A GPU is only as valuable as the fabric that feeds it — how copper, light, and silicon move trillion-parameter workloads, and where the durable margins accrue.
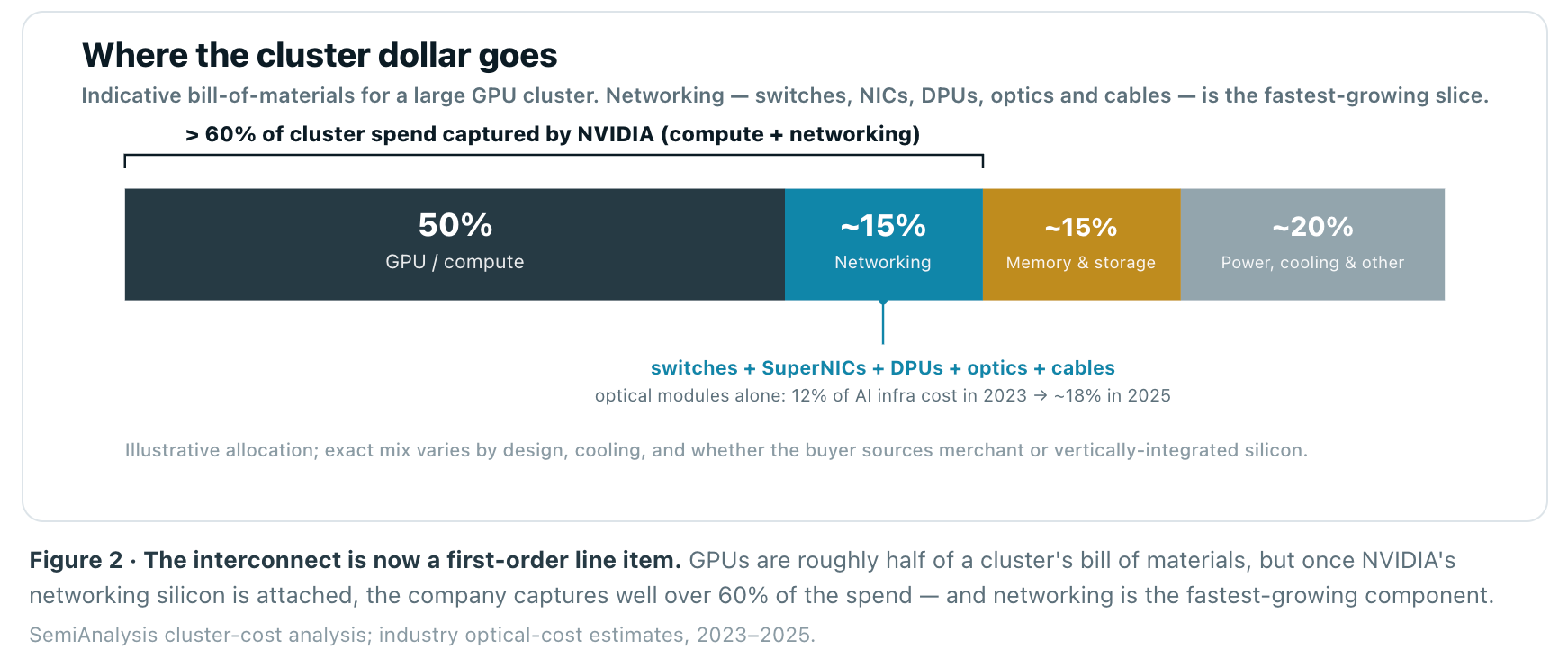
Compute got the headlines; the interconnect gets the margins. Networking is now 10–15% of cluster cost, a ~$60B/yr business for NVIDIA alone that’s tripling YoY. The durable value is concentrating in three places a GPU-centric view misses — transport software, upstream optical supply, and reliability at scale — while open Ethernet does to InfiniBand what it already did to Token Ring, FDDI, and Fibre Channel.
For a decade the AI narrative was a compute narrative. The scarce resource was FLOPS, the winner was whoever owned the accelerator, and the network was plumbing. That framing is now obsolete. In a modern AI factory, a single training job spans tens of thousands of GPUs that must behave as one machine, and the fraction of wall-clock time those GPUs spend waiting on each other — not computing — is set almost entirely by the network. The interconnect has become the second silicon.
Data Gravity is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
This piece maps the whole stack — the physical and logical layers that turn a warehouse of accelerators into a coherent supercomputer — and reads it the way an investor should. The consensus that networking is “the new moat” is directionally right but mispriced. The durable value is concentrating in three places a GPU-centric analysis tends to miss: the software that converts rated bandwidth into delivered bandwidth, the upstream optical supply chain everyone is capacity-constrained on, and the reliability layer that decides whether a 100,000-GPU run finishes at all. Compute is a spec sheet; the network is an operational outcome. Start with the map.
Figure 1 · The three domains of AI networking. Scale-up binds a handful-to-a-thousand accelerators into one memory space at terabytes/second over copper; scale-out lashes thousands-to-millions of GPUs into a cluster over optical Ethernet or InfiniBand; scale-across stitches AI factories together across buildings and metros. Each domain has a different physics, a different incumbent, and a different margin profile.
The Framework: Three domains, three physics, three markets
The single most useful mental model for AI networking is that there is no such thing as “the network.” There are three, nested like Russian dolls, and they are governed by different constraints. Scale-up is the innermost: it fuses a small number of accelerators into a single, coherent memory fabric where any GPU can read another’s memory in roughly 100 nanoseconds. Scale-out is the cluster fabric that connects those tightly-coupled islands into a machine of tens or hundreds of thousands of GPUs. Scale-across is the newest layer, connecting entire AI factories across buildings and metros as single sites run into power ceilings.
The reason this taxonomy matters commercially is that bandwidth, latency, and reach trade off against each other and against cost. Copper is nearly free and draws almost no power, but it dies at about two meters. Optics reach kilometers but burn watts and dollars per bit. The entire architecture of an AI supercomputer is an exercise in keeping the highest-bandwidth traffic on the cheapest, shortest, coolest medium — and pushing to light only when distance forces the issue. Follow the money, and it maps almost perfectly onto that physics.
Why It Gates Scaling: The utilization gap is a networking problem
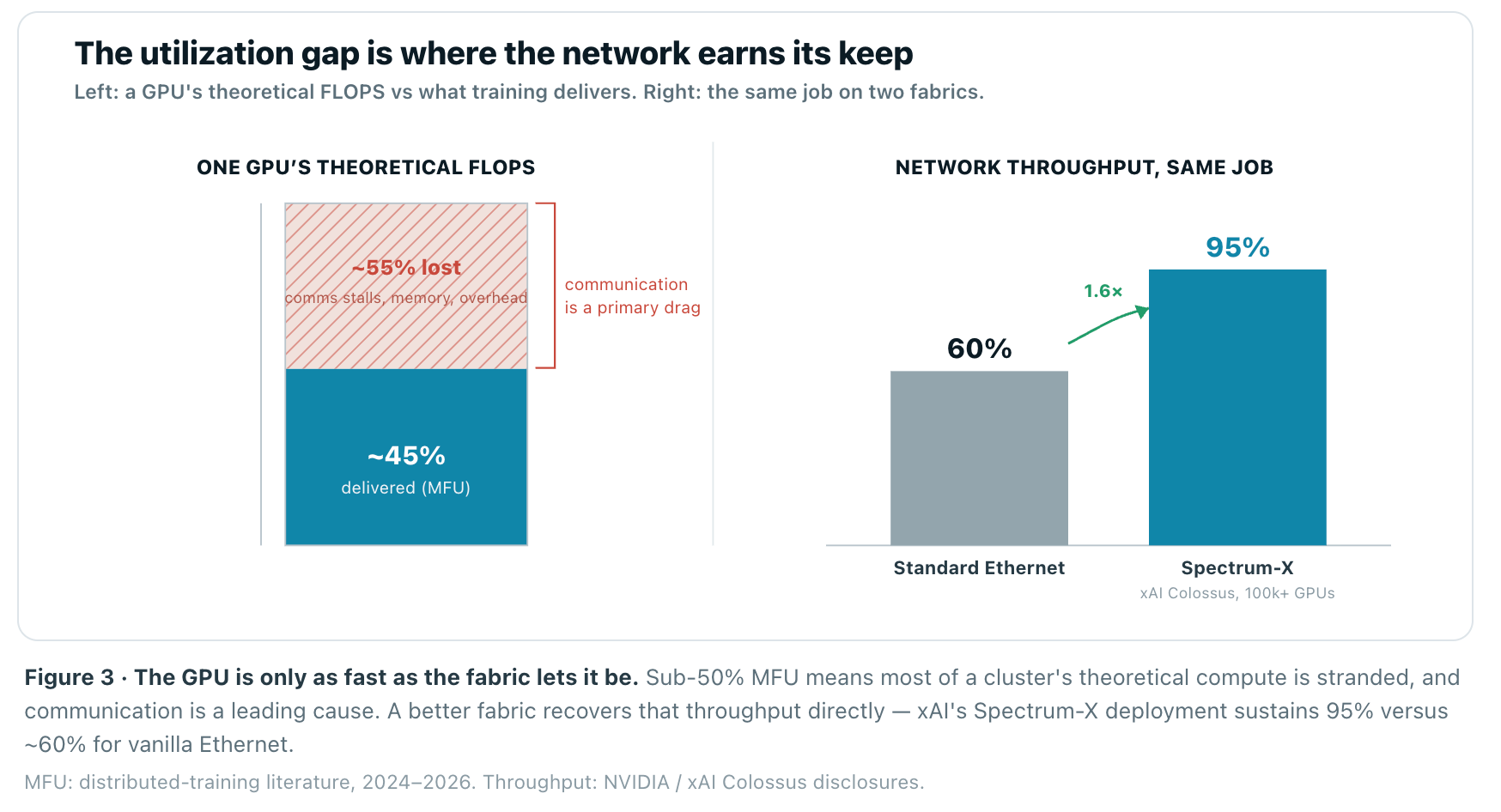
The reason the interconnect commands this share of spend is visible in a single metric: Model FLOPS Utilization, the fraction of a GPU’s theoretical throughput a real training run actually achieves. Frontier runs commonly sustain under 50% MFU — more than half of the silicon you paid for is idle at any instant — and communication is a primary culprit. As models shard across more GPUs and parallelism widens, the share of wall-clock time spent moving data rather than computing rises. Past a certain scale the network, not the accelerator, sets the ceiling. That is the whole reason scale-up bandwidth (NVLink) and lossless scale-out fabrics exist: to keep the compute fed.
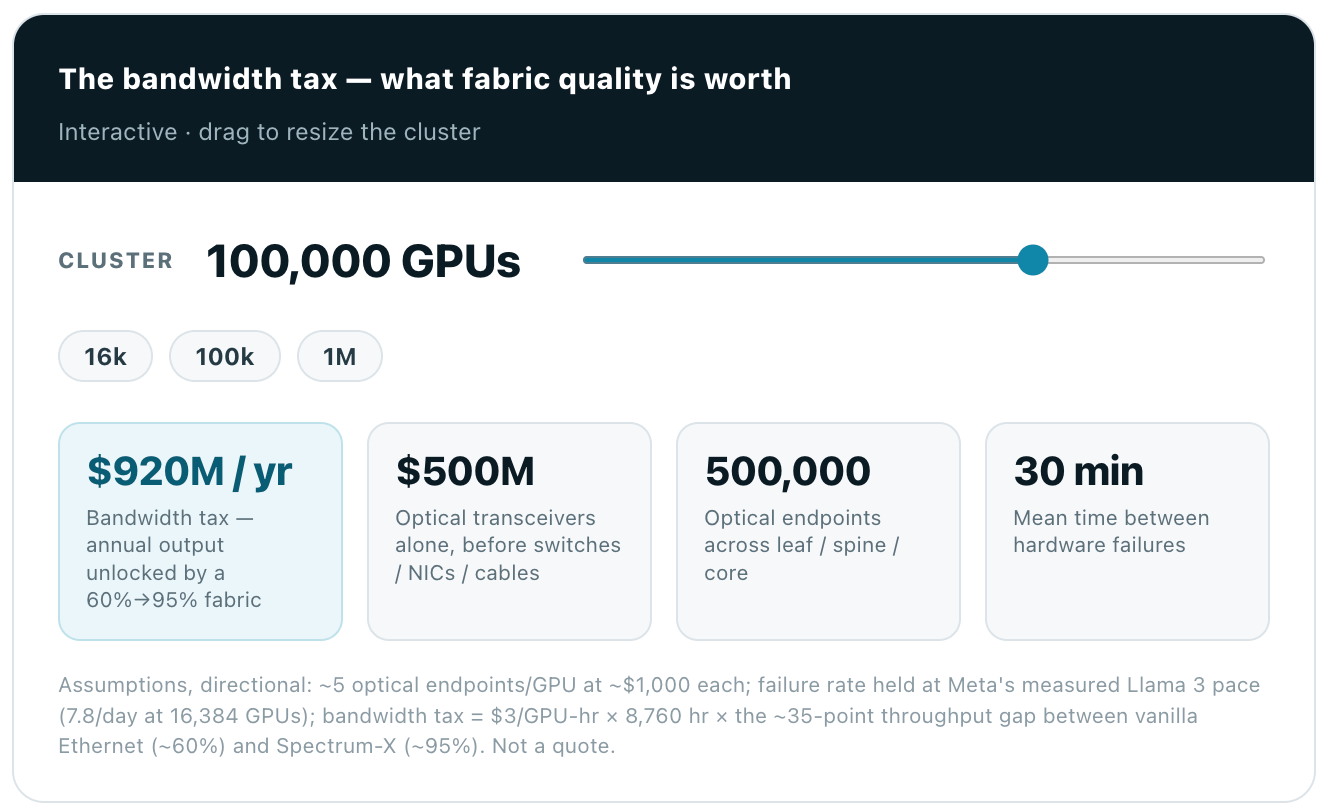
The proof is operational, not theoretical. When xAI built Colossus — 100,000 H100s, since expanded toward 200,000 GPUs including GB200 — on NVIDIA Spectrum-X, the fabric sustained 95% delivered throughput with zero flow-collision packet loss. NVIDIA pegs standard Ethernet at roughly 60% in the same role. That 60%→95% is a ~1.6× swing in effective bandwidth from the fabric alone — the difference between a GPU that earns and a GPU that waits. At a cluster costing tens of billions, that gap is the single highest-return line item in the building.
Scale-Up · The Memory Fabric: NVLink, NVSwitch, and the copper moat
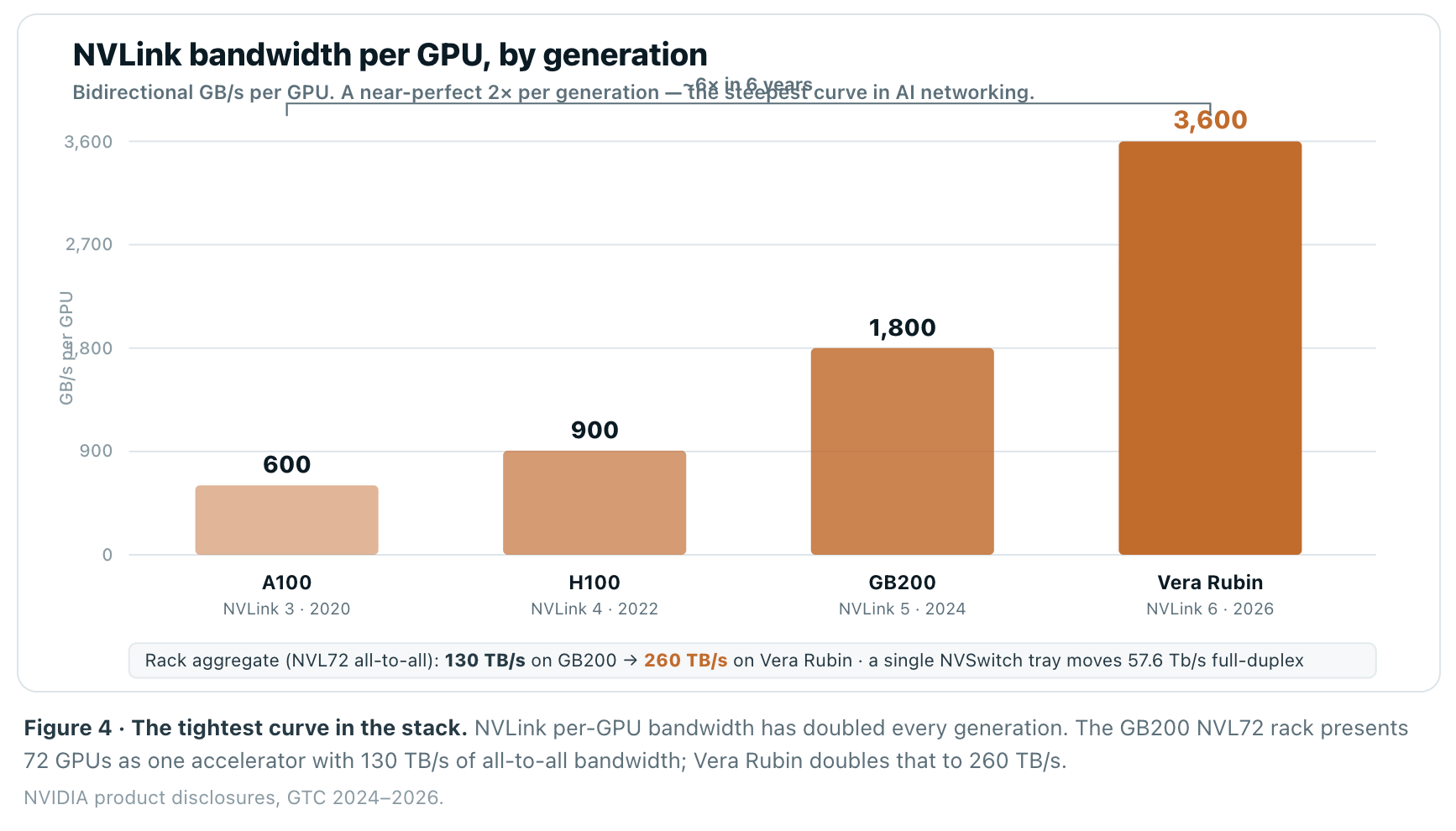
Scale-up is where NVIDIA is strongest and where the physics are most punishing. When a model is sharded across GPUs using tensor parallelism, those GPUs exchange activations on every layer of every forward and backward pass. That traffic is enormous, latency-sensitive, and must look to software like shared memory rather than a network. The answer is NVLink: a memory-semantic interconnect that today delivers 1.8 TB/s per Blackwell GPU — roughly 14× a PCIe Gen5 link — and rises to 3.6 TB/s per GPU on the Rubin generation shipping into 2026.
The trajectory is a clean doubling per generation, and it is the tightest performance curve in the entire stack. In six years NVLink per-GPU bandwidth has gone up roughly 6×, from 600 GB/s on the A100 to 3.6 TB/s on Vera Rubin. That is not incidental; it is the moat. Competitors can match a GPU’s FLOPS far more easily than they can match a rack that moves a quarter of a petabyte per second internally.
How that bandwidth is delivered is as important as the number. Inside a GB200 NVL72, the 72 GPUs and their NVSwitches are wired through a copper backplane carrying roughly 5,000 cables and over two miles of copper, presenting every GPU to every other GPU in a single hop. NVIDIA chose copper deliberately: doing the same job in optics would have required transceivers and retimers drawing an estimated ~20 kW per rack just to light the NVLink spine. Copper is the moat and the power budget.
The strategic question is whether that moat stays proprietary. Two forces are pushing back. The first is UALink, an open scale-up standard ratified in April 2025 at 200 Gb/s per lane and scaling to 1,024 accelerators per pod, backed by AMD, Intel, Google, AWS, Microsoft, Astera Labs and 85+ members — conspicuously, everyone except NVIDIA. The second is NVIDIA’s own NVLink Fusion, which opens the NVLink fabric to third-party CPUs and custom silicon from Qualcomm, Fujitsu, Marvell and MediaTek. NVIDIA would rather rent its fabric to challengers than let them standardize around an alternative. That is a classic control-point defense.
Adjacent: the memory fabric (CXL)
A fourth fabric is forming alongside compute — for memory. CXL (read “What is CXL?”) lets a rack pool and share DRAM instead of stranding it in each server, attacking the “memory wall” that increasingly bounds inference. CXL 4.0, ratified in November 2025, carries up to 1.5 TB/s on bundled links; memory-pooling deployments target 2026–27, with early benchmarks showing ~20× gains for graph workloads and ~70% for recommendation models. It is the least mature domain — adoption is gated on orchestration and security, not silicon — but if memory disaggregation lands, it becomes a memory-semantic fabric with its own control points. Astera Labs’ Leo controllers are the merchant enabler to watch.
Scale-Out · The Fabric War: InfiniBand’s monopoly is breaking
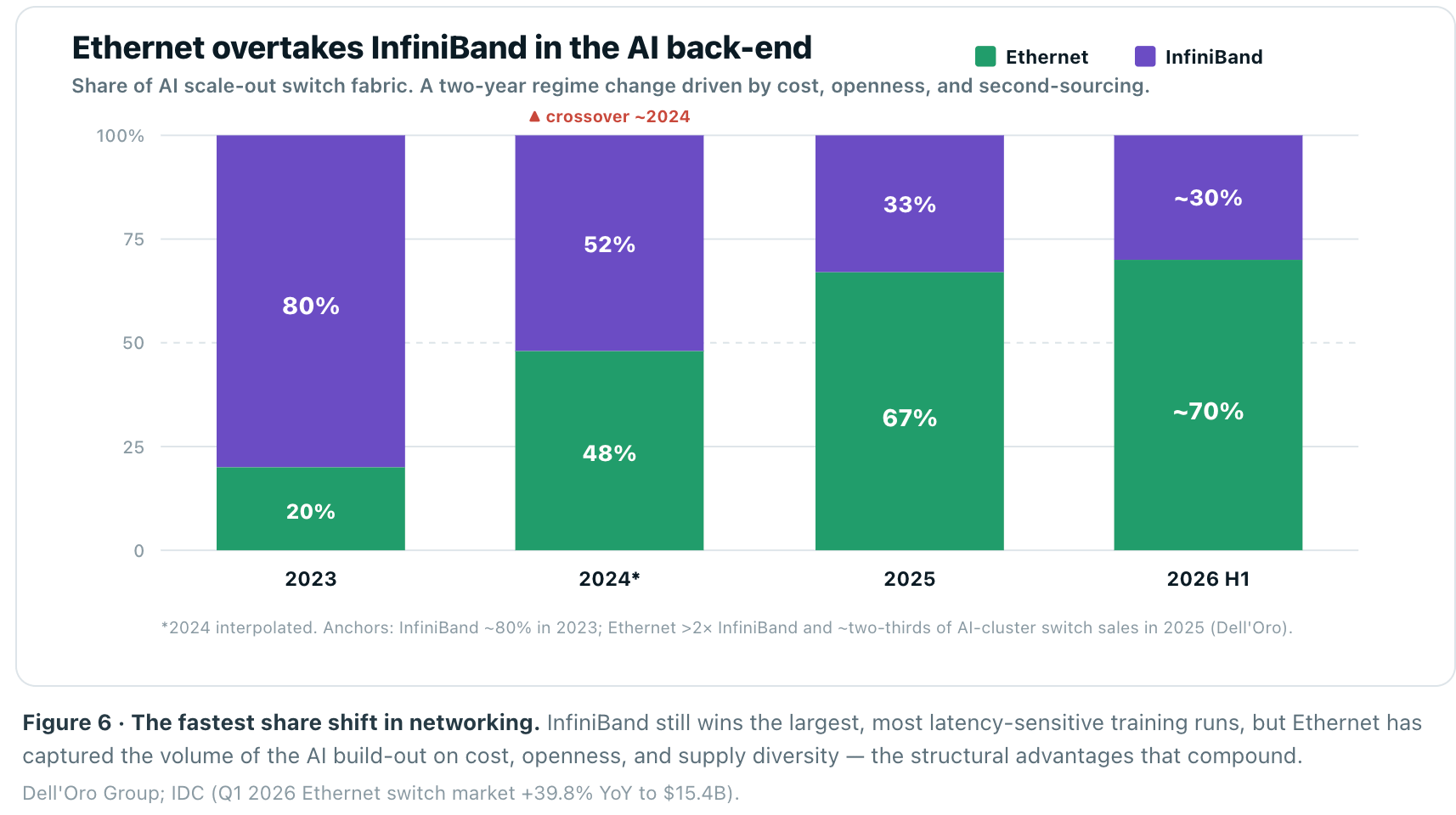
Once a workload outgrows a single rack, it moves onto the scale-out fabric, and here the story of the last eighteen months is a genuine regime change. As recently as 2023, InfiniBand held roughly 80% of AI back-end networking. It earned that share honestly: InfiniBand is lossless by design, offloads collective operations into the switch via SHARP, and comes pre-integrated with NVIDIA’s stack. For frontier training, it remains the reference platform.
But Ethernet has flipped the market. In 2025, Ethernet more than doubled InfiniBand as the leading fabric for AI scale-out, and by Q4 2025 through Q1 2026 it accounted for roughly two-thirds of switch sales into AI clusters. IDC pegged the datacenter Ethernet switch market at $15.4B in Q1 2026, up 39.8% year-over-year, with NVIDIA — not Arista or Cisco — now ranked #1 by revenue on the strength of Spectrum-X. Amazon, Microsoft, Meta, Oracle and xAI are all building on Ethernet.
This shift has a precedent that should unsettle InfiniBand’s defenders: Ethernet has won this exact fight before, repeatedly. Token Ring, FDDI, ATM, and Fibre Channel each offered a real technical edge behind a proprietary or premium model — and each ceded the volume once Ethernet became merely “good enough” and far cheaper. Open, ubiquitous, and cost-declining beats fast-but-closed on a long enough timeline. InfiniBand is the current chapter, not an exception to the pattern.
InfiniBand’s most durable technical advantage is in-network computing. Collective operations like all-reduce — where every GPU must sum its gradients with every other GPU’s — are the heartbeat of distributed training, and they overwhelm a naively-built network. NVIDIA’s SHARP protocol moves the summation into the switch: instead of shuttling every gradient to every node, the switch aggregates as data flows through it. The result is roughly double the effective all-reduce bandwidth and up to 30% faster job completion on large runs. Ethernet’s answer — distributed, host-based collective libraries plus emerging in-switch offload — is closing the gap but is not yet at parity.
Topology · The Cost of Non-Blocking
Why the wiring diagram is a capital decision
A fabric’s logical shape matters as much as its silicon. Because training traffic is synchronized and all-to-all, any bottleneck anywhere stalls the collective, so large clusters are built as rail-optimized fat-trees: each GPU’s network port is mapped to a dedicated “rail,” so the same-index GPUs that must all-reduce together stay on a single leaf and avoid extra switch hops. This is the reference design at 16,000–100,000+ GPU scale across Meta, Microsoft, and NVIDIA’s own SuperPOD.
The expensive constraint is oversubscription. A training east-west path must be 1:1 non-blocking — any oversubscription stalls NCCL — which means the fabric has to carry every GPU’s full line rate at once. A non-blocking three-tier fat-tree roughly triples switch and optics count versus the oversubscribed networks enterprises tolerate, and that is precisely why networking is 10–15% of cluster cost rather than 2–3%. Topology is not an engineering detail; it is the mechanism that converts the physics of collectives into capital intensity.
The Silicon · Switches, NICs, DPUs
Where bandwidth is concentrated and offloaded
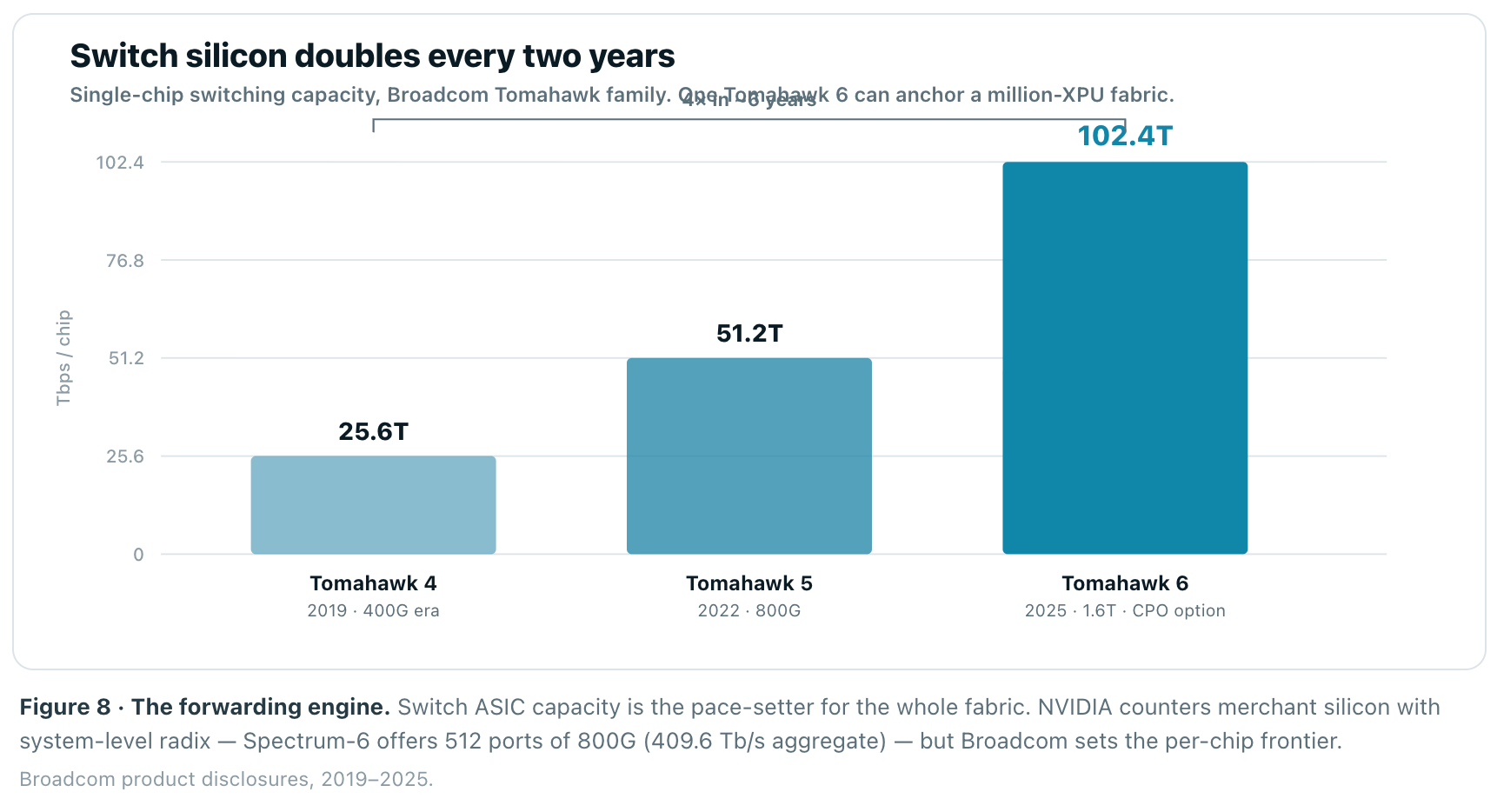
Underneath the protocol wars sits the silicon that actually forwards packets, and it is doubling on a metronome. The switch ASIC is the concentration point of the entire fabric, and Broadcom’s Tomahawk 6, shipping since June 2025, is the first to reach 102.4 Tbps on a single chip — double its predecessor, enough to wire a cluster of more than one million XPUs, with support for both 100G and 200G SerDes and optional co-packaged optics. The cadence is a clean 2× every two years, and it is the reason port speeds march from 800G today to 1.6T by 2027 and 3.2T by 2030.
This is where the merchant-versus-vertical split matters. Broadcom (Tomahawk, Jericho) and Marvell sell switch silicon to everyone; NVIDIA integrates Spectrum-X Ethernet and Quantum-X InfiniBand into its own systems. Broadcom’s combined AI revenue — custom accelerators plus networking silicon — ran $8.4B in Q1 FY26 (+106% YoY), $10.8B in Q2 (+143%), with guidance to ~$16B in Q3. The hyperscalers are deliberately funding a merchant alternative to keep NVIDIA honest.
At the edge of every server, the humble NIC has become a computer in its own right. NVIDIA’s ConnectX-9 SuperNIC delivers 800 Gb/s per port, and each Rubin GPU is paired with 1.6 Tb/s of scale-out bandwidth. But the more consequential shift is the rise of the DPU — a data-processing unit that offloads networking, storage, security and telemetry off the CPU and GPU entirely. NVIDIA’s BlueField-3 already does the work of roughly 300 CPU cores at ≤150W; BlueField-4, launching in 2026, adds 800 TOPS of on-die inference at 800 Gb/s. AMD’s Pensando Pollara 400 AI NIC and Salina DPU give the buyer coalition a credible second source.
Congestion Control · The Invisible Bottleneck
Why rated bandwidth and delivered bandwidth diverge
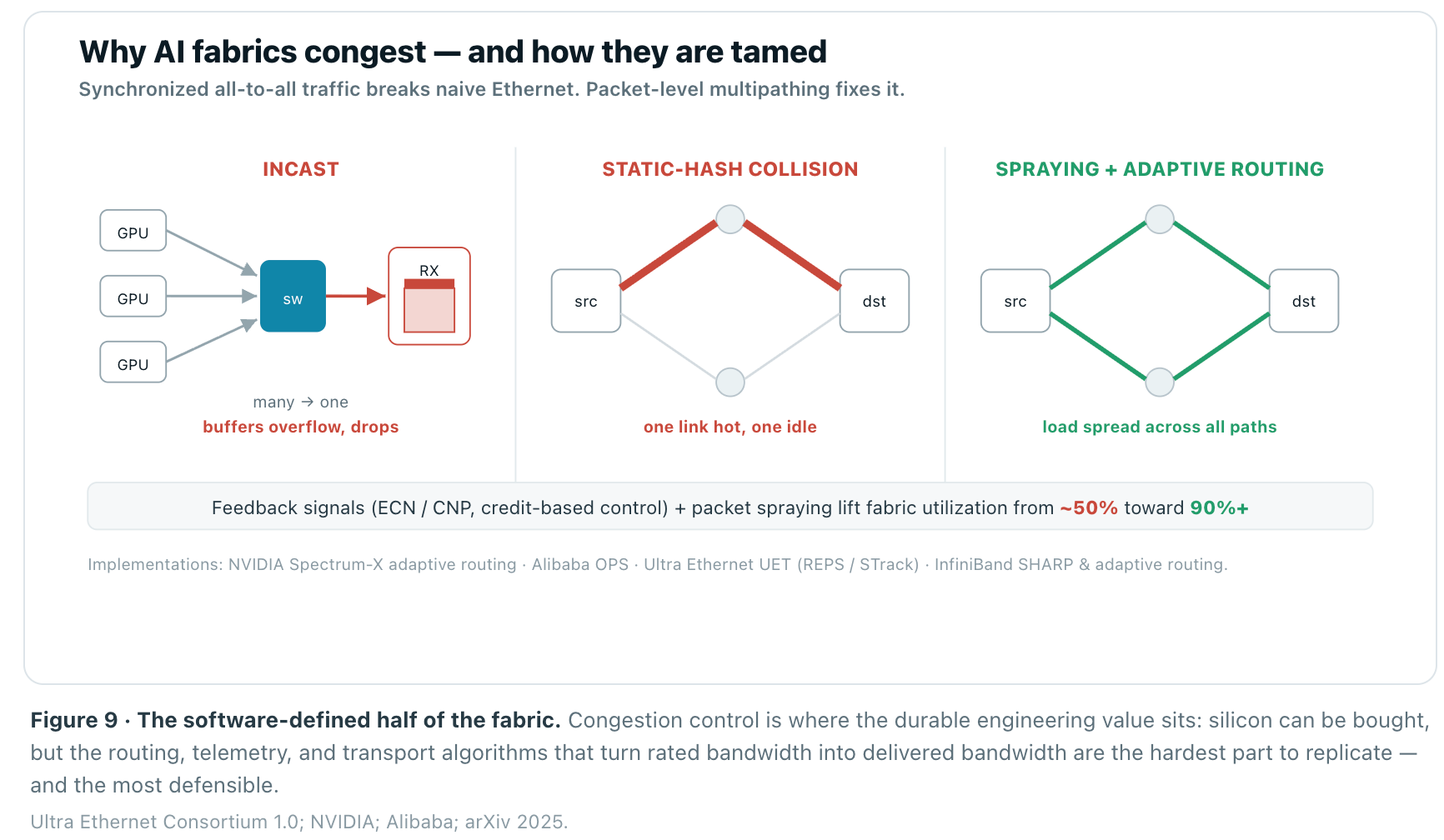
Here is the layer that separates a fabric’s spec sheet from its real performance. AI traffic is unlike anything Ethernet was designed for: it is synchronized, it moves in enormous “elephant” flows, and in a collective operation thousands of GPUs talk all-to-all at once. Two pathologies follow. Incast — many senders hitting one receiver at the same instant — overflows switch buffers and drops packets. And because classic Ethernet load-balancing hashes each flow onto a single path, a handful of elephant flows routinely collide on the same link, leaving it saturated while parallel links sit idle. In a collective, the slowest path sets the pace for all of them, so tail latency is job latency.
The fixes are the real intellectual property of modern AI networking. Lossless RoCEv2 uses ECN and priority flow control to signal congestion before buffers overflow. But the decisive move is packet spraying — per-packet load balancing that sprays a single flow across every available path — combined with adaptive routing and reorder-tolerant transport. NVIDIA’s Spectrum-X does this in hardware; Alibaba runs Oblivious Packet Spraying; and the Ultra Ethernet Consortium’s UET transport builds packet spraying and credit-based incast control into the standard. Done well, this lifts effective fabric utilization from roughly 50% toward 90%+ — a direct multiplier on the return of every GPU in the building.
Reliability · The Tail That Stalls the Job
At scale, the network’s job is to keep the run alive
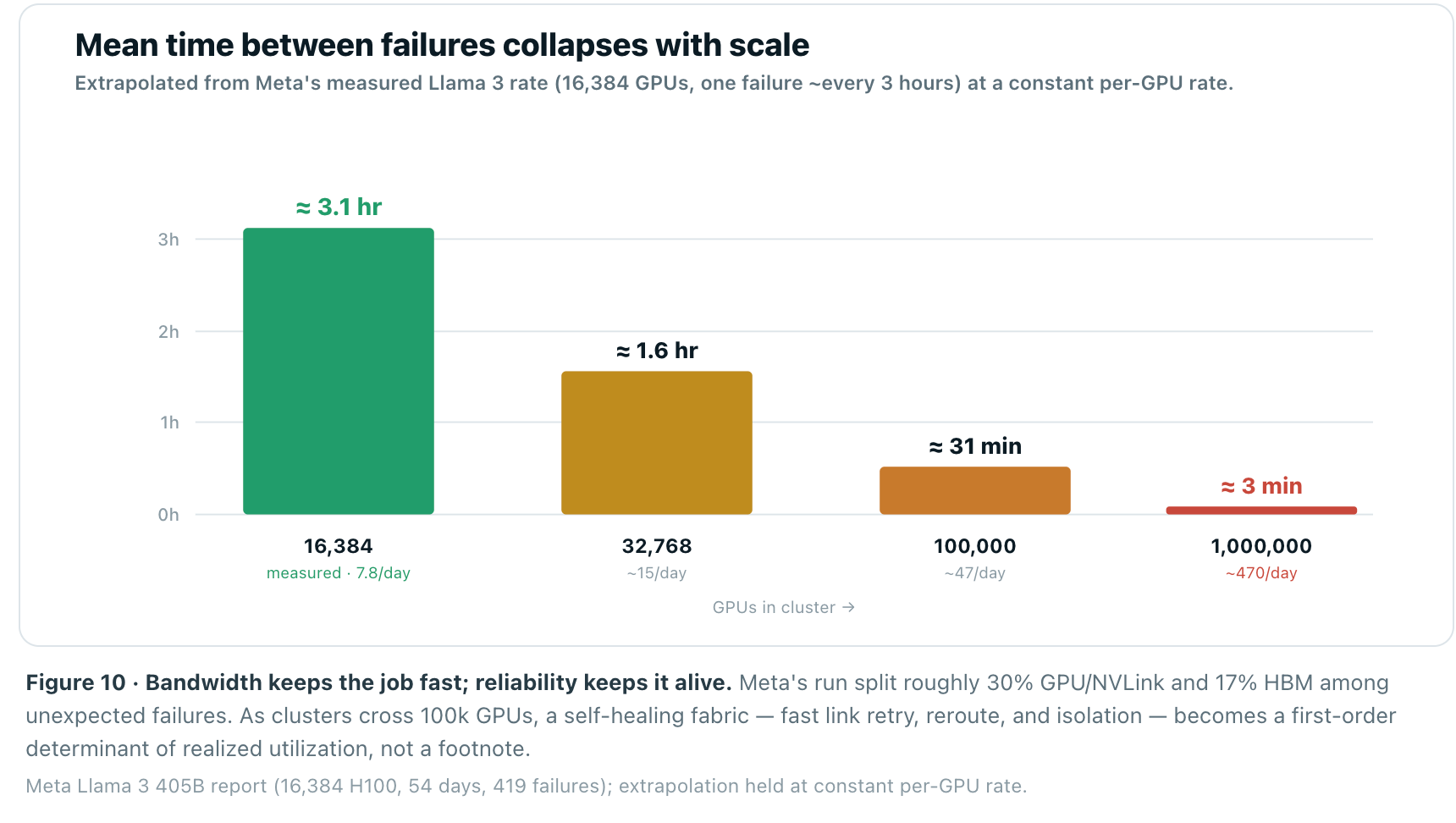
There is a failure mode that never appears on a spec sheet yet dominates real economics. At scale, hardware breaks constantly, and synchronous training is brutally intolerant of it. Meta’s public Llama 3 405B run — 16,384 H100s over 54 days — logged 419 unexpected failures, roughly one every three hours, with about half tracing to GPUs, NVLink, or HBM memory. Because the job is synchronous, a single failed GPU or link can halt all 16,384.
Failures scale with component count. Hold the per-GPU rate constant and a 100,000-GPU cluster faces an interruption every ~30 minutes; the million-GPU clusters now being planned face hundreds per day. Meta still achieved >90% effective training time — but only through relentless checkpointing and a fabric that can detect a bad link and reroute around it in hardware. This is why link-level retry, adaptive routing, and fast fault isolation now matter as much as raw bandwidth. Reliability is the fabric’s third axis, alongside bandwidth and latency, and it is the one that gets harder every time a cluster doubles.
Inference · The Workload Inverts
Serving got more network-bound, not less
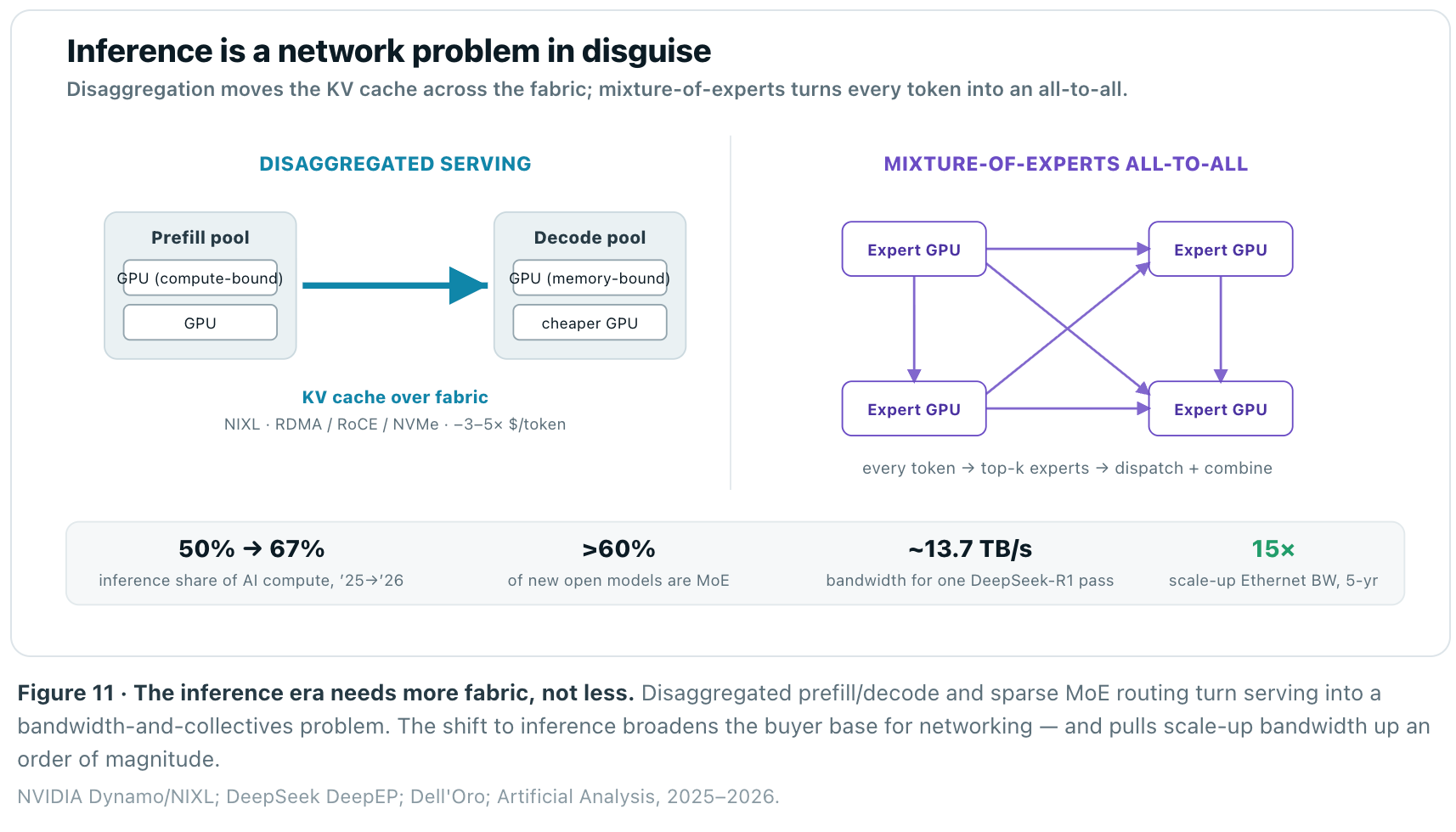
The single biggest shift in 2026 is that the workload changed. Inference passed half of all AI compute in 2025 and reaches roughly two-thirds in 2026. The lazy inference is that serving needs less network than training. The opposite is happening: modern inference is disaggregated and sparse, and both properties push traffic onto the fabric.
Two forces drive it. First, disaggregated serving splits the prefill and decode phases onto separate GPU pools, which means the multi-gigabyte KV cache must move between them at wire speed — NVIDIA open-sourced NIXL precisely for this, shuttling KV tensors from prefill to decode VRAM over RDMA, RoCE, or NVMe and cutting cost per token 3–5×. Second, mixture-of-experts models — now more than 60% of new open releases — route every token through a sparse all-to-all across experts; DeepSeek’s DeepEP saturates 400G NICs, and a full DeepSeek-R1 forward pass demands on the order of 13.7 TB/s of bandwidth. Inference has become a distributed-systems problem with the network at its center, which is why Dell’Oro projects scale-up Ethernet bandwidth to rise 15× in five years.
The market narrative says inference is cheap and local. The architecture says inference is a bandwidth problem wearing a latency mask.
Optical Networking · The Power Wall
Light is no longer the afterthought — it is the constraint
Every scale-out and scale-across link that exceeds a few meters is optical, which means optics now sit on the critical path of the entire AI build-out — on cost, on supply, and above all on power. A single pluggable transceiver draws about 15W at 800G and ~30W at 1.6T; a large GPU is fed by several of them, and at cluster scale optics consume a double-digit percentage of total AI-factory power. Conventional DSP-based pluggables burn roughly 21 picojoules per bit. When you are provisioning gigawatts, that is real money and real megawatts.
The industry’s response is a march to shorten the electrical path and delete power-hungry silicon. Linear pluggable optics (LPO) remove the DSP entirely, cutting module power 30–50% and shaving latency, and are projected to cover over 40% of short-reach 800G links. Co-packaged optics (CPO) go further, integrating the optical engines directly onto the switch package: NVIDIA claims 3.5× better power efficiency, 4× fewer lasers, and 10× the network resiliency. Broadcom’s Tomahawk 6 “Davisson” is already shipping 102.4 Tbps of optically-enabled switching, and NVIDIA’s Quantum-X Photonics InfiniBand reaches production in early 2026, with Spectrum-X Photonics Ethernet following in the second half.
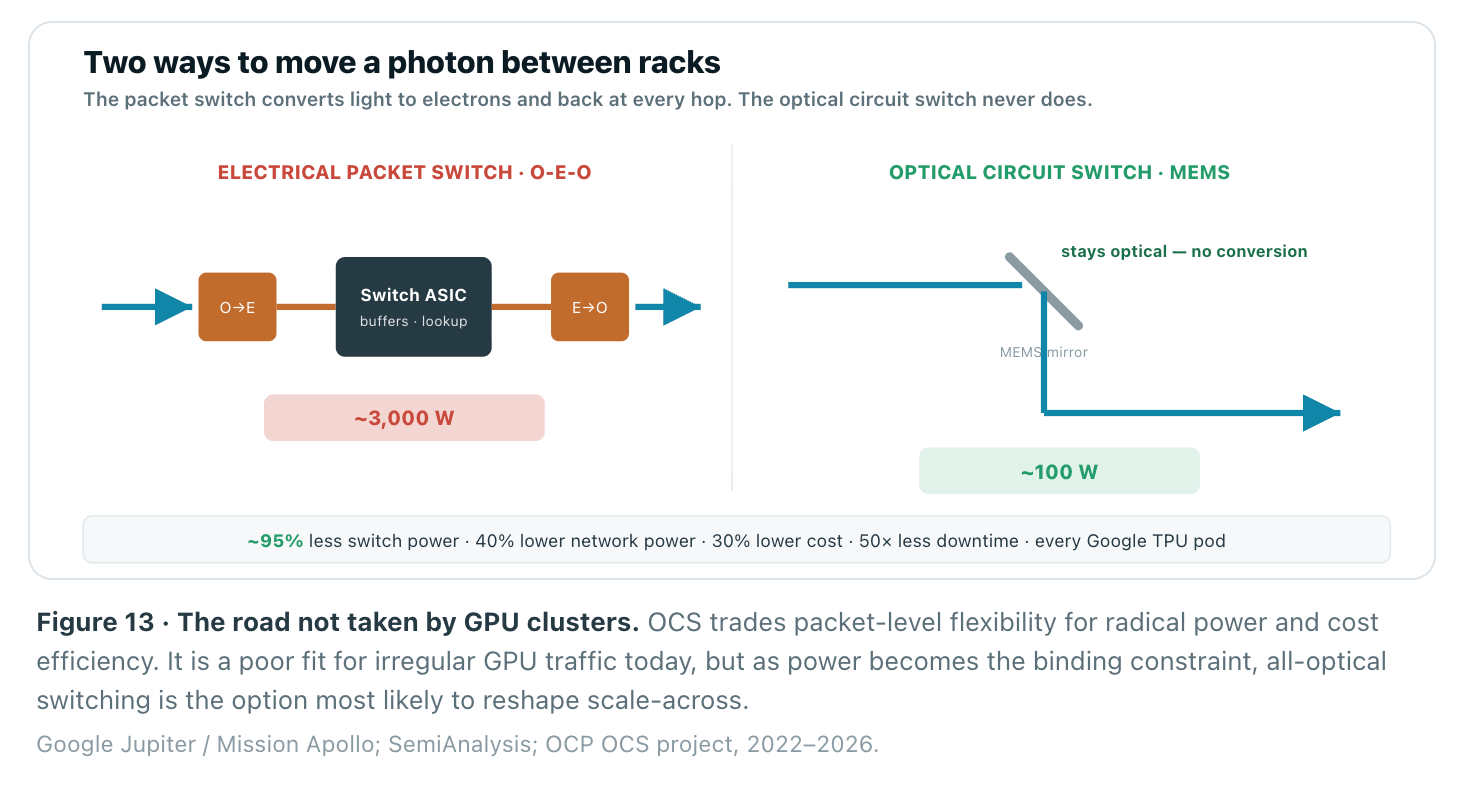
A different bet: optical circuit switching
Not everyone is buying more packet switches. Google took a structurally different path with optical circuit switching (OCS) — MEMS mirror arrays that steer light from rack to rack without ever converting it to electrons. Its Jupiter fabric has used OCS (codenamed Palomar) across every TPU v4 and v5 pod, and the latest Ironwood generation pairs a 3D-torus with the Apollo OCS. The numbers are hard to argue with: a single OCS draws about 100W versus ~3,000W for an equivalent electrical packet switch — a ~95% reduction — contributing to 40% lower network power, 30% lower cost, and 50× less downtime. An OCS can’t inspect or buffer packets, so it fits the regular, reconfigurable topologies of TPU pods better than general GPU clusters. But it is the clearest existence proof that the packet-switched, convert-at-every-hop model is not the only way to build an AI fabric — and the OCP stood up a standardized OCS project in 2026.
The Money · Market Structure
Sizing the fabric — and who captures it
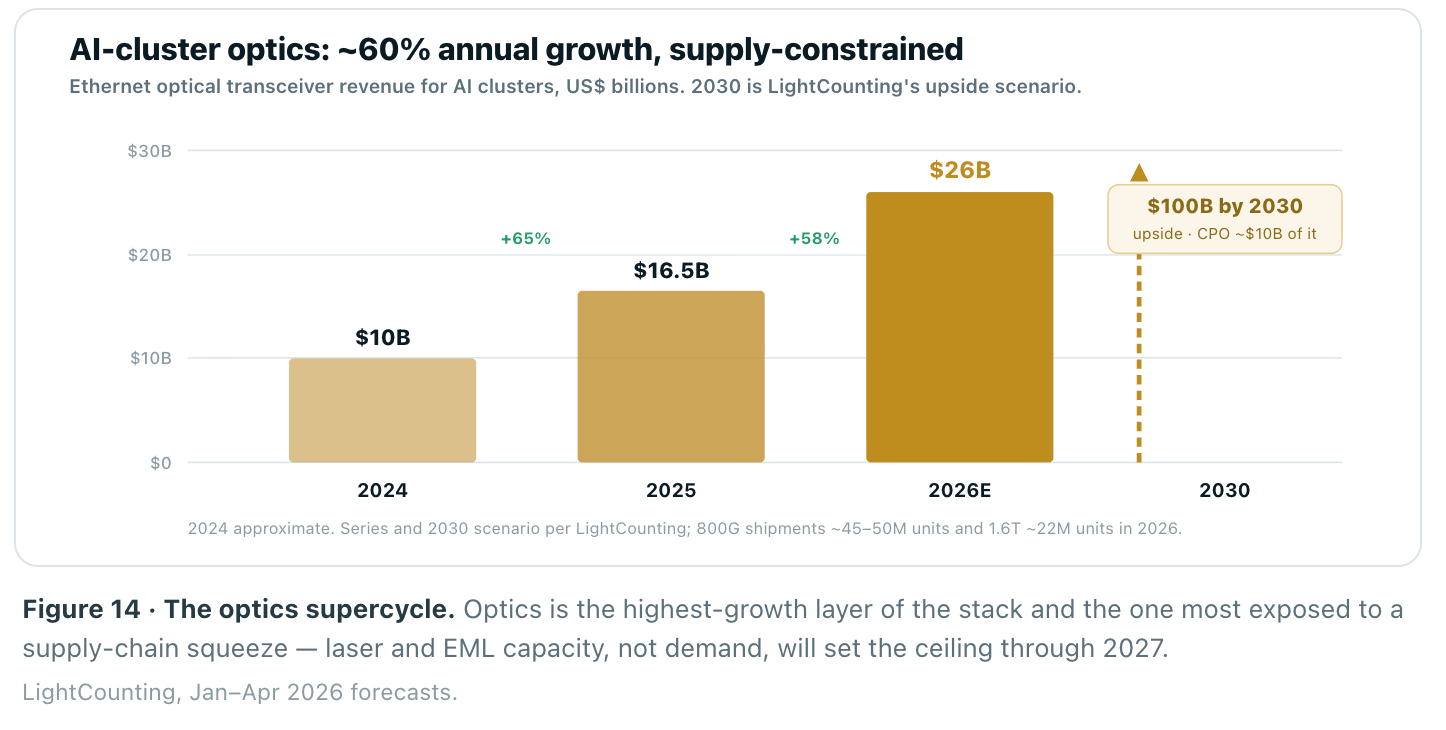
Pull back to the market map and the numbers are large and fast. Data-center capex is on track to approach $1 trillion in 2026 and hit $1.7 trillion by 2030. Within that, Dell’Oro sees AI back-end switching alone clearing $100B in annual spend by 2030. The optics attach is growing even faster: AI-cluster optical transceivers went from roughly $10B in 2024 to $16.5B in 2025 to a projected $26B in 2026 — ~60% growth two years running — with LightCounting’s upside scenario reaching $100B by 2030. The binding constraint is supply, not demand: InP laser and EML capacity is running roughly 30% short of orders.
The pace is set by a SerDes cadence that doubles lane rate every two-to-three years, dragging port speeds and optics with it. The majority of AI back-end ports have already moved to 800G; Dell’Oro expects 1.6T by 2027 and 3.2T by 2030. Each step is a forced upgrade cycle for switches, NICs, optics, and cabling — a recurring-revenue engine for whoever owns the reference design.
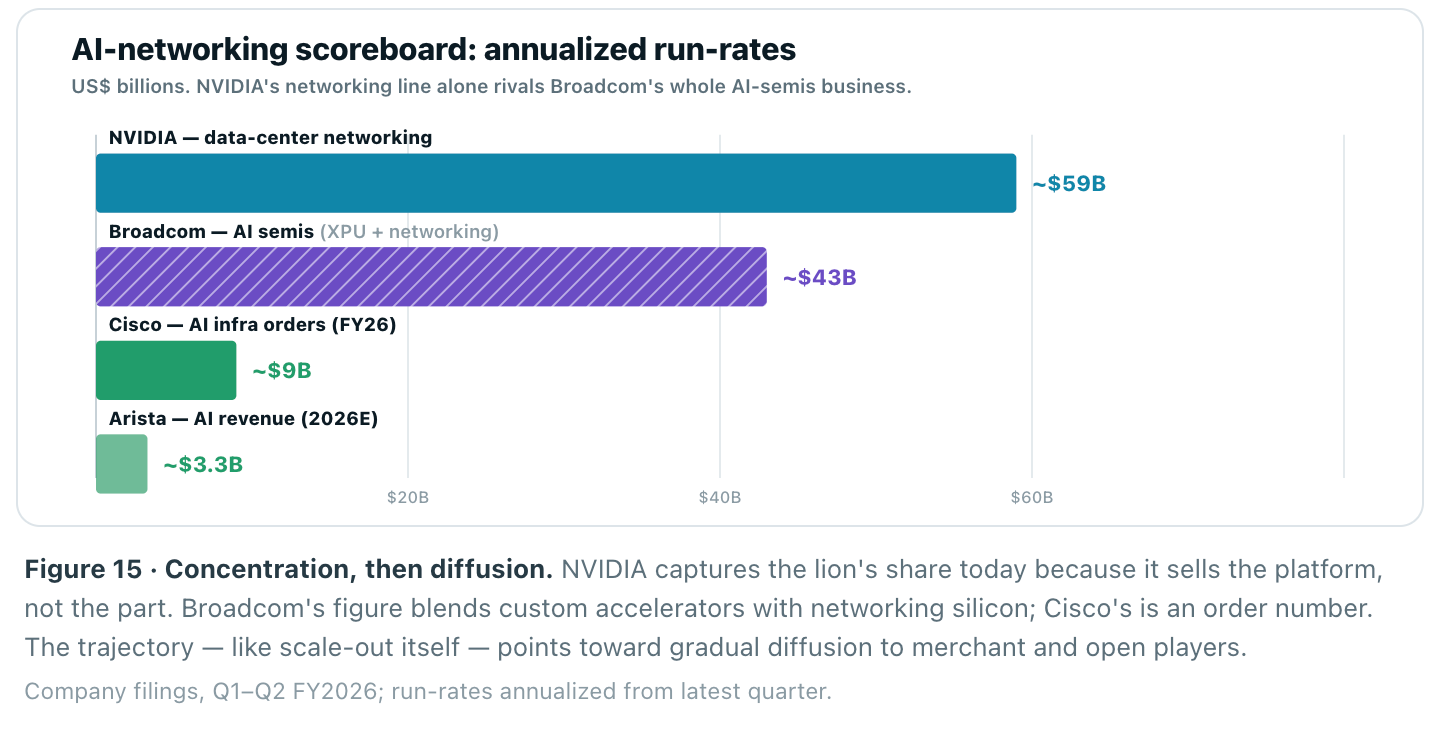
And who is capturing it? NVIDIA’s networking business alone is now running at roughly a $60B annualized rate — Q1 FY27 networking revenue hit $14.8B, up 199% year-over-year, with Spectrum-X past a $10B run-rate on its own. That single line item is larger than Broadcom’s entire AI semiconductor business and dwarfs Arista and Cisco’s AI franchises. The merchant challengers are growing fast — Arista’s AI revenue roughly doubles to $3.25B in 2026, Cisco’s AI infrastructure orders reach $9B — but the scoreboard shows how much of the value the platform owner still captures.
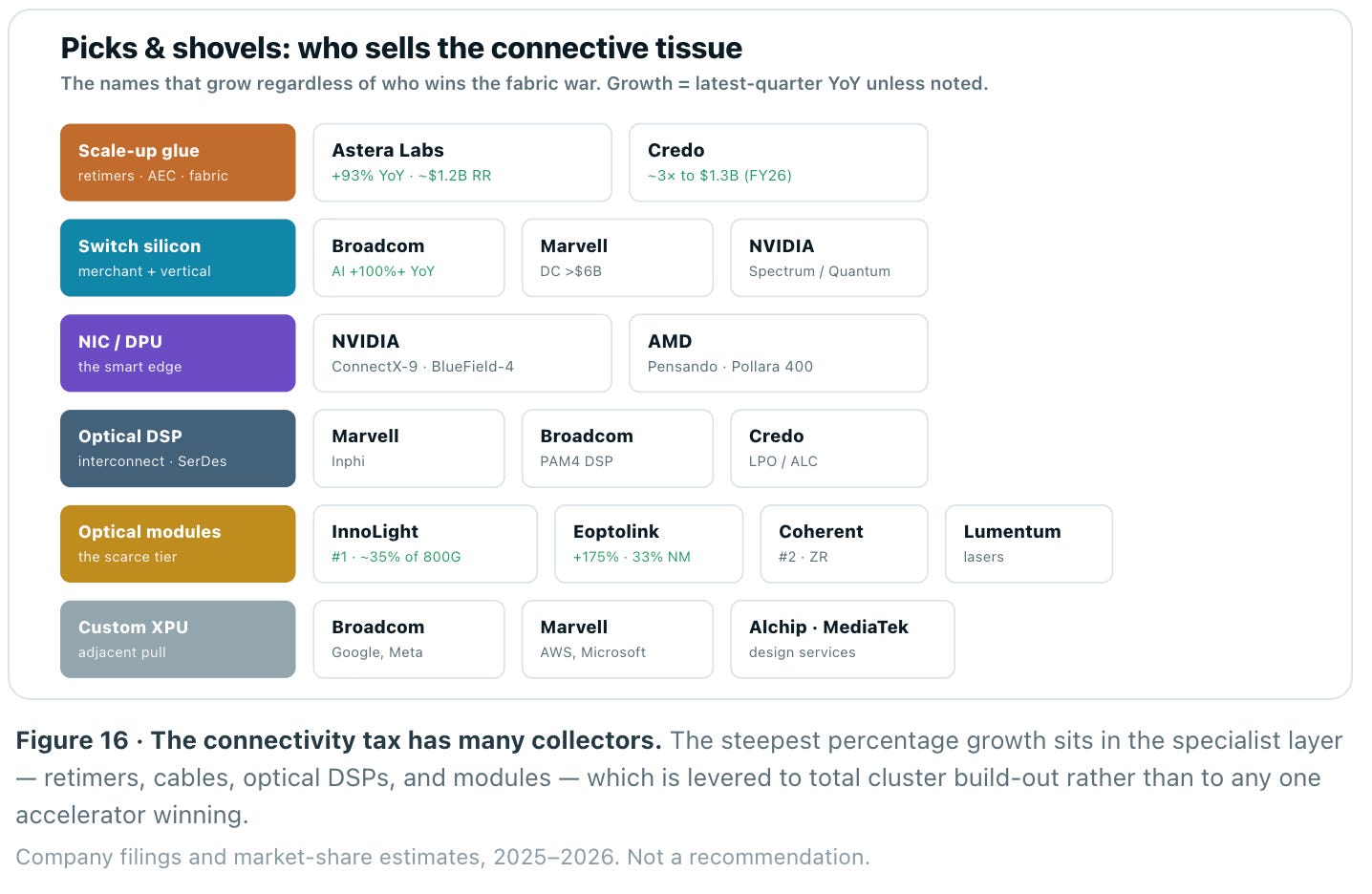
The megacap scoreboard understates where the sharpest returns sit. Beneath NVIDIA and Broadcom is a layer of specialists whose growth rates are, in percentage terms, even steeper — because they sell the connective tissue every architecture needs regardless of who wins the fabric war. Astera Labs (retimers, PCIe/CXL fabric switches, active cables) grew Q1 2026 revenue 93% YoY to $308M, a ~$1.2B run-rate, and now ships a 320-lane scale-up fabric switch. Credo, whose active electrical cables replaced flaky passive copper in hyperscale racks, roughly tripled fiscal-2026 revenue to $1.3B. Marvell’s data-center business — custom XPUs plus Inphi-derived optical DSPs — cleared $6B en route to a targeted $15B by FY28.
The scarcest tier — optical modules and their laser inputs — is where a set of mostly-Asian specialists captures the volume. InnoLight leads 800G at an estimated ~35% share; Eoptolink grew 175% to $1.2B at a 33% net margin; Coherent and Lumentum anchor the lasers and coherent DCI. The top five are roughly half the market. This layer is the cleanest expression of the thesis: pure connectivity exposure and growth that outruns the megacaps — with the offsetting risk that modules commoditize and CPO migrates value back to the switch vendor.
Make the stakes concrete. A fabric is not just a cost line; a better one converts directly into recovered compute. Drag the cluster size below — the bandwidth tax is what lifting delivered throughput from a vanilla ~60% to Spectrum-X’s ~95% is worth every year, alongside the optics bill and the failure interval you are signing up for.
The Investment Lens
Reading the stack as a set of control points
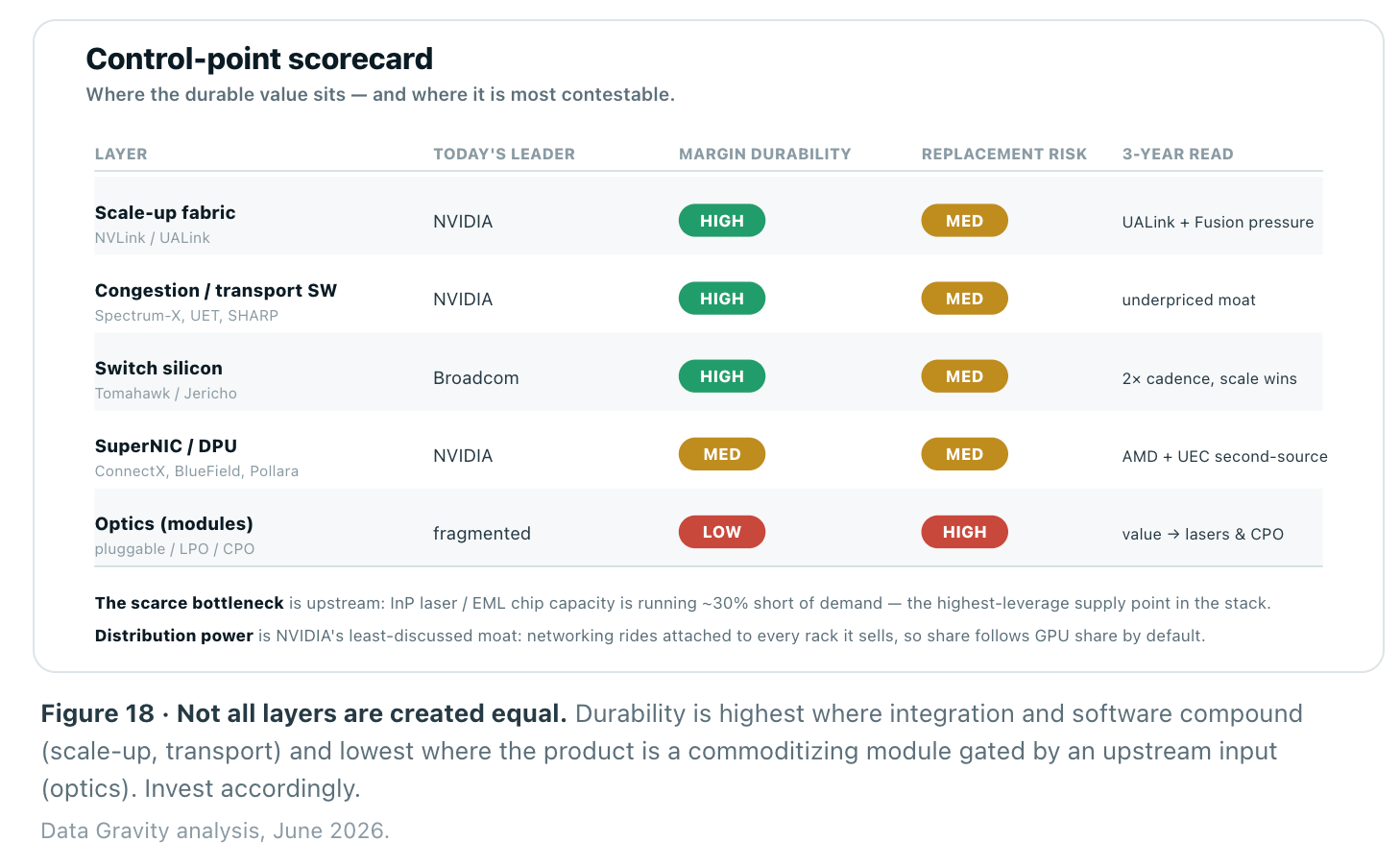
The layers of this stack are not equally defensible, and that distinction is the entire investment question. Sort it on the durable questions — structural advantage, capital intensity, margin durability, replacement risk — and a clear hierarchy of moats appears.
At the top sits the scale-up memory fabric: NVLink is the deepest moat in AI hardware because it is vertically integrated, copper-based, and physically hard to second-source. Just beneath it, and consistently underpriced by the market, is the congestion-control and transport software — adaptive routing, telemetry, and collective offload are what turn rated bandwidth into delivered bandwidth, and they travel with the platform. Switch silicon is durable but merchant, where Broadcom’s scale is the advantage. And optics — the fastest-growing layer — has the least durable margins: modules are commoditizing, the real scarcity is upstream in lasers and EML chips, and CPO is migrating value from the module maker to the switch vendor.
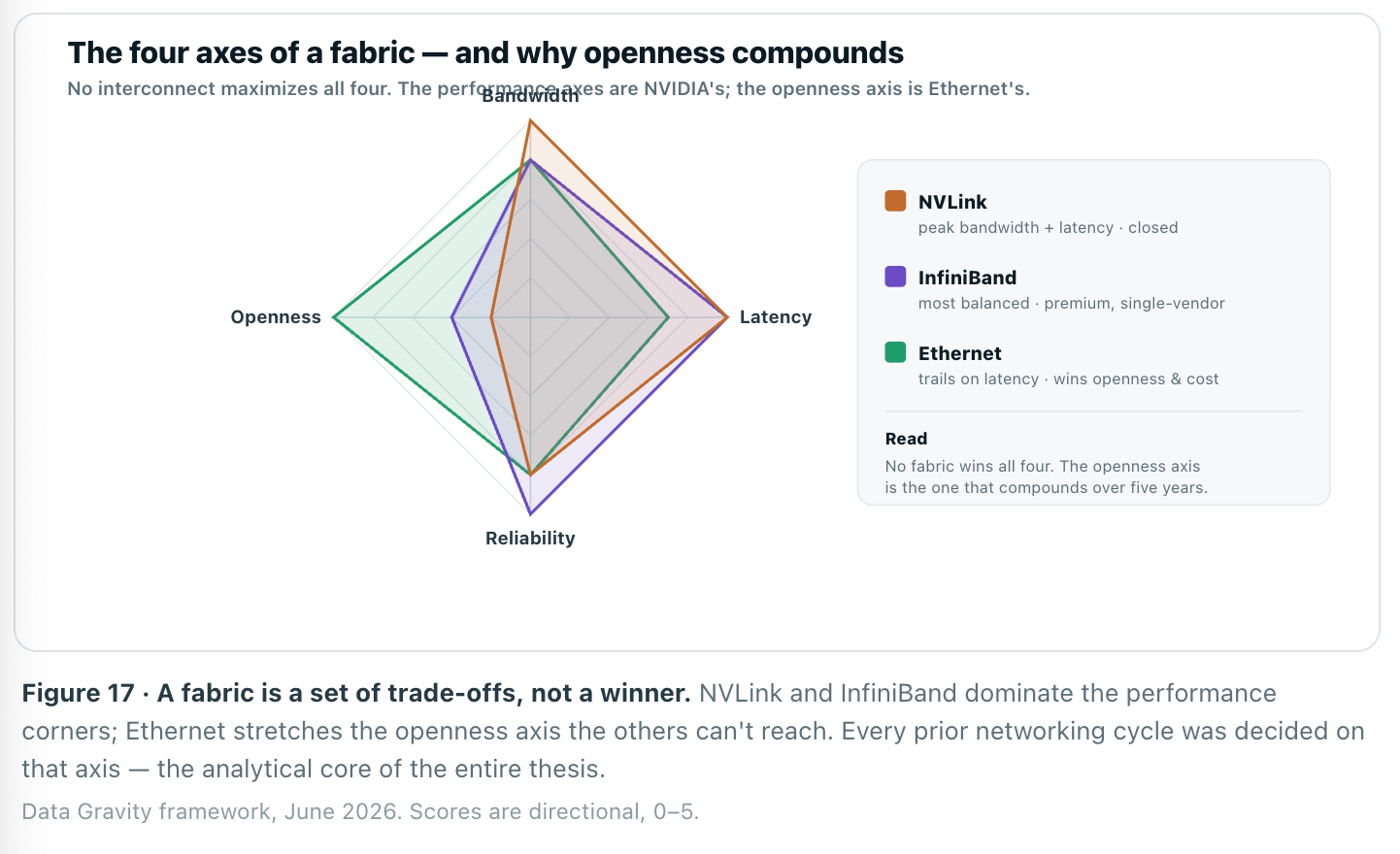
Start with the fabrics themselves. Every interconnect is a different point in a four-dimensional trade space — bandwidth, latency, reliability, and openness — and no fabric maximizes all four. NVLink and InfiniBand win the performance axes; Ethernet wins openness. On a five-year horizon, openness is the axis that has historically compounded.
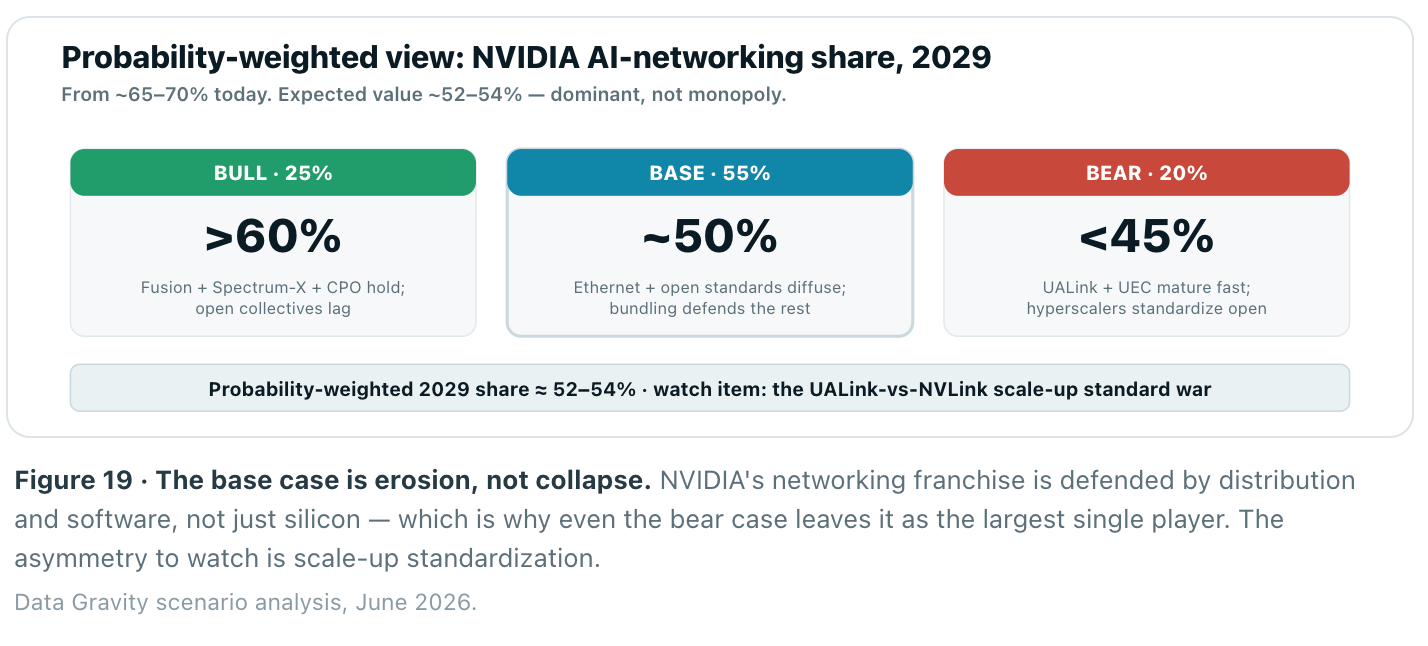
Put probabilities on it. The one variable that moves the most enterprise value is NVIDIA’s share of AI networking revenue over the next three years — today roughly 65–70%. Base case, weighted at ~55%: Ethernet and open standards keep diffusing, NVIDIA’s platform bundling defends a slipping-but-dominant position, and share settles near half. The bull case (~25%) has NVLink Fusion, Spectrum-X and CPO holding share above 60% because open collectives and transport software lag. The bear case (~20%) has UALink and Ultra Ethernet maturing fast enough that hyperscalers standardize on open scale-up and merchant silicon, dragging share below 45%. Expected value lands around 52–54% — still dominant, but no longer a monopoly.
Bottom Line
The interconnect is the investable layer
The AI narrative has quietly become a networking narrative. Three nested fabrics — scale-up over copper, scale-out over light, scale-across over the metro — now determine whether a warehouse of accelerators behaves like one supercomputer or an expensive pile of idle silicon. The economics have followed: networking is a double-digit share of cluster cost, a ~$60B annual business for NVIDIA alone, and a market Dell’Oro sizes above $100B by 2030.
Own the bottlenecks — scale-up integration, transport software, switch-silicon scale, and upstream optical supply — and underwrite the open-standards coalition as the force that slowly redistributes the rest.
For investors, the signal is to price durability, not growth. The most defensible positions are the vertically-integrated scale-up fabric and the transport software that rides with it; the most durable merchant franchise is switch silicon at scale; and the scarcest physical bottleneck is upstream optical supply — lasers and EML chips — not the modules themselves. The commodity risk sits precisely where the growth headlines are loudest. The single highest-leverage variable over the next three years is whether the open coalition — UALink and Ultra Ethernet — can standardize the scale-up domain the way it already flipped scale-out. That contest, more than any FLOPS number, will decide where the margins in AI infrastructure ultimately settle.
The one-line thesis: Compute got the headlines; the interconnect gets the margins. Own the bottlenecks — scale-up integration, transport software, switch-silicon scale, and upstream optical supply — and underwrite the open-standards coalition as the force that slowly redistributes the rest.
Data Gravity is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.