

Meta's AI Initiatives: $20B+ of Investment in GPUs and Data Center Infra
Discussing the winners from Meta's $20B+ of data center investment to train the next generation of Llama models and power Facebook family of AI apps

In a unique way to announce huge AI initiatives, Mark Zuckerberg posted an Instagram Reel discussing Meta’s 2024 plans. The two main areas of announcements came in data center compute infrastructure and training its next-gen model Llama 3.

Zuck announced 350K H100s by the end of the year and almost 600K H100s equivalents if you include other GPUs — presumably 250K of either AMD or internal chips developed in-house. Perhaps Meta becomes the first mega customer of AMD in the data center that chips away at Nvidia’s monopoly. We highlighted Meta’s role as tied for Nvidia’s largest customer with Microsoft with 150K GPUs — this announcement represents a 4X step up from the last publicly disclosed figure!

For a typical DGX deployment with 8 H100 GPUs, the for the full stack of components is $269K per SemiAnalysis. ~73% of the total cost for an AI server is in these GPUs, with the rest split across SmartNICs, Memory, CPU and Storage. This doesn’t include networking which we dive into later.
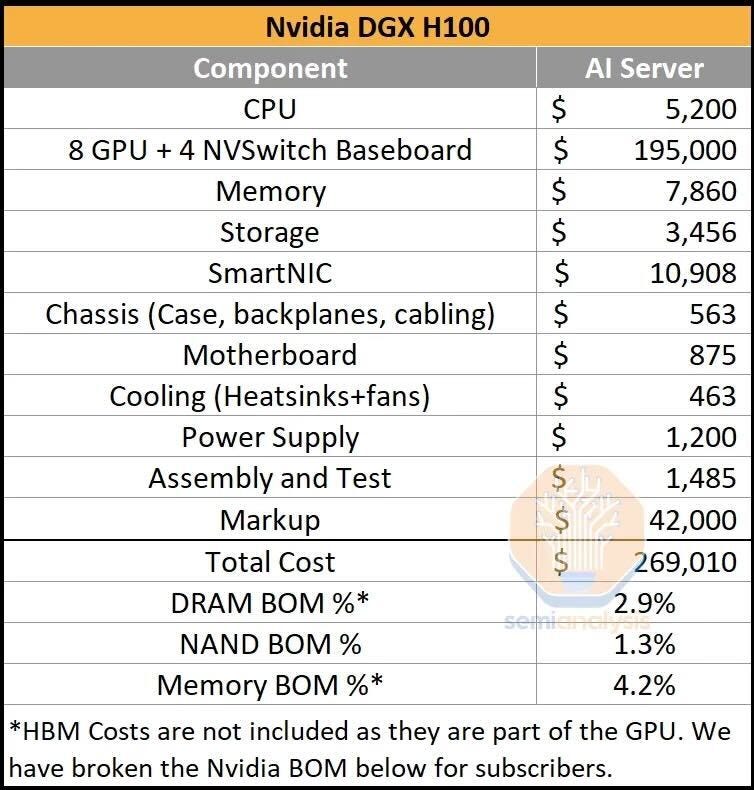
Source: Semi Analysis
Thus, at 600,000 total H100 equivalents (assuming similar cost for the 250K non Nvidia H100 chips) we approximate a total GPU server investment of $20.2B! This excludes networking and operating costs of the data center which we dive into later. Together, the facilities and networking would more than double the total investment Meta is making in total data center infrastructure to over $50B by using standard data center operating expenses.

Source: Nvidia earnings report
For reference, last year Meta’s biggest cost was research and development where it allocated ~$36B. Thus, this announced data center investment is 1.5 years of R&D — a sign of the growing important of compute and data center for AI-first tech companies. This data center investment is a 4X+ stepup in total GPUs for Meta — a massive win for open-source AI as well as a number of players in the GPU and data center supply chain. We discuss the winners below:
Winner’s from Meta’s Data Center Investments
GPUs:
🥇 Winner: Nvidia — NVDA 0.00%↑

Zuck states that 350,000 of the 600,000 total GPUs will be H100s, representing $11.8B of total revenue for Nvidia alone — excluding networking! He explicitly states Nvidia H100s will be ~60% of total GPUs that Meta uses in the next year. Though this is the vast majority of Meta’s GPUs, 60% would be significantly lower than Nvidia’s current market share of 92% of data center GPUs — suggesting Meta is optimistic on diversifying their supply chain and buying from other players.
🥈 Runner-up: AMD — AMD 0.00%↑

Meta is a significant AMD customer today and presumably the majority of the 250K other A100 equivalents going will be from AMD. While Nvidia’s market capitalization is 5X of AMD and its data center market share 50X smaller, AMD is expected to make big progress this year with a faster chip. Everyone in AI is hoping for this, as GPU competition is the biggest lever to reduce AI training and inference costs.
🥉 3rd place: Broadcom — AVGO 0.00%↑

JPM claimed in 2022 that Meta is paying Broadcom over $1B per year for its custom AI chip. Broadcom partners with Meta (as well as Google for its TPUs) for custom AI chip development. With this huge rise of chip investment and 250K A100 equivalents that are non Nvidia-based, we can assume internally developed chips with Broadcom will hit production this year.
Networking:
🥇 (TIE) Winner: Nvidia — NVDA 0.00%↑
Presumably, most of the 350K H100 GPUs that Meta purchases will include Nvidia’s Networking offerings via Mellanox Infiniband. For AI data centers, Nvidia estimates that for every $4 of GPU spend, customers spend ~$1 on Networking. Nvidia’s networking business surpassed $10B of annualized revenue, tripling year over-year.
🥇 (TIE) Winner: Arista Networks — ANET 0.00%↑

Arista likely will be deployed for most of the 250K non H100 GPUs discussed (particularly the AMD GPUs) and is a big beneficiary from AI networking. In 2022, Meta spent $1.2B on Arista Networks for its networking solutions and represented ~25% of Arista’s revenue that year — 2nd place customer being Microsoft at 15-20% of total revenue. Meta relies on Arista for its networking to run Facebook, Instagram, Whatsapp and other properties. Arista will continue to benefit if more data center GPU market share disperses from Nvidia. We will do a follow up piece on Arista Networks in AI networking. No surprise the $80B+ networking vendor saw its stock rise 5% on this announcement.
🥈Runner-up: Broadcom — AVGO 0.00%↑
As discussed earlier, Meta is spending over $1B per year on internal chip development with Broadcom and also using Broadcom for networking components. Broadcom is Meta’s third largest networking partner. If Meta’s internal chip takes off, we can expect Broadcom’s networking to be used alongside this.
Facilities/Power:
🥇 Winner: Eaton — ETN 0.00%↑
Nvidia estimates that 50% of AI data center spend is on facilities, power and operations. While Meta owns and operates most of its own data centers, it does work with third-party firms for power management, backup solutions and uninterruptible power supplies. Eaton is the largest of these partners per prior reports. Perhaps surprisingly, Coatue (the leading tech hedge fund with $19.7B of market positions per its latest 13F) has an $810M position in Eaton — likely for its expertise in data center power management. Further, its 2nd largest position is Meta, with Nvidia as its largest and AMD at 4th — suggesting a strong focus on the semiconductor supply chain for AI.
Honorable Mentions:
Open-source AI

")
Meta has been a huge contributor to open-source AI. From my view, the single largest contributor having launched Pytorch and the leading open-source foundation model Llama. In September, Meta a significant announcement on the Llama family of models stating over 10M downloads in the last 30 days and 30M+ cumulative downloads. Llama is either the 2nd or 3rd most deployed foundation model behind OpenAI (distant) and Anthropic. With this investment in GPUs, Meta will have more compute than any foundation model provider — though Meta also has a variety of internal projects in addition to the Llama family of models.
Open-source foundation models and libraries like Pytorch are huge boons for the startup ecosystem and software applications that are crippled with huge AI costs for inference alone — let alone AI training.
CPUs: AMD (AMD 0.00%↑), Intel (INTC 0.00%↑)
While only $5.2K of the $269K costs of deploying an AI server components are CPUs, these are still significant. These additional 600K of GPUs will need approximately $400M of additional CPU investment. AMD recently became Meta’s largest CPU provider for data centers, for its high core counts and energy efficiency which are particularly valuable in AI. Meta also uses Intel for CPUs.
Memory and Storage: Samsung and SK Hynix
DRAM and flash memory are important components for high-speed data processing and data caching in AI workloads. Meta has previously announced working with Samsung and SK Hynix in these areas. We estimate ~$850M of marginal investment in DRAM memory and storage to service these data centers at $7,860 and $3,456 per DGX cluster.
Foundry: TSMC — TSM 0.00%↑

TSMC is perhaps the most important bottleneck of all. Its stock surged over 10% today after strong guidance of 20%+ revenue growth this year. TSM is the only supplier of Nvidia’s chips and the key supplier for AMD chips. Further, the Company also makes the other key components for AI data centers — partnering with ecosystem players like Broadcom and others.