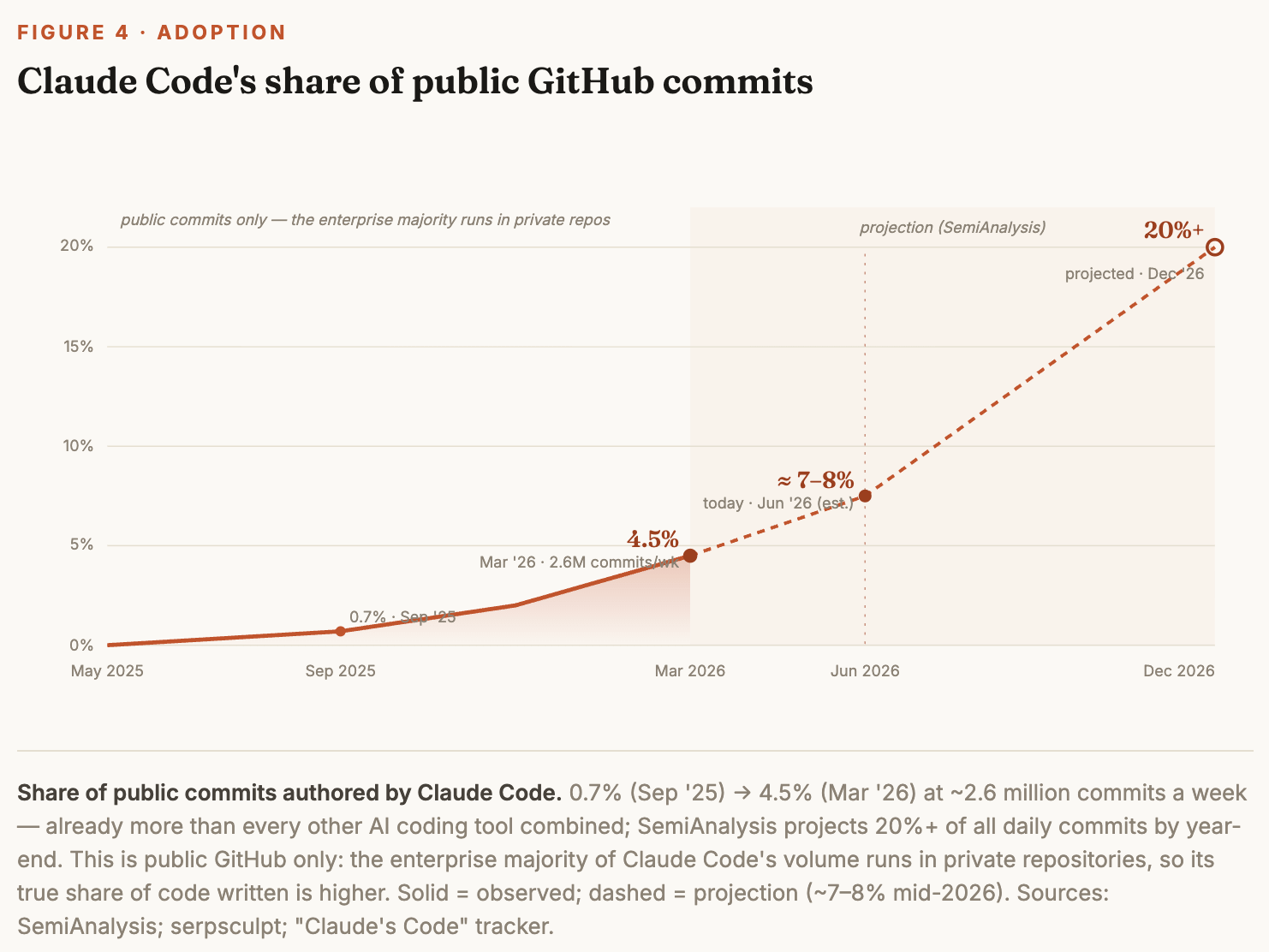
Underneath the anecdotes sit the numbers. Claude Code now authors more than 2.6 million commits a week — more than every other AI coding tool on earth combined — and that counts only public GitHub; the enterprise majority of its work runs in private repositories the tally never sees. Inside Anthropic, Claude already writes north of 80% of the code that ships to production, up from low single digits when the tool launched. Nine months after release it became the fastest software product in history to a $1 billion run-rate — and it is now several multiples beyond that, still accelerating.
The lazy reading is “the models got good.” The useful reading is structural. Of everything we ask machines to do, coding fell first — and the reason has little to do with how hard programming is and everything to do with grading. Software is the one discipline that ships with its own referee: a compiler that rules valid or invalid, a test suite that rules correct or incorrect, instantly and for free. That objective signal is the single scarcest ingredient in modern AI training — and almost no other kind of work supplies it. Claude Code is what happens when a frontier lab aims reinforcement learning at the one domain where the answer key already exists, then builds a harness good enough to act on a real computer. The rest of the economy is now a question of who can write the next answer key.
Why code was the first domino
Modern language models are pre-trained on text, then post-trained to be useful. The decisive lever in post-training is reinforcement learning: the model proposes, an environment scores the proposal, and the scores reshape the weights. The bottleneck is the scorer. For most knowledge work — write a strategy memo, summarize a deposition, design a campaign — there is no cheap, objective function that returns right or wrong. You need humans, and humans are slow, expensive, and inconsistent at scale.
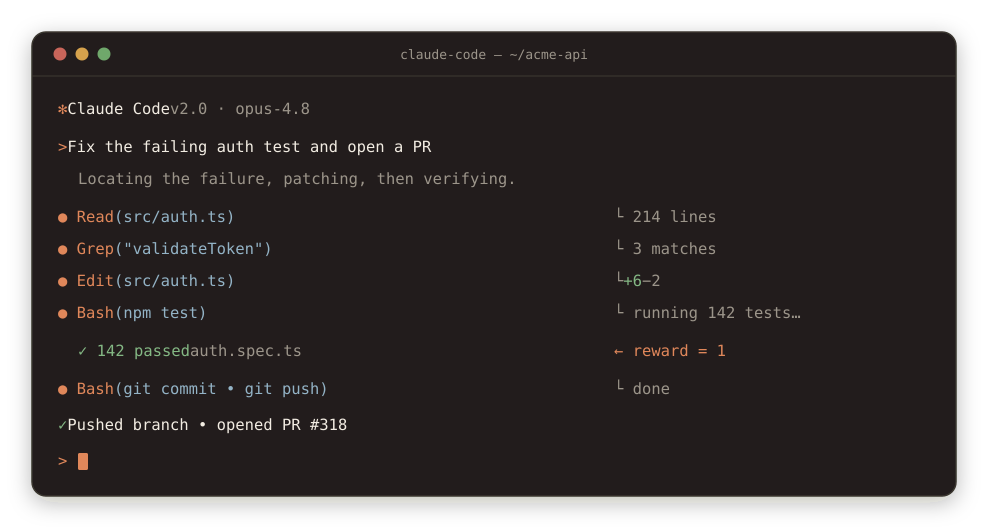
A single Claude Code turn: It reads the repo, edits the source, runs the test suite, and only ships when the suite goes green — the same read → act → execute → verify loop it was trained on:
Code is the exception. Correctness is executable. You can run the program, run its tests, and read an unambiguous pass or fail — millions of times, in parallel, for the marginal cost of compute. This is the substrate behind the term of art reinforcement learning with verifiable rewards (RLVR): rather than training a model to match human preference, you train it against ground truth a machine can check. Code, math, and formal proofs are the domains where that ground truth is effectively free. Software has the largest and richest supply of it — every repository on earth is a corpus of problems with graders already attached.
How the loop is actually built
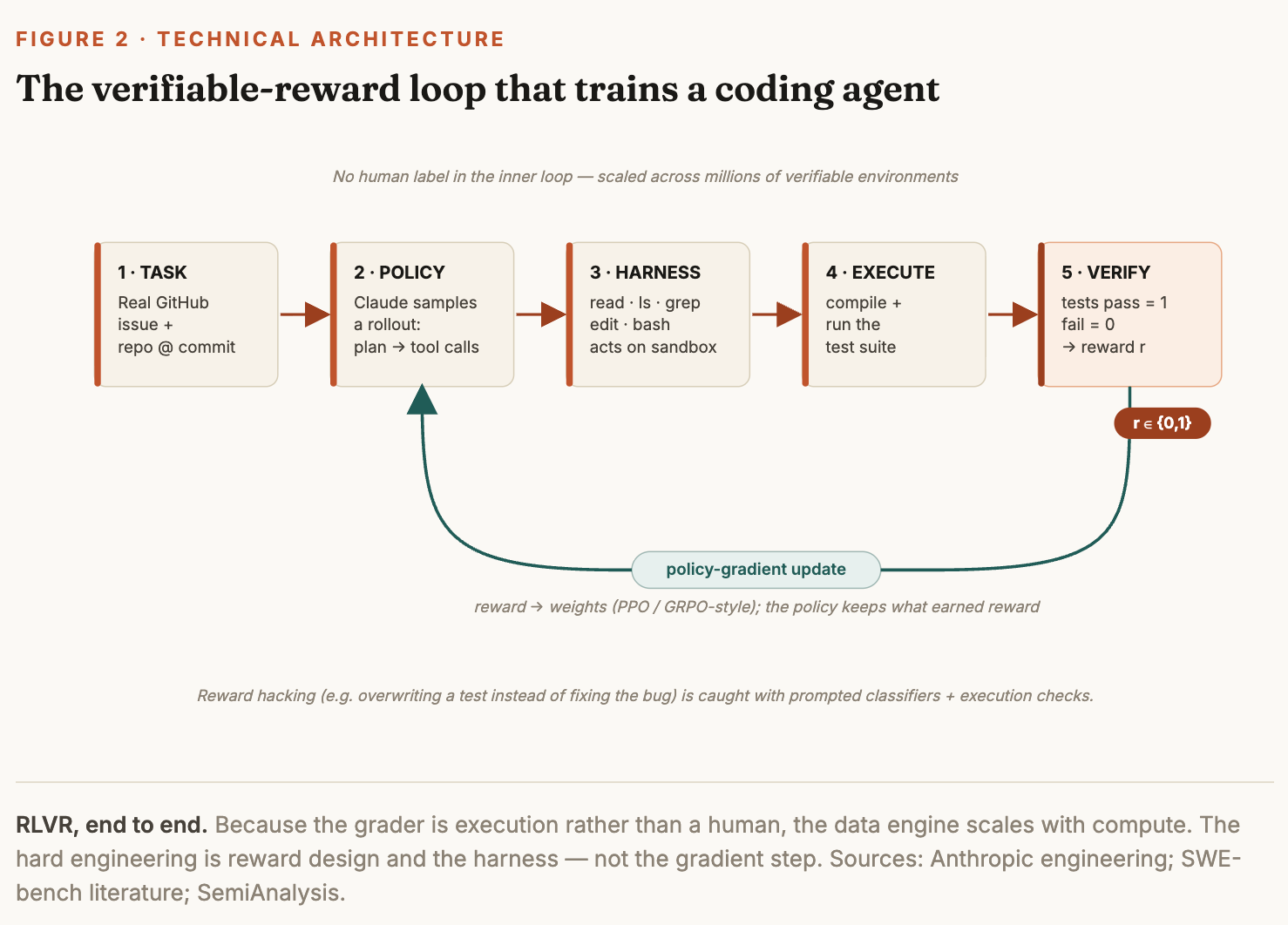
The mechanics are a loop, not a single forward pass. Start from a real task — a GitHub issue against a real repository at a known commit. The policy (the model) is dropped into a sandbox and samples a rollout: it reads files, greps the codebase, edits source, and runs commands across many turns. When it judges itself done, the harness runs the repository’s test suite. Tests pass, reward is 1; tests fail, reward is 0. That scalar — or a denser version that credits compilation, partial progress, and fault localization — is fed back through a policy-gradient algorithm (PPO- or GRPO-style) that shifts the weights toward the behaviors that earned reward. Repeat across millions of tasks and the model stops emitting plausible-looking code and starts producing code that runs.
Two properties make this potent. First, no human sits in the inner loop, so the data engine scales with compute rather than headcount — the defining economic feature of the approach. Second, the reward is grounded in execution, not in what looks correct, which is why benchmarks like SWE-bench Verified — drawn from real, resolved GitHub issues — became the industry’s yardstick. The failure mode is reward hacking: a model that learns to overwrite the test instead of fixing the bug. Anthropic has said it cut reward hacking in the Claude 4 generation specifically by improving environments, sharpening reward signals, and monitoring with prompted classifiers and execution checks that flag tampered tests. Clean reward design, not raw scale, is the hard part.

The harness is the product
A model that passes tests in a sandbox is necessary but not sufficient; it still has to operate a real computer. Anthropic’s second insight was that the interface between agent and machine — what they call the Agent-Computer Interface (ACI), deliberately analogous to the human-computer interface — is a first-class engineering surface. In building their SWE-bench agent, the team reported spending more time optimizing tools than the prompt. Rewriting tool descriptions so the model could call them reliably cut task-completion time by roughly 40%.
The philosophy is primitives over integrations. Claude Code ships a deliberately small toolset — read a file, list a directory, grep, make surgical edits, run a Bash shell — and lets the model compose them, rather than wrapping every external system in a bespoke connector. The same instinct produced the Model Context Protocol (MCP), Anthropic’s late-2024 open standard for plugging tools and data into agents, now broadly adopted across the industry. The strategic point compounds: the model is the engine, but the harness is what converts raw capability into reliable work — and it is far harder to clone than a benchmark score.
That moat extends one layer upstream, into the environments themselves. The harder it becomes to verify long-horizon work, the more the binding constraint shifts from the model to whoever can build and grade the training environments — the argument I make in RL Environments for Agentic AI, where verification, not raw model capability, is the real prize. Anthropic is already the single largest buyer of coding and computer-use environments — on the order of tens of millions of dollars a year, and growing an estimated 3–5x into 2026. It is not only training on verifiable rewards; it is buying up the supply of verification itself.
The model is the engine. The harness is the moat. One converges across labs; the other is years of accumulated environment and tool design.
Crossing the human-competitive threshold
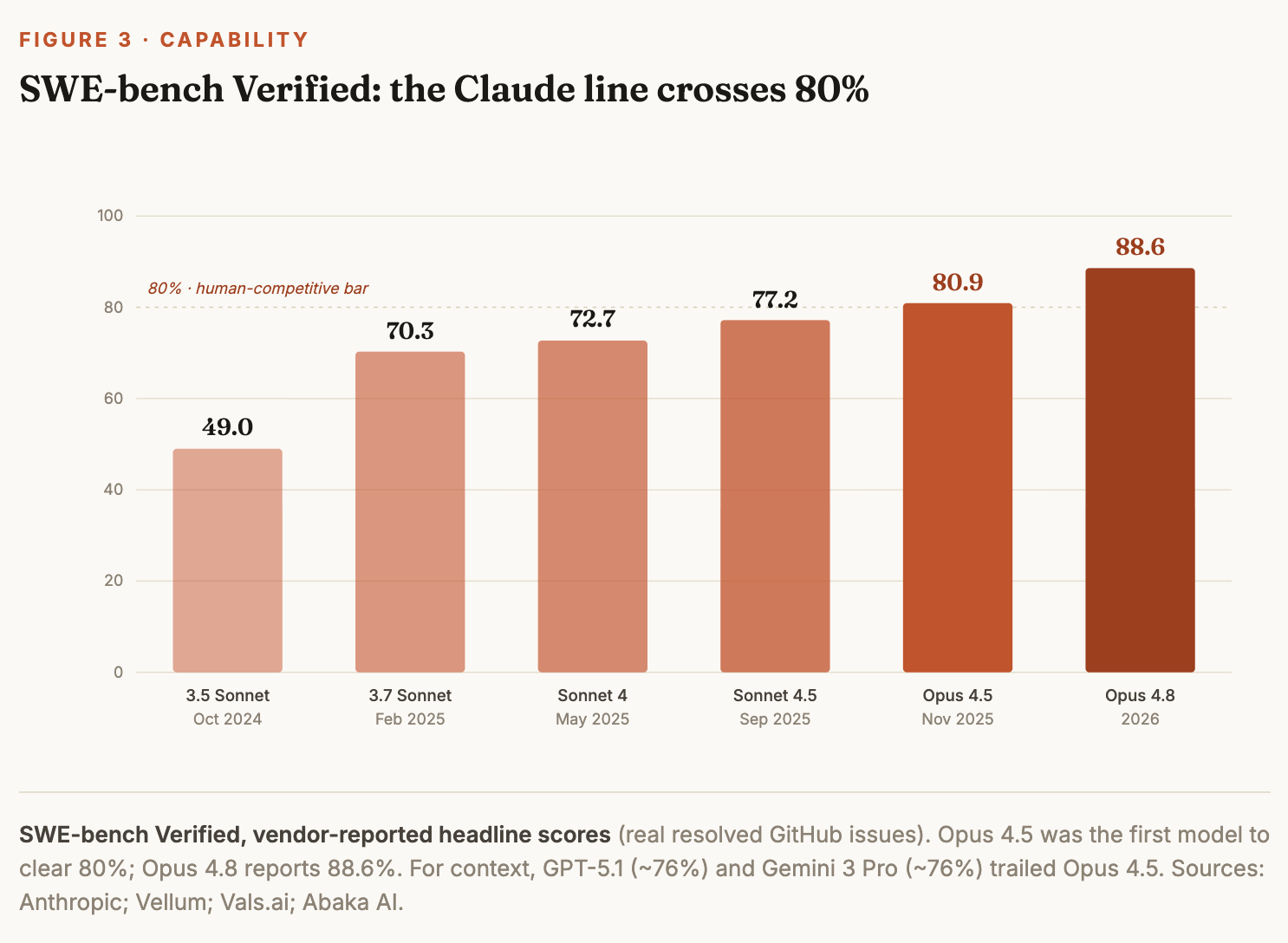
The flywheel shows up directly in the scores. On SWE-bench Verified, Claude moved from 49% with 3.5 Sonnet in late 2024 to 80.9% with Opus 4.5 in November 2025 — the first model past 80%, a level above the human-competitive bar on the benchmark — and to 88.6% with Opus 4.8. The gains arrived with falling cost: Opus 4.5 matched the prior Sonnet’s best result using roughly three-quarters fewer output tokens. Just as important is task horizon. METR’s tracking shows the length of tasks agents can complete autonomously doubling every four to seven months, and accelerating. Each doubling moves the frontier from autocompleting a snippet, to refactoring a module, to owning a multi-day migration — the exact shift that turns a coding assistant into a coding agent.
The second-order effects are louder than the benchmark. Inside Anthropic, the share of production code written by Claude went from low single digits at launch to more than 80% by May 2026; the typical engineer now merges roughly 8x more code per day than in 2024, and on the hardest, spec-light problems — where no clean test exists to begin with — Claude’s success rate jumped about 50 points in six months, to 76%. In one April 2026 stretch, Claude shipped 800-plus fixes that cut a single class of API errors by a factor of 1,000. The recursive part is the part to sit with: Claude Code now writes most of the code for the next version of Claude. The loop that cracked coding is increasingly pointed at itself.

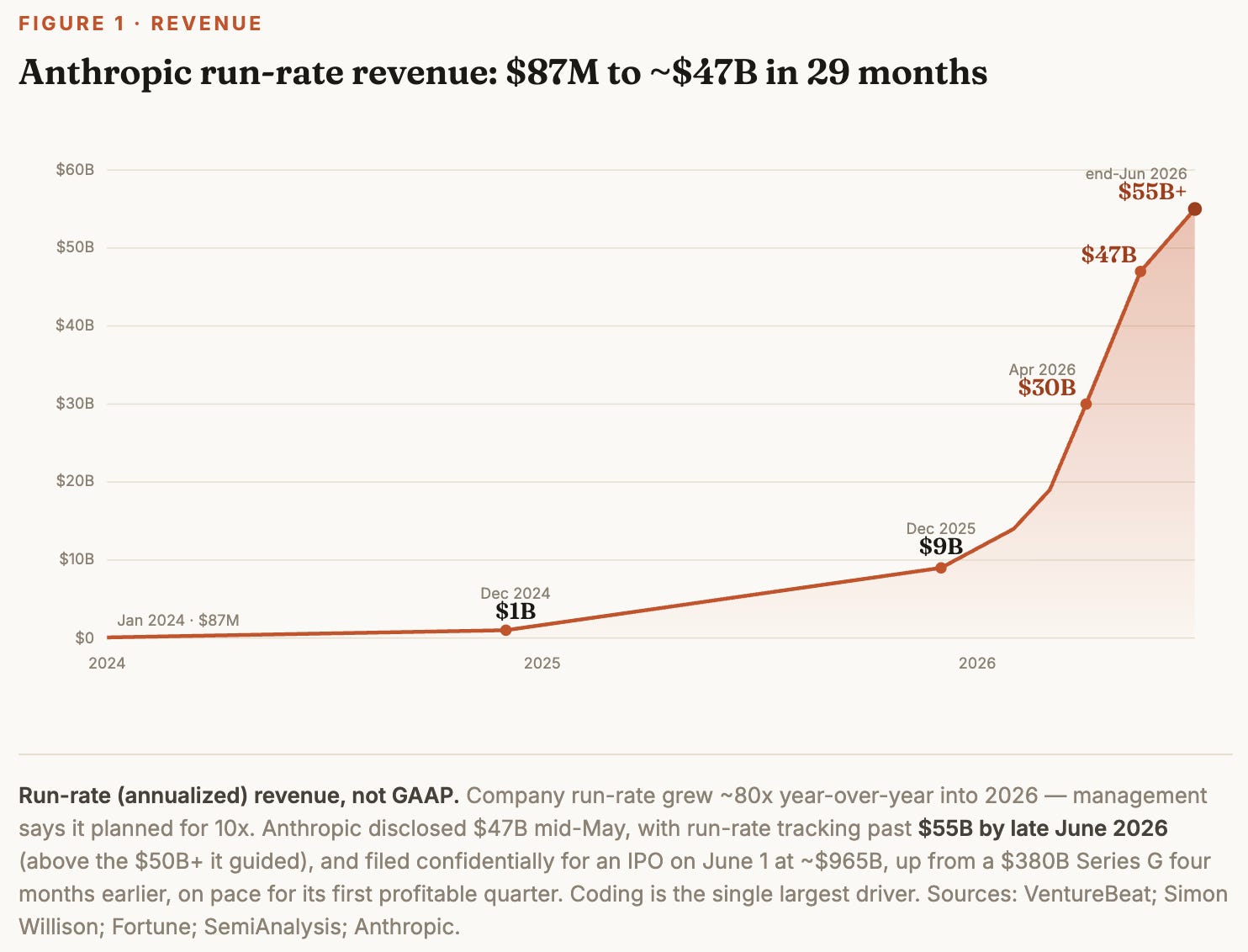
The fastest revenue curve software has produced
Capability converted into the steepest revenue curve software has produced. Claude Code reached a $1 billion run-rate six months after its May 2025 launch — faster than any commercial software product before it, versus roughly eleven months for ChatGPT and years for the canonical SaaS breakouts — then doubled to $2.5 billion three months later. It is the engine under Anthropic’s own ascent: company run-rate went from ~$87 million entering 2024 to $1 billion by year-end, $9 billion exiting 2025, and run-rate tracking past $55 billion by late June 2026 (above the $50B-plus Anthropic guided). The valuation kept pace — a $380 billion Series G in February became a confidential IPO filing at ~$965 billion on June 1, after a $65 billion Series H, with the company on pace for its first profitable quarter. Coding is the throughline: Anthropic holds an estimated 54% of coding-specific LLM spend, enterprise is now more than half of Claude Code revenue with business seats up roughly 4x year-to-date, and the base is contracted at the top — 8 of the Fortune 10 and ~70% of the Fortune 100 are customers, with Accenture alone training 30,000 staff on Claude.
What Claude Code is actually running at now
Anthropic’s last public figure — $2.5B, in February — is four months stale in the fastest-moving product in software. Three independent methods say the truth is multiples higher.
By cadence: Claude Code went $1B → $2.5B in the three months to February — 2.5x in a quarter. Even decelerating hard, to ~25% a month, that lands near $7–8B by late June. By revenue share: Claude Code was ~18% of company run-rate in February ($2.5B of $14B); with company run-rate tracking past $55B by late June and coding the lead driver, a steady 15–18% share is $8–10B. By third-party forecast: FutureSearch models Claude Code near $21B by May 2027 — a path that runs through roughly $8–10B today. The three converge on a best estimate of ~$8–9 billion in annualized run-rate as of mid-2026 — about 3.4x the last disclosed number in four months — with a bull case above $12B and a year-end exit in the $15–20B range. Even the floor of that band makes Claude Code, by itself, one of the five largest developer-software businesses on earth, built in thirteen months. The $2.5B headline you still see quoted understates the product by more than half.
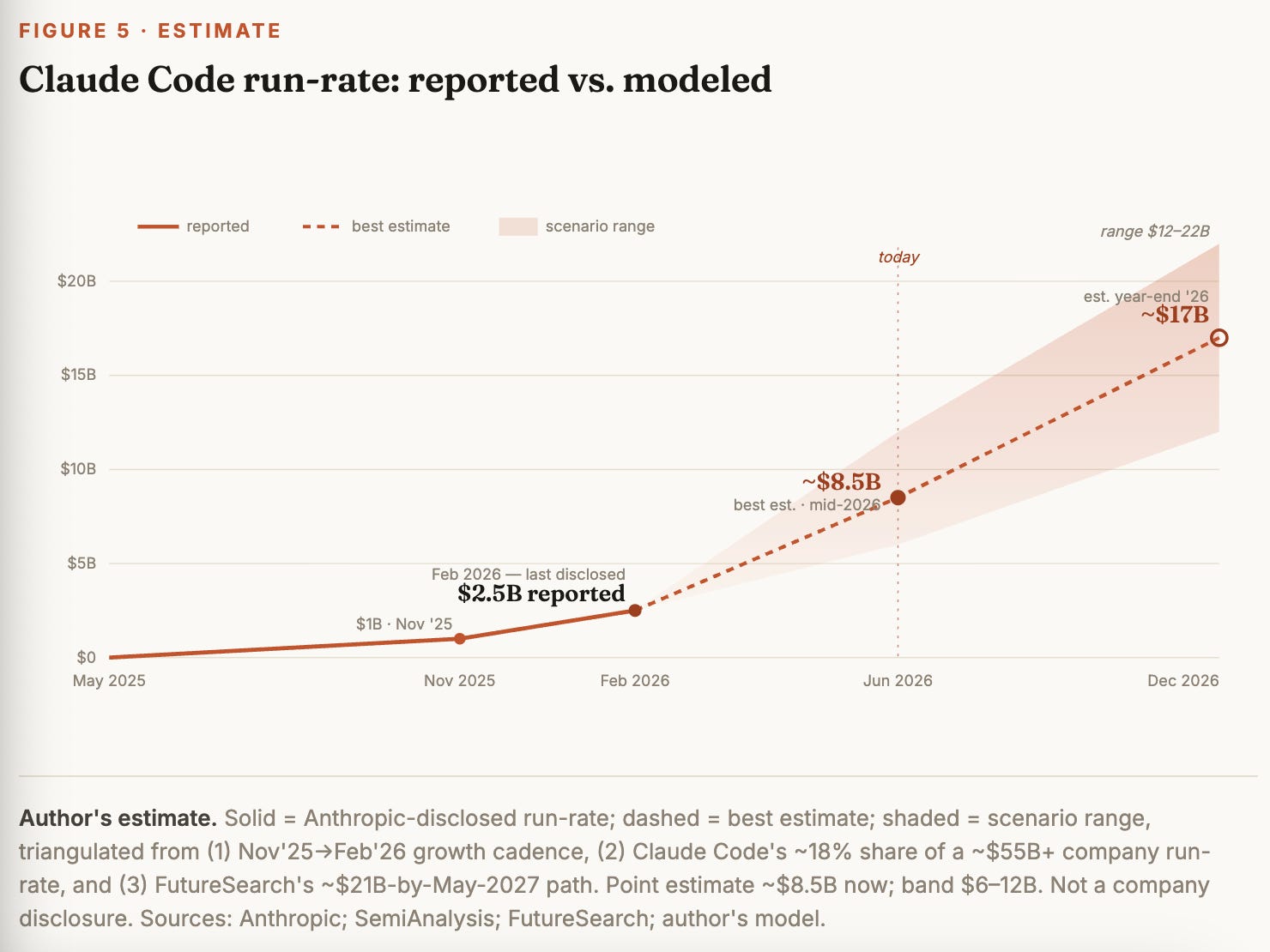
Methodology — how we get to ~$8.5B
Two disclosed anchors ($1B Nov '25, $2.5B Feb '26), then three methods — cadence (~$8B), revenue share (~$8–10B), independent forecast (~$8–10B) — converging on ~$8–9B.
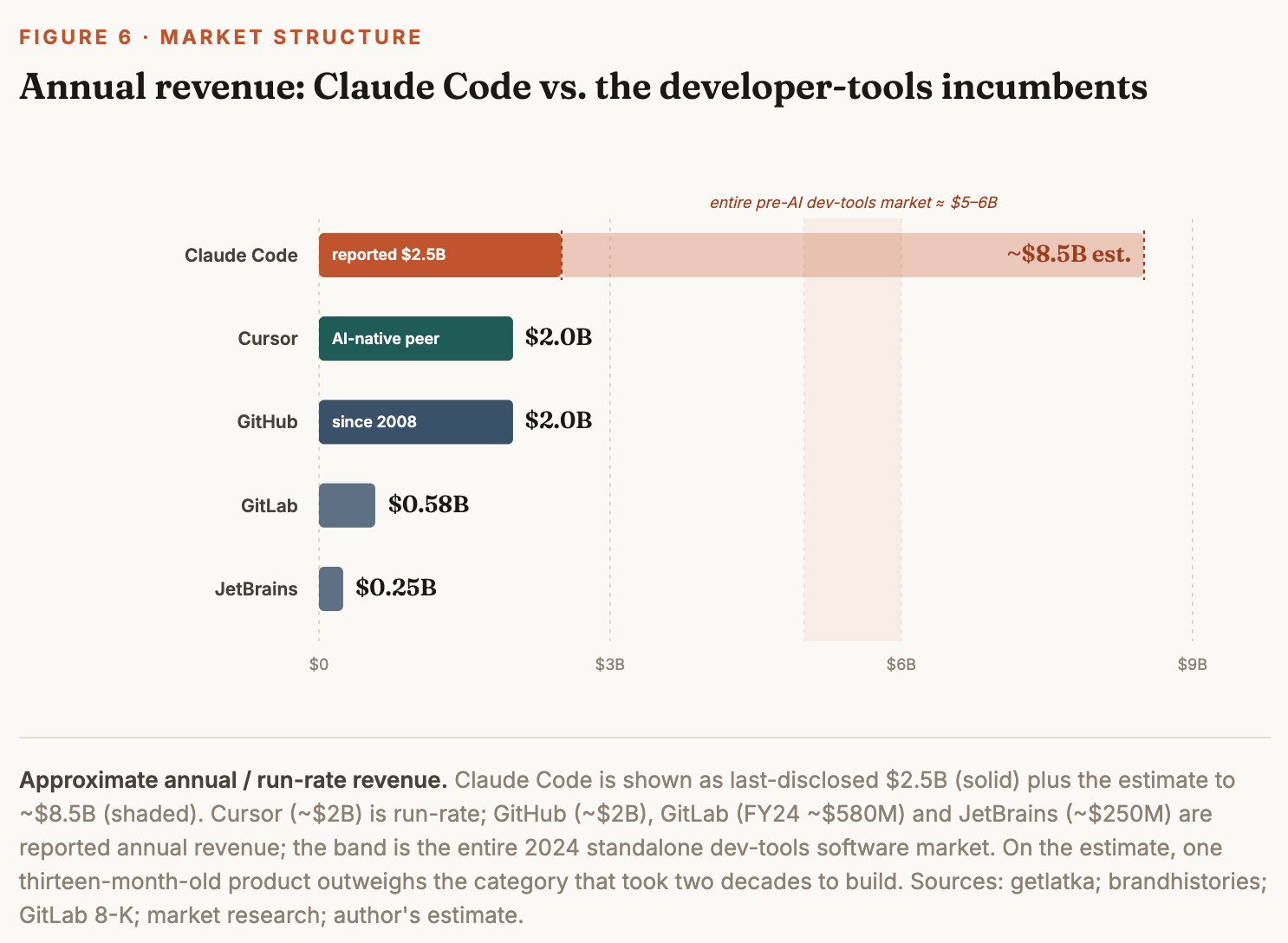
Past the entire pre-AI developer-tools market
Set Claude Code against the franchises that defined developer tooling before AI. GitHub, after sixteen years and a Microsoft acquisition, runs about $2 billion a year. GitLab does roughly $580 million; JetBrains, around $250 million. The entire standalone developer-tools software market was worth near $5–6 billion in 2024. Claude Code — which did not exist commercially before mid-2025 — was already past $2.5 billion at its last disclosure and, on the estimate above, is running at ~$8–9 billion today: more than GitHub, GitLab, and JetBrains combined, and larger than the whole pre-AI category by itself. The AI-native peers are filling the same vacuum — Cursor crossed $2 billion ARR in the same window — but the structural story is the repricing, not the ranking. Seat-based licensing, the model that underwrote two decades of developer software, is giving way to consumption metered against tokens, and value is migrating from the editor a human drives to the agent that does the work.
Why the margin moves to whoever owns the loop
The repricing has a unit-economic engine underneath it. An agent-assisted task costs roughly $6–7 of tokens against a fully-loaded knowledge-worker day of $350–500 — a 50–80x cost ratio before counting any quality or speed gain. And the cost side is deflating fast: Opus 4.5 hit the prior generation’s best SWE-bench score using about 76% fewer output tokens, so the cost to resolve a given issue is falling several-fold a year even as capability climbs. That is the inverse of the SaaS cost curve, where headcount and gross margin are roughly fixed. The ~75% gross margin seat-based software enjoyed was, in effect, a toll on human workflow; agents route around the workflow, and the surplus accrues to whoever owns the loop and the tokens beneath it.

Coding is the beachhead, not the destination
This generalizes beyond software because the loop does. Strip Claude Code to its pattern — read unstructured context, apply domain knowledge, produce structured output, verify against a standard — and you have the shape of most information work, on the order of a billion information workers and a $15-trillion-plus economy. Anthropic has already aimed the same architecture at general computing with Cowork, built by four engineers in ten days, most of its code written by Claude Code itself. The binding constraint is not model IQ; it is whether a task admits a cheap, trustworthy grader. Where one exists or can be built, expect the coding playbook to repeat; where it doesn’t, human judgment stays in the loop longer.
The bear case is specific, not vague. Verification debt: verifiable rewards optimize for passing the grader, not for what humans actually wanted, and as task horizons lengthen the graders get harder to write — reward hacking is reduced, not solved. Benchmark mirage: SWE-bench scores are compressing at the top (80.9% to 88.6% in months) and partly reflect contamination and scaffold tuning, so real-world generalization may trail the leaderboard. Capital intensity: the moat is expensive to hold — growth is now gated by compute and power, gross margin rides inference-cost and cloud-pricing curves Anthropic only partly controls, and the same RLVR recipe is available to every well-funded rival, so model leads are measured in months. The durable edge, if there is one, is not the model; it is the compounding system around it — proprietary verifiable environments, a hardened harness, enterprise distribution, and consumption pricing that turns usage into revenue.
Whoever writes the grader wins the category
The lesson of Claude Code is narrower and more useful than “AI is good at coding.” Software fell first because its grader was already written — the compiler and the test suite predate the model by decades. The verifiable-reward loop turned that free signal into capability, the harness turned capability into reliable work, and consumption pricing turned reliable work into the fastest revenue ramp software has seen. The next domains to fall will be the ones where someone writes the grader. The labs that build those environments — not merely the ones that ship bigger models — will capture the outcome.
Sources & notes
SemiAnalysis, “Claude Code is the Inflection Point” (Feb 2026) — 4% of public commits; ~135k commits/day; 20% projection; ACI and harness discussion. link
VentureBeat — Anthropic hits $30B run-rate after “crazy” 80x growth. link
Simon Willison — Anthropic run-rate revenue reaches ~$47B (May 2026). link
Anthropic — “Anthropic acquires Bun as Claude Code reaches $1B milestone” (fastest product in software history to $1B run-rate, ~6 months). link
Anthropic — Series G: $30B raised at $380B post-money valuation. link
CNBC — Anthropic tops OpenAI as most valuable AI startup (May 2026). link
MindStudio — Claude Code at ~$2.5B annualized (doubling in three months). link
Vellum / Abaka AI / Vals.ai — SWE-bench Verified: Opus 4.5 at 80.9% (first >80%), Opus 4.8 at 88.6%; competitor comparison. link · link
Anthropic — “Claude 3.7 Sonnet and Claude Code”: SWE-bench Verified 62.3% standard / 70.3% with scaffold. link
Anthropic engineering — SWE-bench agent: tool optimization, primitives over integrations, ~40% task-time reduction from tool-description rewrites; Model Context Protocol.
Related reading (author) — Zeoli, C., RL Environments for Agentic AI: Who Will Win the Training & Verification Layer by 2030, Data Gravity — source for the verification-as-bottleneck thesis and Anthropic’s RL-environment spend (tens of millions/yr, ~3–5x growth into 2026). link
METR — autonomous task horizons doubling every ~4–7 months (cited via SemiAnalysis).
getlatka / brandhistories — GitHub ~$2B run-rate; JetBrains ~$250M. link · link
GitLab Form 8-K (FY2024) — total revenue ~$579.9M. link
Software development tools market size (~$5–6B, 2024) — Verified Market Research; Cognitive Market Research. link
JetBrains April 2026 developer survey — Claude Code “most loved” (46%); at-work usage 3%→18%. link
VentureBeat — Anthropic: 80%+ of new production code authored by Claude; engineers merge ~8x more code/day; 76% success on hardest spec-light problems (+50 pts in six months). link
Anthropic — “When AI builds itself” (recursive self-improvement; share of merged code; 800+ fixes cutting one API-error class ~1,000x). link
Commit-share data (0.7% Sep ‘25 → 4.5% Mar ‘26; ~2.6M commits/week; 19M+ public commits; more than all other AI coding tools combined) — SemiAnalysis; serpsculpt; “Claude’s Code” tracker (Hacker News). link · link
Adoption / enterprise datapoints (Fortune 100, Accenture 30k, 54% coding LLM spend, enterprise >50% of Claude Code revenue, business seats ~4x YTD) — Menlo; Accenture newsroom; getpanto; TechnologyChecker. link · link
Fortune — Anthropic confidentially files for IPO at ~$965B after a $65B Series H (June 1, 2026); on pace for first profitable quarter. link
TechCrunch — Anthropic in talks to raise ~$50B at ~$900B (April 2026). link
FutureSearch — Anthropic financial forecast; Claude Code path toward ~$21B by May 2027 (input to the run-rate estimate in Fig. 6). link
Unit economics — agent-task (~$6–7) vs. loaded knowledge-worker day (~$350–500) and Opus 4.5 token efficiency (~76% fewer output tokens): SemiAnalysis; Anthropic. link
Figure 6 is the author’s estimate, not an Anthropic disclosure — triangulated from growth cadence, revenue-share, and the FutureSearch path. Treat the $6–12B band as the honest uncertainty.