

What is CXL?
The interconnect rewiring AI memory: turning stranded DRAM into a shared resource as memory prices spike and KV cache becomes the bottleneck


Compute Express Link (CXL) is an open, cache-coherent interconnect that lets CPUs, accelerators, and memory devices share one address space over the PCIe physical layer. It exists because memory stopped scaling at the rate compute does, and because the unit of AI infrastructure spend has shifted from FLOPS to bytes held in fast memory.
CXL is the mechanism for decoupling memory capacity from the CPU socket it used to be soldered next to — turning memory into a pooled, fabric-attached resource instead of a fixed, stranded one. Seven years after its 2019 launch, it has gone from a side project to the default answer for memory disaggregation: all three big DRAM makers build CXL memory modules, every major CPU exposes CXL root ports, and the spec hit its fourth major revision in November 2025. The timing is not incidental. With DRAM prices up roughly 90% quarter-over-quarter in Q1 2026 and HBM crowding conventional DRAM off the wafer, the economic case for reclaiming stranded memory just went from theoretical to urgent.
Key Points

What is CXL in simple terms?
Compute Express Link is an open standard that lets a CPU treat memory attached over a PCIe cable or slot almost like its own local RAM — readable with ordinary load/store instructions, kept cache-coherent — so capacity and bandwidth can be added, pooled, and shared instead of being fixed to each socket.
What problem does CXL solve?
The memory wall. Compute has scaled ~600× faster than memory bandwidth over two decades, and AI inference (especially KV cache) consumes memory per user. CXL adds a cheaper, poolable memory tier and recovers DRAM that would otherwise sit stranded.
Is CXL used to connect GPUs to each other?
No. GPU-to-GPU scale-up is the domain of NVLink and UALink. CXL targets CPU-to-memory expansion, pooling, and coherency — the two are complementary, not competing.
Who are the main CXL companies?
Astera Labs (Leo controllers), Marvell (Structera controllers and switch), Credo (SerDes/retimers), Micron, Samsung and SK hynix (memory media), and Penguin Solutions and MemVerge (systems and software).
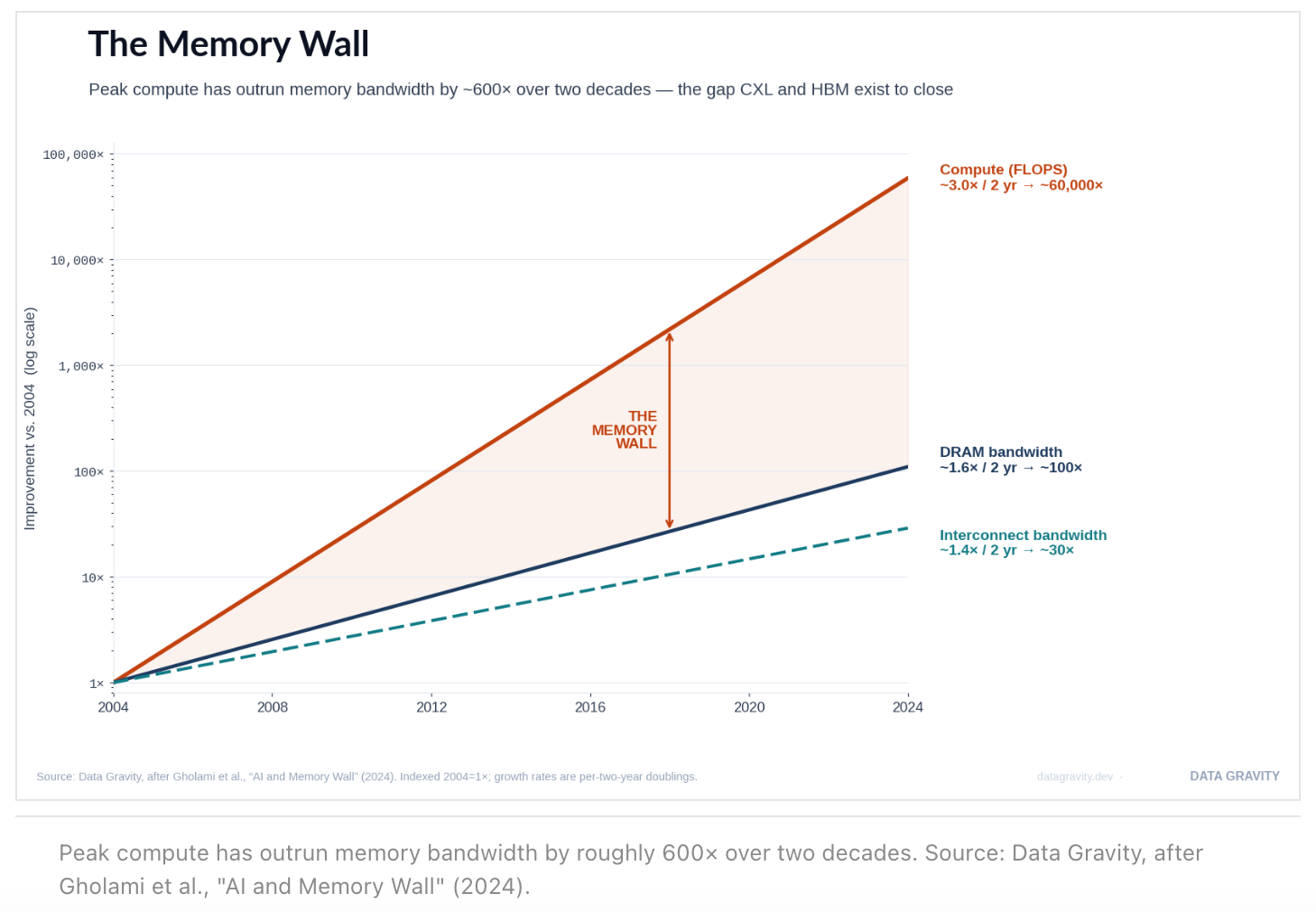
The Bottleneck: Compute outran memory by 600x
The mechanics start with a scaling divergence. Over the past two decades, peak compute (FLOPS) has grown roughly 3.0× every two years — about 60,000× cumulatively — while DRAM bandwidth grew ~1.6× per two years (~100×) and interconnect bandwidth ~1.4× (~30×). That is a ~600× gap between how fast processors can compute and how fast memory can feed them. This is the “memory wall,” and it is the single largest cost driver in LLM inference today.
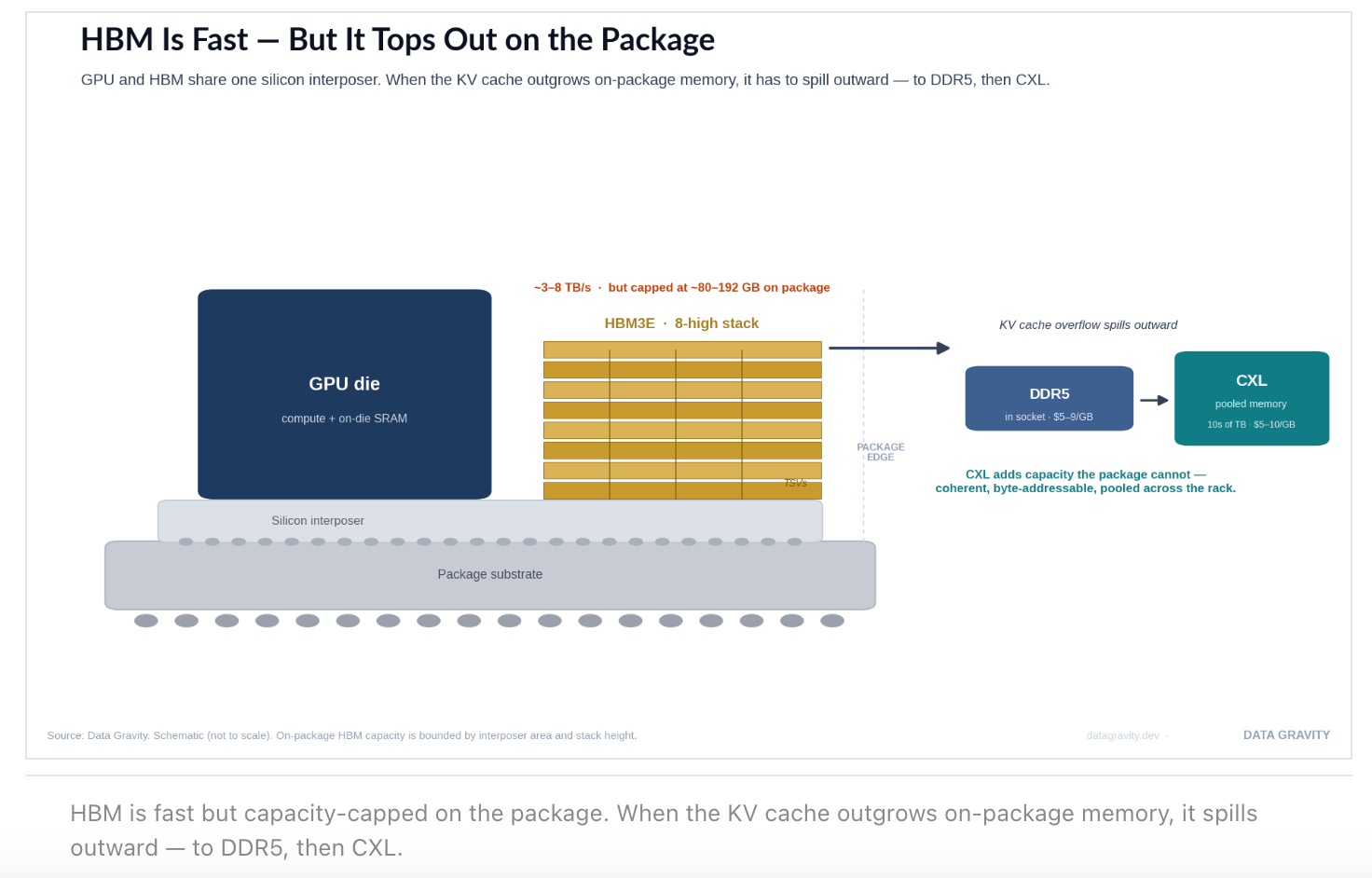
As I detailed in Why KV Cache and Memory Drive AI Economics, a 128K-token conversation on a 70B-parameter model can consume ~40GB of HBM per concurrent user — memory that scales linearly with users and context length, unlike the fixed footprint of model weights. HBM is the fastest tier, but it is capacity-constrained and priced at a premium: a single HBM3E stack runs $60–100 against $5–10 for an equivalent slice of DDR5, and HBM consumes roughly 3× the wafer area per gigabyte. The result in 2026 is a genuine DRAM shortage. CXL exists to put a coherent, low-latency tier between scarce HBM and a slow storage hop — and to recover the DRAM that is already installed but stranded.
The Demand Driver: Context windows are the underappreciated trend
The demand curve underneath the memory wall is context length. Two years ago GPT-4 shipped with an 8K-token window; today Gemini runs at 2M and Claude- and GPT-5-class models sit at 1M+, with roughly thirteen frontier models now shipping million-token windows. Micron EVP Manish Bhatia told JPMorgan in 2026 that context windows are expanding ~30× per year. Every token in a window generates KV-cache data that must live in memory during inference, so a single 1M-token session can consume hundreds of gigabytes of KV cache per user — and agentic workflows, where one request fans out into many chained model calls each carrying its own context, make that growth combinatorial rather than linear.
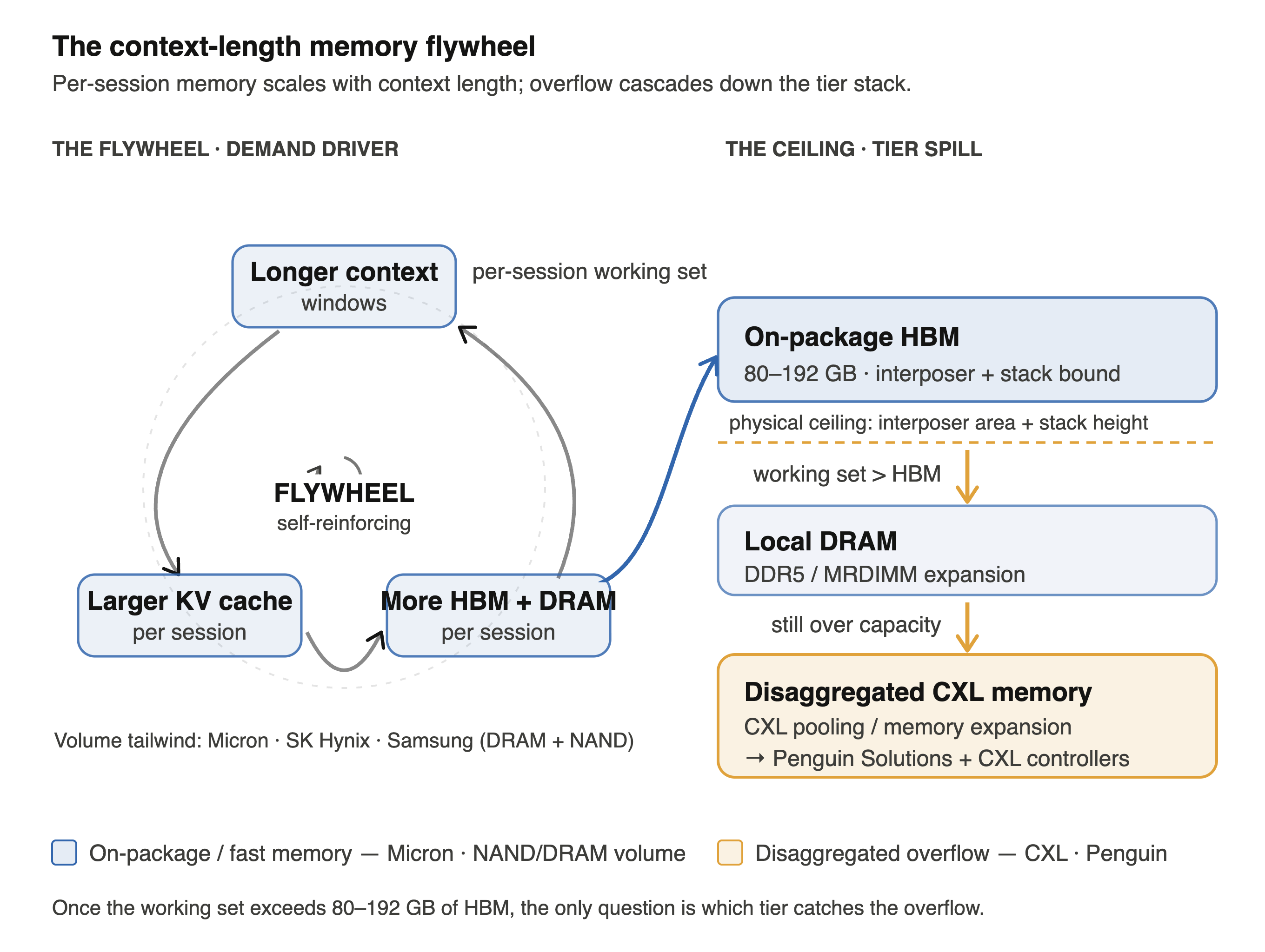
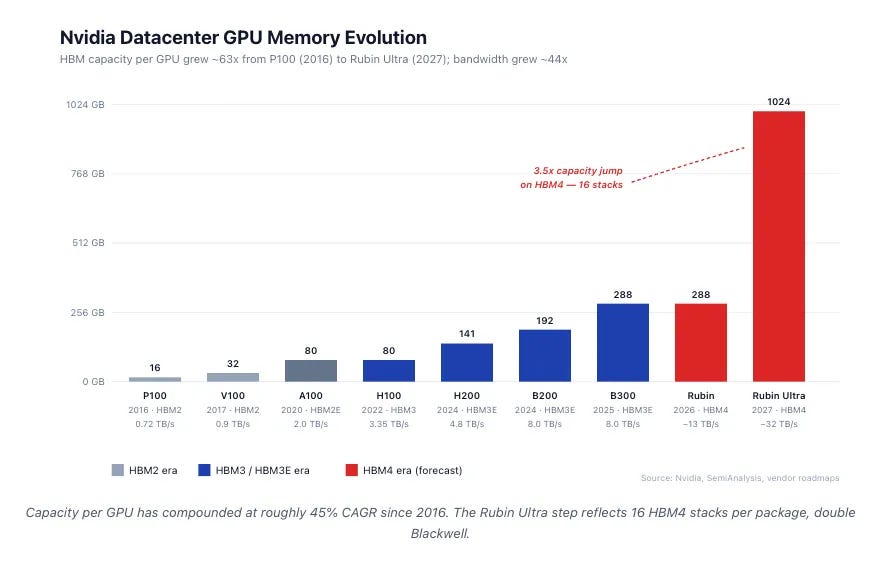
This is the flywheel: longer context → larger KV caches → more HBM and DRAM consumed per session (a direct tailwind for Micron and the NAND makers), and, when the cache overflows on-package memory, a forced spill outward to disaggregated CXL memory (where Penguin Solutions and the controller vendors monetize). A GPU’s on-package HBM is physically bounded by interposer area and stack height to roughly 80–192 GB; once the working set exceeds that, the only question is which tier catches the overflow.
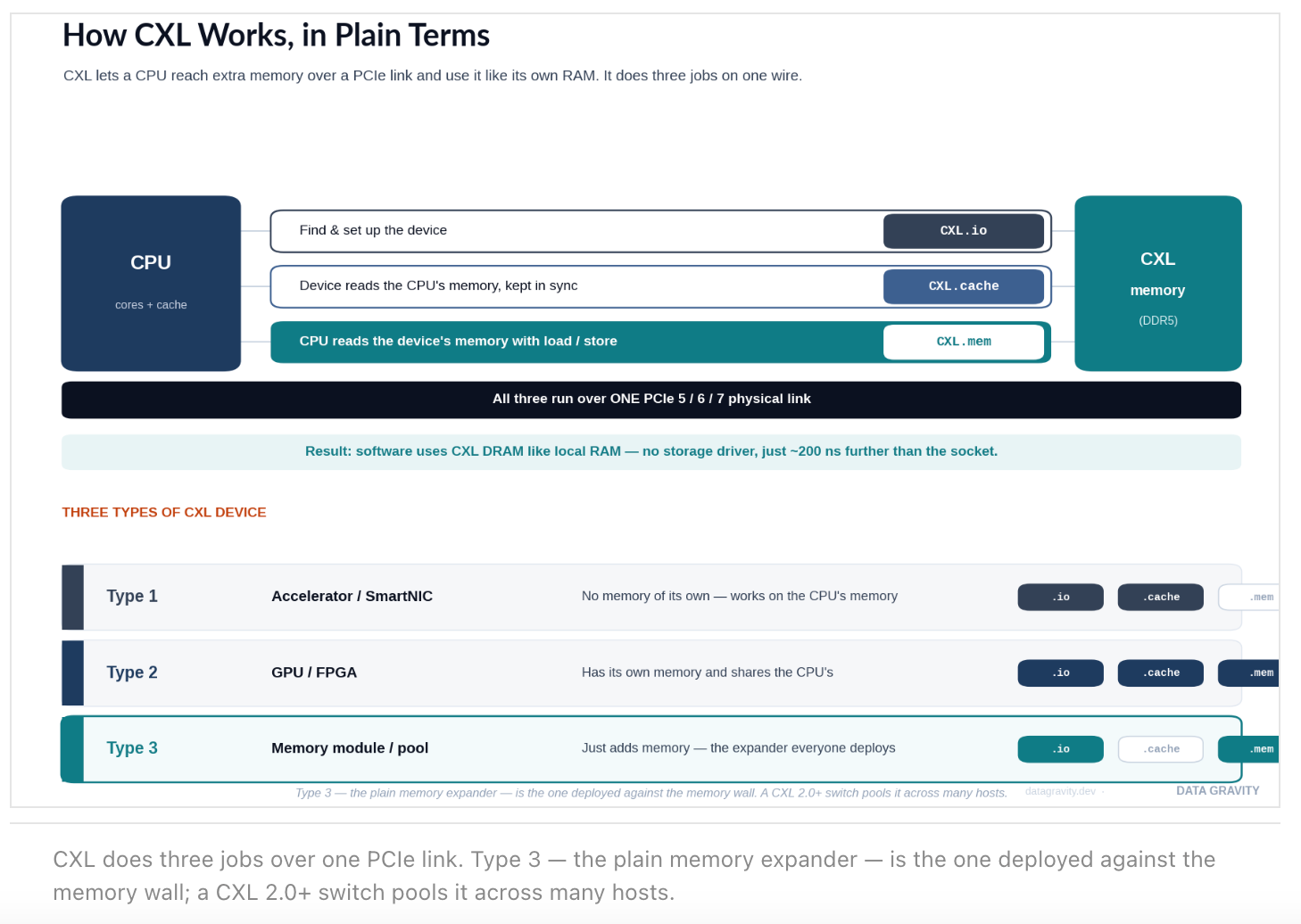
How CXL works, in plain terms
Strip away the jargon and CXL does one thing: it lets a CPU reach extra memory sitting on a PCIe link and use it almost like its own RAM. It does this with three sub-protocols that share a single physical wire. CXL.io handles discovery and configuration — the housekeeping, functionally identical to PCIe. CXL.cache lets a device read the host’s memory while staying coherent (kept in sync). And CXL.mem — the important one — lets the host read the device’s memory with ordinary load/store instructions, no storage driver in the path.
CXL.io → find & set up the device · like PCIe
CXL.cache → device reads the CPU's memory, in sync · coherent
CXL.mem → CPU reads the device's memory, load/store · the key one
The practical consequence is the whole point of the technology: software treats CXL-attached DRAM the same way it treats local DRAM, just ~200 nanoseconds further away (about a NUMA hop), versus the ~100 microseconds it would take to reach an SSD. Around this, the spec defines three device types: Type 1 (an accelerator or SmartNIC with no memory of its own), Type 2 (a GPU or FPGA that has its own memory and also shares the host’s), and Type 3 (a plain memory expander or pool — the workhorse deployed against the memory wall).
Memory semantics, not I/O semantics, is what makes CXL a memory technology rather than just a faster peripheral bus.
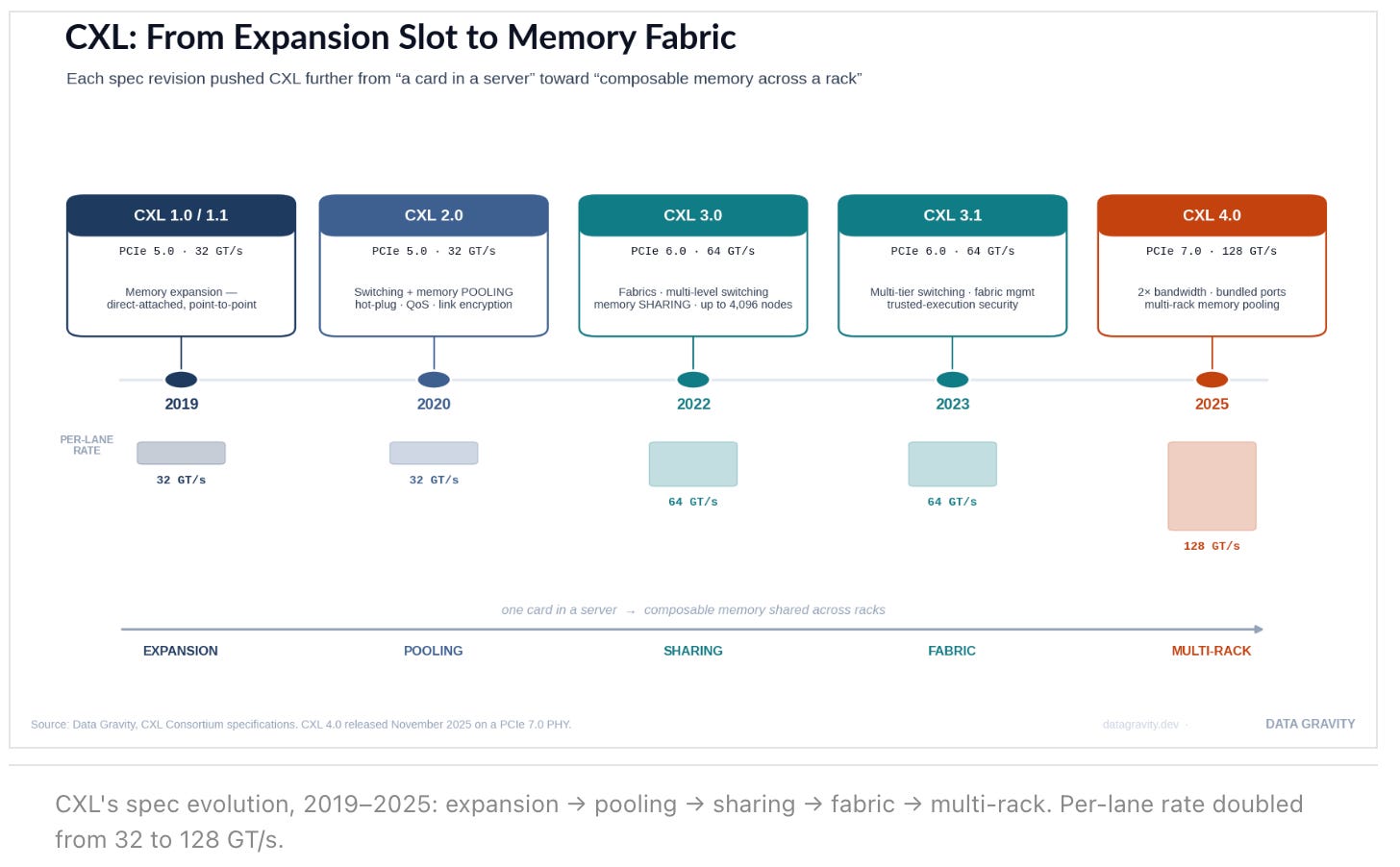
The Roadmap: From expansion slot to memory fabric
Each spec revision pushed CXL further from “a card in a server” toward “composable memory across a rack.” CXL 1.1 (2019) did direct-attached expansion on a PCIe 5.0 PHY at 32 GT/s. CXL 2.0 (2020) added switching and memory pooling, plus hot-plug, QoS, and link encryption. CXL 3.0 (2022) moved to a PCIe 6.0 PHY at 64 GT/s with PAM-4 signaling, doubled bandwidth, and introduced fabrics: multi-level switching, memory sharing across hosts, peer-to-peer DMA, and addressing for up to 4,096 nodes. CXL 3.1 (2023) added multi-tier switching and trusted-execution security. And CXL 4.0, released in November 2025, doubled per-lane bandwidth again on a PCIe 7.0 PHY at 128 GT/s, with bundled ports and multi-rack pooling. The throughline: every generation widened the blast radius of a single memory allocation, from one motherboard to an entire rack.
Who is behind CXL — and what CXL is not
CXL is governed by the CXL Consortium, founded in 2019 by Alibaba, AMD, Cisco, Dell EMC, Meta, Google, HPE, Huawei, Intel, and Microsoft — a roster that signals hyperscaler-driven standardization rather than one vendor’s proprietary play. Critically, the Consortium then won the interconnect wars: it absorbed Gen-Z (2021), OpenCAPI (2022), and the CCIX effort, consolidating a fragmented landscape into one standard with one roadmap. That removed the standards-war risk that historically discourages capex on new interconnect silicon, which is why every major CPU — Intel Xeon, AMD EPYC, and the Arm server ecosystem — now ships CXL root-port support natively, and why AMD, Nvidia, and Samsung all sit on the board.

One clarification for the technical reader: CXL is not the GPU-to-GPU scale-up fabric. Its bandwidth and radix are wrong for that job, which belongs to NVLink (proprietary) and UALink (open). CXL won the CPU-to-memory layer; it never seriously contested the accelerator-to-accelerator layer. The two are complementary — and the most telling signal is that even Nvidia supports CXL memory expansion on Grace and Blackwell while building NVLink for scale-up.
Key Players
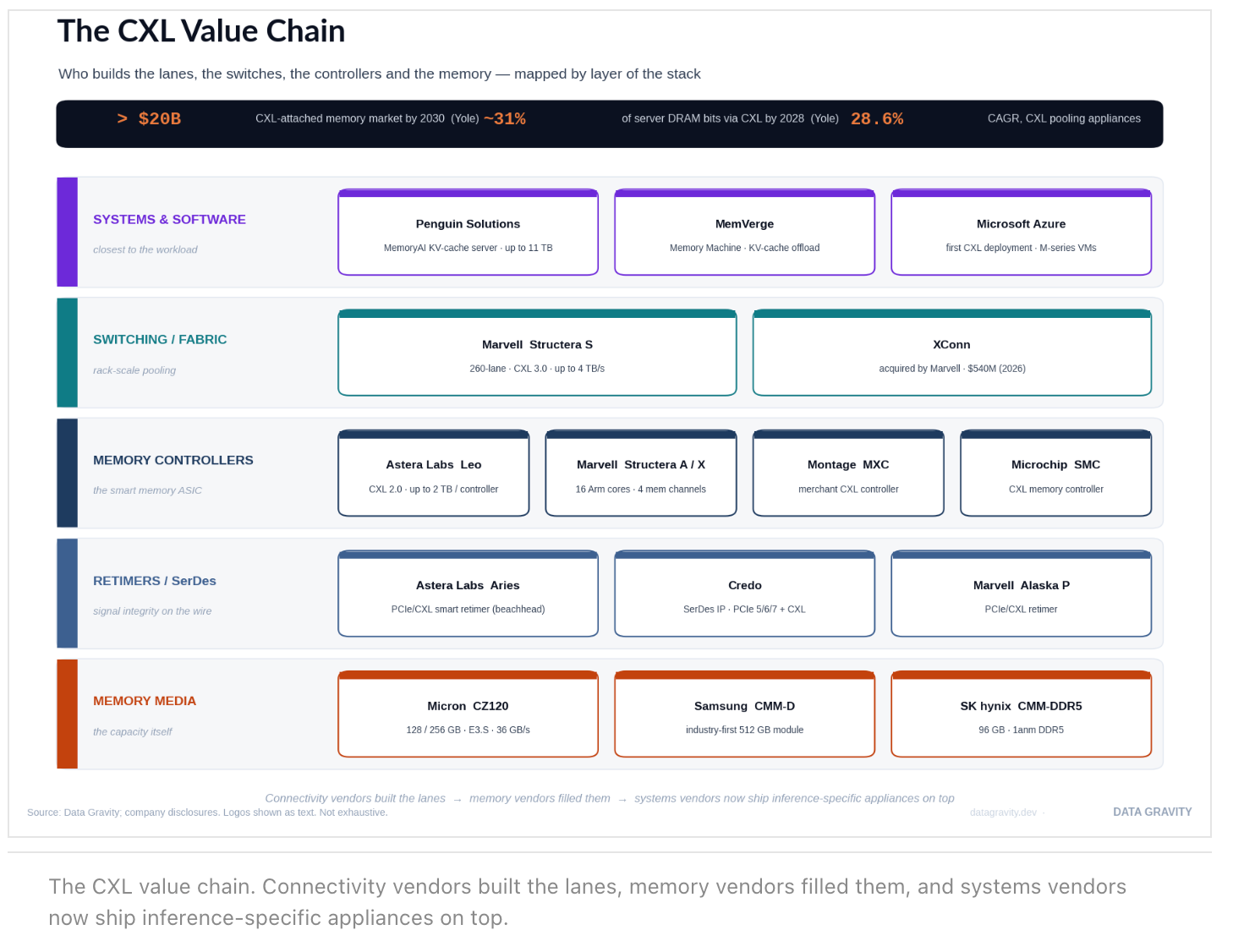
Connectivity silicon: Astera, Credo, Marvell
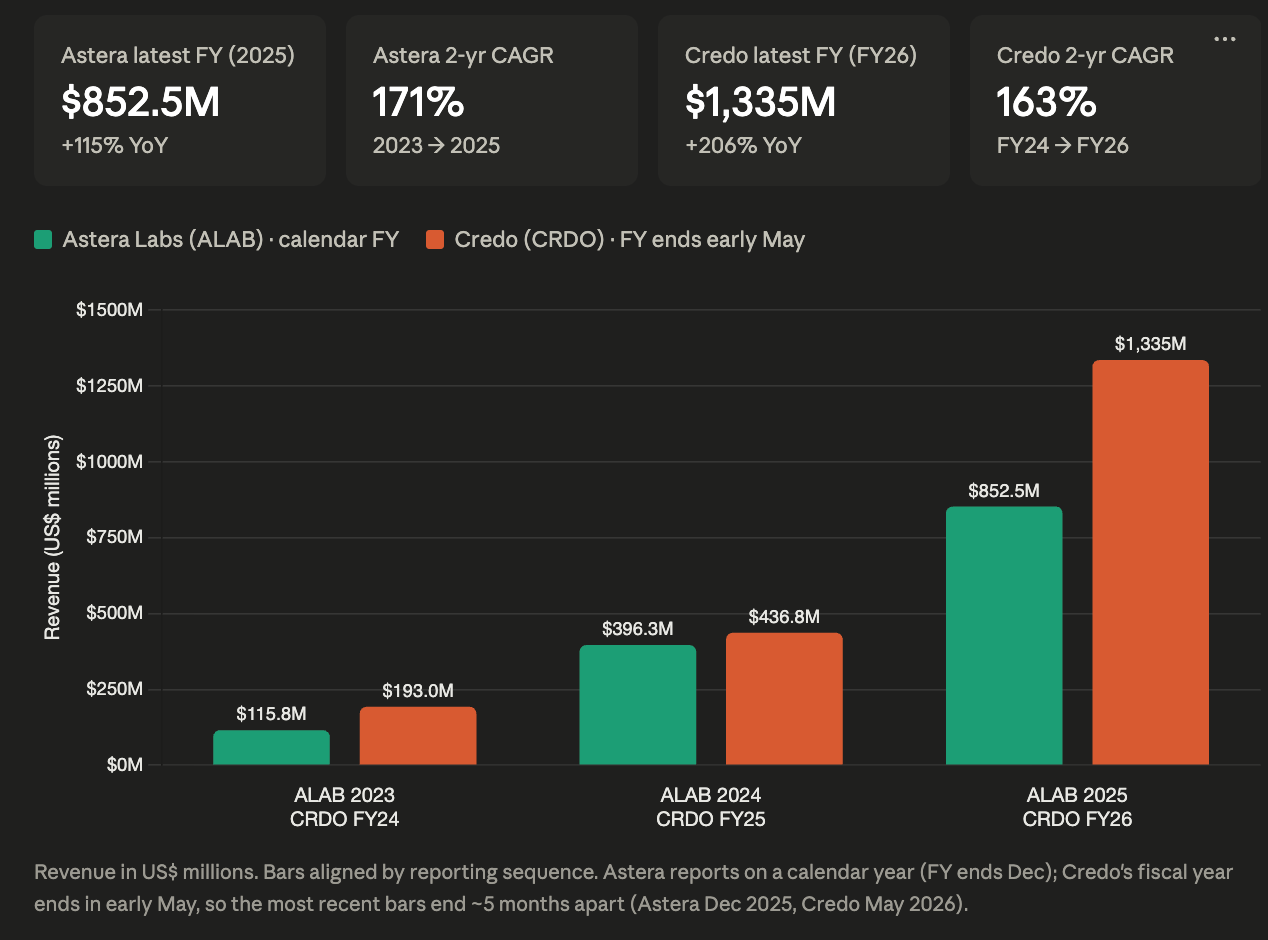
Astera Labs (ALAB) is the highest-profile pure-play. It IPO’d in March 2024 at more than 50× trailing revenue — I broke down the filing in Astera Labs IPO: S-1 Teardown, when Aries retimers drove 90%+ of revenue. The scale since is the story: full-year 2025 revenue hit $852.5M (+115%), and the most recent quarter — Q1 FY2026 (reported May 2026) — set a record at $308.4M, up 93% year-over-year and 14% sequentially, at a 76.4% non-GAAP gross margin and a 36.2% non-GAAP operating margin, with PCIe Gen 6 already more than a third of revenue. Leo, its CXL smart-memory-controller line (CXL 2.0, up to 2TB per controller), is the strategic bet — it powers Microsoft Azure’s M-series VMs in the industry’s first announced CXL-attached memory deployment, and in distributed inference with Penguin Solutions it has shown 75% higher GPU utilization and 2× inference throughput, plus 40% faster time-to-insights and up to 3× concurrent LLM instances for RAG. Leo plugs into vLLM, TensorRT-LLM, and SGLang with no application changes.
Credo (CRDO) occupies the adjacent retimer and SerDes layer. The growth has been violent: fiscal 2026 revenue hit $1.3B, up 206% year-over-year, with a record Q4 of $437M (+157% YoY) at ~68% gross margins — and the stock now carries a roughly $50B market cap, four times the level when I first covered it in From Niche to Necessary: Credo’s Quiet Domination of AI Interconnects. Its retimers support PCIe 5.0/6.0/7.0 and CXL interchangeably, so it captures CXL-attach revenue regardless of which controller or memory vendor a hyperscaler standardizes on. Marvell, meanwhile, is building the switch and fabric layer underneath both. Its Structera A near-memory accelerators (16 Arm Neoverse V2 cores, up to 200 GB/s and 4TB) and Structera X expansion controllers were the first with four memory channels and inline compression on 5nm; then in March 2026 it announced the Structera S 30260, a 260-lane CXL 3.0 switch delivering up to 4 TB/s of aggregate bandwidth for rack-level pooling, sampling Q3 2026 — built on Marvell’s $540M acquisition of XConn, closed February 2026, the largest deal in CXL switching to date.
Memory and systems: Micron, Samsung, SK hynix, Penguin
The memory makers supply the capacity the connectivity silicon pools, and CXL is their channel into sockets that are otherwise capacity-capped. Micron (MU) is the cleanest read on the demand: fiscal Q2 2026 revenue hit $23.86B, up 196% year-over-year, at a ~74% gross margin, with Q3 guided near 81% and management describing HBM and high-capacity DRAM as effectively sold out ahead of supply. Its CZ120 CXL modules ship in 128GB and 256GB capacities over PCIe Gen5 x8 at ~36 GB/s — within a hair of a DDR5-4800 RDIMM’s 38.4 GB/s. Samsung’s CMM-D line reached an industry-first 512GB module, and SK hynix ships its 96GB CMM-DDR5 with pooling support. None of them needs CXL to sell DRAM, but all of them need a way to sell more DRAM per core while HBM eats fab allocation — and NAND makers (Micron again, plus SanDisk) pick up the colder KV-cache tiers below CXL.
At the top of the stack, Penguin Solutions (PENG) is the clearest evidence that CXL demand is now inference-driven. In March 2026 it shipped what it calls the industry’s first production-ready CXL-based KV cache server, the MemoryAI appliance — 3TB of DDR5 plus up to eight 1TB CXL add-in cards for up to 11TB total — purpose-built to offload KV cache from GPU HBM, with roughly 10× faster access than NVMe-based approaches and out-of-the-box compatibility with NVIDIA’s Dynamo framework. Penguin frames the workload bluntly: inference is roughly 30% compute and 70% memory. The pull is showing up in results — Q2 FY2026 integrated-memory sales rose 63% year-over-year to $172M, and the company raised full-year guidance to ~12% growth.

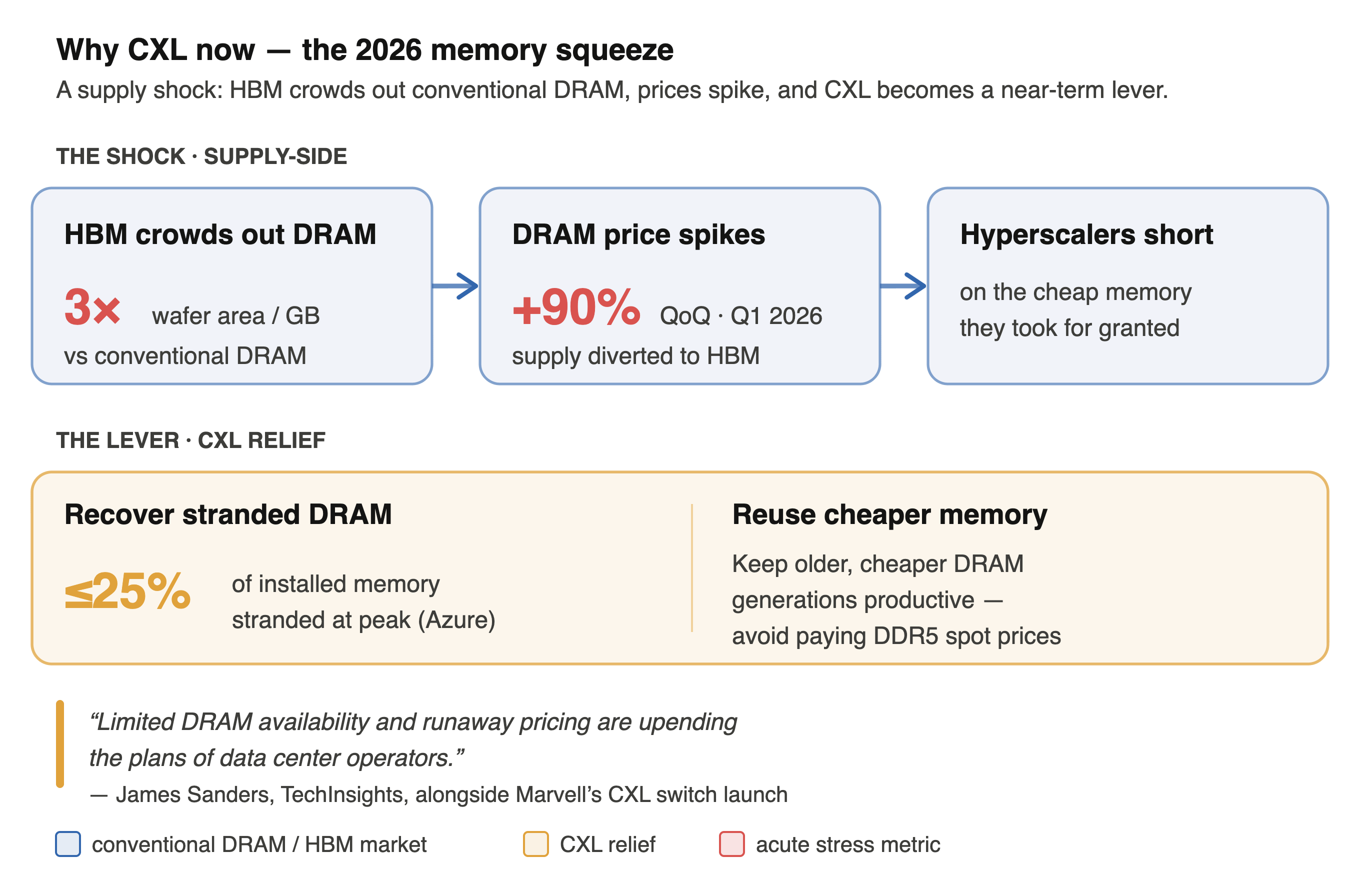
Why CXL Now?: The 2026 memory squeeze
The reason all of this is happening at once is a supply shock. HBM has reallocated wafer capacity away from conventional DRAM — it consumes roughly 3× the wafer area per gigabyte — sending DRAM prices up about 90% quarter-over-quarter in Q1 2026 and leaving hyperscalers short on the cheap memory they used to take for granted. As TechInsights’ James Sanders put it alongside Marvell’s switch launch, limited DRAM availability and runaway pricing are “upending the plans of data center operators.” CXL is one of the few near-term levers: it recovers DRAM that would otherwise sit stranded (up to 25% of installed memory at peak, per Microsoft’s Azure data), and it lets operators keep older, cheaper memory generations in productive service instead of paying spot prices for the newest DDR5.
Each generation of Nvidia GPUs adds more HBM capacity and bandwidth. Yet there are fundamental packaging and physical constraints on how much HBM can be integrated with a single GPU, limiting how far this scaling can continue.
What this means — and what breaks
CXL’s economics favor the infrastructure layer over any single silicon architecture. Astera and Credo monetize per-lane regardless of which CPU or accelerator sits on either end — a more durable position than betting on a GPU generation. Marvell’s switch converts pooling from a server feature into a rack-level fabric decision, raising both contract size and switching cost once a hyperscaler commits to a topology. The memory vendors get a second demand channel that requires no new fab, exactly when HBM allocation is tight. The risk to the thesis is timing, not direction. CXL-attached memory carries ~200ns of added latency — immaterial for KV cache offload and pooling, but disqualifying for the most latency-sensitive accelerator-local work, which keeps HBM taking share at the high end. And the disaggregation dividend is real but bounded: Microsoft’s Pond study found pooling across 8–16 sockets recovers ~7% of DRAM (hundreds of millions of dollars at cloud scale) against stranding that can hit 25% — meaningful, but not a panacea. That ceiling is what determines how much of the memory wall CXL actually absorbs versus HBM growth and software-side efficiency.

Summary
CXL solves a specific, quantifiable problem: memory bandwidth and capacity have scaled ~600× slower than compute over two decades, and AI inference — KV cache in particular — drives per-user memory consumption that fixed-memory architectures cannot absorb. Governance by a hyperscaler-led consortium that swallowed its two main rivals removed the standards-war risk that usually slows adoption, and four spec revisions since 2019 have carried CXL from single-server expansion to multi-rack fabric. Astera Labs and Credo monetize the connectivity layer, Marvell is building the switch fabric, Micron, Samsung, and SK hynix supply the capacity, and Penguin Solutions is shipping inference-specific appliances on top. Yole expects CXL-attached memory to exceed $20B by 2030 and CXL to carry ~31% of server DRAM bits by 2028; the CXL component market alone is forecast to grow from ~$1.9B in 2024 to ~$12.3B by 2030 at a ~32% CAGR. The next 12–18 months — through Marvell’s Structera S sampling and the first wave of CXL 4.0 silicon, against the worst DRAM shortage in years — will determine how much of the memory wall gets absorbed by CXL versus solved with HBM and smarter software instead.