

What is VAST Data?: Behind the $9.1B leader in AI-First storage and data infrastructure
Examining VAST’s role in AI-first storage and database infrastructure in the data center

Last week, Vast Data announced its series E financing at a $9.1B valuation [link]. Vast has quietly become a dominant infrastructure player for AI-first storage, pioneering a new storage architecture and software infrastructure layer that has drawn strategic interest from key players in AI like NVIDIA and GPU clouds like CoreWeave, Lambda and more. The Company has shown very strong customer demand, passing over $1 billion in cumulative software bookings and over at a 90% gross margin having only began selling in 2019. Particularly impressive at this scale, the Company grew to over $200M of ARR, up 3.3X year-over-year while maintaining positive cash flow for the last 12 quarters. Its product platform intentionally blurs the line between storage and database infrastructure, purpose-built for AI.

As Jensen Huang highlighted in the acquisition of Mellanox, there are 3 key infrastructure components to AI-first computing in the data center — obviously in addition to physical space, racking, cooling, power and the utilities, etc.:
Compute — led by NVIDIA’s GPUs, with competition from AMD and Google/Broadcom’s TPUs
Networking — now led by NVIDIA’s Mellanox Networking, with competition from Arista, Cisco, Broadcom, Juniper, HPE and Aruba, Intel and Dell EMC
Storage — now led by VAST Data for AI workloads, with a historically fragmented market with players like Dell, NetApp, Pure Storage, Huawei, HPE, IBM, Micron, Cloudera
See attached for how Vast compares itself to other storage vendors
VAST brings an innovative approach of software-defined storage, purpose-built for the data optimizations needed for AI. That is, as CEO Renen Hallak says, “Vast is a software company that operates on commodity hardware”.

Vast Data — Data Center Storage Market Backdrop and Flash-based Storage:
At the founding of VAST, the 4 founders had the realization that vast datasets offer the best representation of the natural world and that these datasets for deep learning in practice are essentially applied statistics. Flash-based storage has been taking share in the data center storage market, as the fastest memory is required for expensive GPU compute and AI networking. Not only has flash been getting faster, it’s also been getting cheaper and more reliable — becoming the default choice and only way to run AI.
The founders of VAST state that at founding, all-flash was 10X the cost of hybrid storage costs and while there were many startups working on improving the speed of flash, VAST was the only company working on making all-flash practically affordable. Importantly, VAST views itself as a data company (not just a storage company) and has created significant innovations in the realm of data infrastructure, which we discuss later. The Company aims to be the all-in-one player delivering on price performance value prop in data storage.

As a result of its price/performance value proposition, data center operators are increasingly deciding on Vast over incumbents like NetApp and Pure Store every 4-7 years as they upgrade existing boxes.
Vast Data — Storage Innovations:
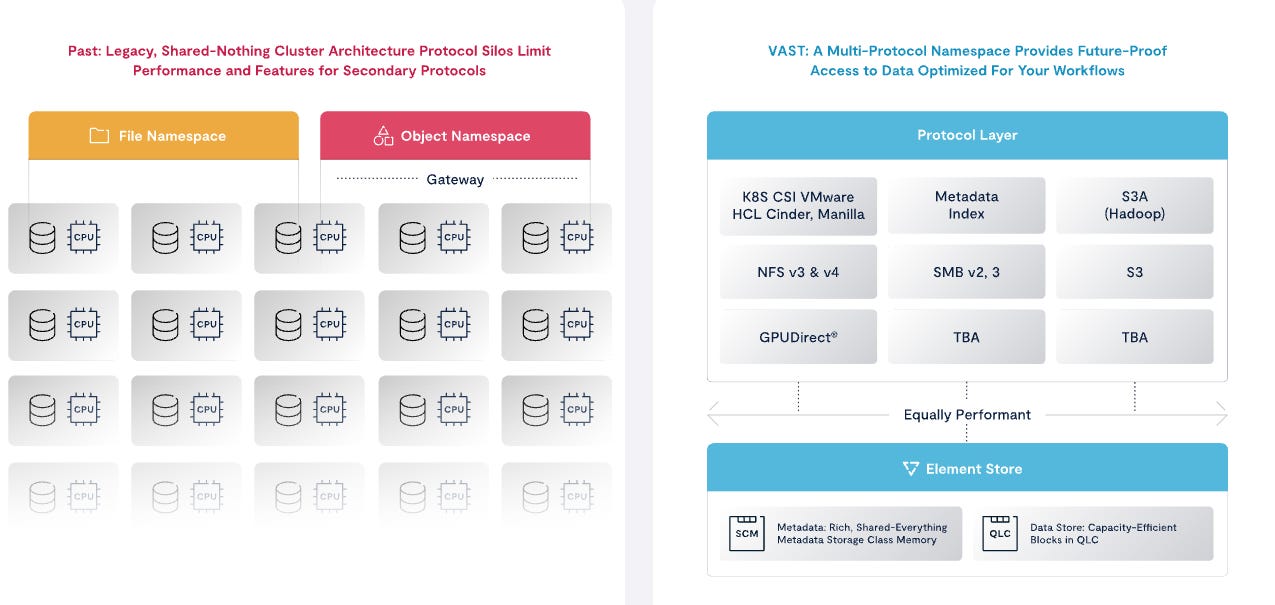
Over 30 years ago, Teradata launched the first “shared-nothing” (“SN”) system architecture. Later, Google published the seminal Google File System, which detailed a new system architecture that eliminates single points of failure. Shared-nothing allows the overall system to continue operating despite failures in individual nodes and allowing individual nodes to upgrade hardware or software without a system-wide shutdown. Shared-nothing systems scale by organizing a series of independent commodity storage servers to create high-capacity and high-performance namespaces.
Google's “Shared Nothing” architecture has inspired hundreds of billions of data center investment in scalable storage, database, and hyperconverged systems. While SN solved early 2000s scalability issues, SN introduced significant challenges as customer needs from such systems have grown:
With nearly petabyte-sized servers and growing SSDs for today’s data centers, the cost of server failures are increasingly painful with operational and data loss risks.
Shared-nothing systems require tight node coordination for data writing. This coordination around shared operations, cache management, locking, rebuildings and cache coherency stress the limits of east-west traffic and its coordination systems make it tough for clusters to scale consistency.
Data access capability is determined by their CPU and storage architecture. Failing to scale the CPUs independent of data capacity results in isolated data islands known of as “tiers”. Essentially, performance is rigid and inflexible.
To counter these limitations, VAST introduced DASE — Disaggregated Shared Everything. DASE disaggregates (separates) the storage infrastructure from compute.

The DASE architecture relies on stateless servers, known as VAST Containers, that can access a global namespace via a high-speed NVMe fabric, which can be based on Commodity Ethernet or InfiniBand. This allows for multi-protocol access, ensuring compatibility with a variety of data access methods. The combination of Storage-Class Memory with Hyperscale Flash within each High Availability (HA) Enclosure is unique; it offers both the high performance of SCM and the large-scale storage capacity of flash memory, aiming to provide fast, reliable, and cost-effective storage solutions that are future-proof for growing AI and data needs.
DASE fuses capacity with performance, data with rich metadata. With DASE, compute clusters can be separated from SSDs as if they are directly attached. With DASE, servers can be deployed on Ethernet or Infiniband networking, and can be scaled to support exabytes of data across 10s of thousands of processors. Once processing has been disaggregated from the system state, you only need to buy capacity when you need capacity and only buy stateless compute when you need more cluster performance — CPUs scale independently of storage.

Note, while Vast’s product is delivered as a hardware solution, the Company is not operating in that business manufacturing its products. The company partners with a few third-party manufacturers (i.e. Avnet AVT 0.00%↑ , and Arrow Electronics ARW 0.00%↑ ) for the boxes that are paid separately.
What this translates to is what differentiates VAST from competitors in price / performance tradeoff. Vast's storage architecture stands out by blending top-tier performance with cost-effective pricing, a unique approach compared to Pure Storage and NetApp. It achieves this by primarily using consumer-grade QLC flash for over 90% of storage capacity, complemented by a high-end, custom flash chipset for the critical top 5-10% of the array. This design allows for efficient management of hot (frequently accessed) and cold (infrequently accessed) workloads, ensuring reliability even on the more economical consumer-grade flash.
Vast Data — Data Innovations:
In addition to its software-defined hardware innovations, DASE introduces new shared and transactional data structures that are optimized for unstructured data. As we discussed in our Snowflake piece on LLMs, unstructured data is the heart of AI. Unstructured is the raw content, and structure becomes the corresponding that comes from data labeling, data prep and AI inference. From VAST’s perspective, bringing semantic understanding to unstructured data is the holy grail as “the power of AI is to understand the context of files that have no schema in order to create structure from unstructured data”.
By rethinking traditional storage and database architectures, Vast Data has integrated file and object storage with advanced database services, enabling real-time data management and analysis. A key aspect of Vast Data's innovation is the use of affordable flash memory combined with unique data structures. This combination simplifies the data infrastructure, collapsing traditional storage tiers and database layers into a single, scalable system. The result is a unified architecture that provides both high performance and cost efficiency. This system is particularly suited for AI applications where access to large amounts of data is essential.
Vast Data's platform also addresses the challenges of deep learning. Recognizing that deep learning is essentially applied statistics, the company has built a system that leverages flash storage to provide the necessary speed and capacity for these applications. Their approach to data storage infrastructure, named the VAST DataStore, is a distributed file and object storage system that offers the scale and resilience needed for exabyte-scale flash within data centers.

Moreover, Vast Data has reimagined database tiers by creating a new database architecture that handles multi-variant data streams in real-time while providing instantaneous structured queries. This innovation allows for the correlation of data all the way to the archive, significantly enhancing the speed and precision of data analysis. With these developments, Vast Data is shaping the future of AI infrastructure by providing a platform that can handle the growing and diverse demands of modern AI applications.


Some additional features that are core to bringing structured context to unstructured data within VAST’s data platform:
VAST DataSpace, a key feature in VAST Data's infrastructure, revolutionizes global data management by enabling efficient and consistent transaction handling across large datasets. This system facilitates global data sharing with transactional consistency, through peering relationships between clusters for selective data synchronization. It combines top-level metadata caching, local caching, and global prefetch for effective read operations, along with a decentralized lock management system for streamlined write operations. This approach ensures both flexibility and global consistency, making it ideal for AI applications that require quick, reliable access to extensive data.
VAST Data Engine, as part of the VAST Data Platform, is a key element that refines unstructured data into insights accessible through structured queries. This computational framework, running in containers across the VAST DataSpace, supports a range of CPU, GPU, and DPU resources. It introduces a functional programming environment for deep learning training and inference, and extends data ingest capabilities with a Kafka connector for real-time data streaming. This innovative engine plays a crucial role in VAST's vision for a unified, efficient AI data infrastructure.
Given VAST’s architecture choices in storage and data, the overwhelming workloads they win are expand use cases like big data analytics and AI workloads (specifically AI training workloads). These require high compute and low latency. Vast Data's technological approach gives it a competitive edge in AI data management.
By uniquely supporting both file and object storage, Vast can effectively combine data across sources like a Snowflake database with the raw storage functionality of an S3 bucket. This integration at the physical storage layer is both elegant and high-performing, constituting their "secret sauce." The blend of flash storage, advanced networking across multiple units, and sophisticated file and storage technology provides a significant advantage. Although these elements may become commoditized over time, they currently establish a strong competitive moat for Vast against other storage vendors.
Vast Data — Company History:
VAST Data was founded on the idea that the future of artificial intelligence must be built upon storage and data infrastructure that allows for AI engines to process data at any scale. The Company was founded in 2016, though began selling in 2019. Vast Data has four co-founders:
Renen Hallak (Founder and CEO) — Before founding VAST Data, Renen Hallak led the architecture and development of an all-flash array at XtremIO, where he was instrumental in growing the business from its inception to over $3B dollars in revenue and 40% market share in flash storage. He served as VP of R&D and led a team of over 200 engineers.
Jeff Denworth (Co-founder) — Jeff served as the Senior Vice President of Marketing at CTERA Networks Ltd. and Vice President of Marketing at DataDirect Networks Inc., where he directed marketing, business, and corporate development during a phase of rapid sales expansion.
Shachar Fienblit (Chief R&D, co-founder) — previously worked at Kaminario and IBM on data storage. His background and expertise, particularly in the realm of storage solutions, played a significant role in shaping VAST Data's innovative approach to data storage and management.
Alon Horev (Co-founder, VP Technology) — previously worked at Cisco and the Israeli Defense Force
VAST has predominantly raised from traditional venture firms as well as strategics like NVIDIA and Dell.
Series A (2016): Raised $15 million, led by 83North and Norwest.
Series A1 (2018): Raised $25 million, led by Dell Technologies Capital, 83North, and Norwest.
Series B (2019): Raised $40 million, led by Greenfield, 83North, and Norwest.
Series C (2020): Raised $100 million at a $1.2B valuation, led by Next47, with participation from NVIDIA and Mellanox.
Series D (2021): Raised $83 million, led by Tiger Global Management at a $3.7B valuation.
Series E (2023): Raised $118 million, led by Fidelity Management at a $9.1B valuation, with participation from BOND
The Company has about 630 employees per LinkedIn, roughly equally split between Israel and New York.
Vast Data — Business Model and Customers:
Vast Data's business model strategically shifts away from hardware involvement, focusing instead on leveraging data center capital expenditures through 4-5 year software contracts paid upfront. This model involves customers purchasing a Vast box, where they pay for the software subscription upfront for a period of 4-5 years, while hardware costs are handled separately with third-party manufacturers like Avnet and Aero Electronics. This approach allows Vast Data to step out of the hardware business, offloading it to these partners. The result is a financial profile that excels in cash flow and Annual Recurring Revenue (ARR), though may lag in live revenue. VAST Data is actively working on establishing operational procedures to enhance this aspect of their business model.
VAST boasts an impressive set of customers, with its average Fortune1000 paying $1.2M annually for its solution and a 4X year-over-year growth in F1000 customers. Its largest customers are GPU cloud providers like CoreWeave and Lambda (+ dozens of others), as well as mainstream enterprises like Verizon, Zoom, Pixar; it also has government agencies like NASA and the US Air Force. The press release claims the Company is above $200M of ARR, growing 3.3X YoY with 90% gross margins — quite impressive and in a special tier list!

Vast Data's unique approach to data infrastructure, combining high-performance, scalable storage with an emphasis on efficient data handling, positions it exceptionally well for AI training workloads. Their system's ability to rapidly process and manage large datasets with low latency aligns with the demanding requirements of AI and machine learning tasks, offering potential for significant speed and efficiency improvements in training complex models.
VAST Data — Partnerships:
Vast Data has established itself as the preferred storage vendor for prominent GPU cloud providers, including Coreweave and Lambda, leveraging the high-performance capabilities of Nvidia Infiniband networking. This strategic alignment with Nvidia's technology positions Vast as a key player in the infrastructure of GPU clouds. Their expanding influence is evident as they are now the preferred storage provider for an additional 38 GPU cloud services, underscoring their significant presence in this specialized and rapidly growing market. NVIDIA is a key channel partner for VAST and has made it its preferred storage vendor. VAST has also partnered with other networking vendors like Arista and HPE, as well as cloud providers and hardware vendors in the data center.
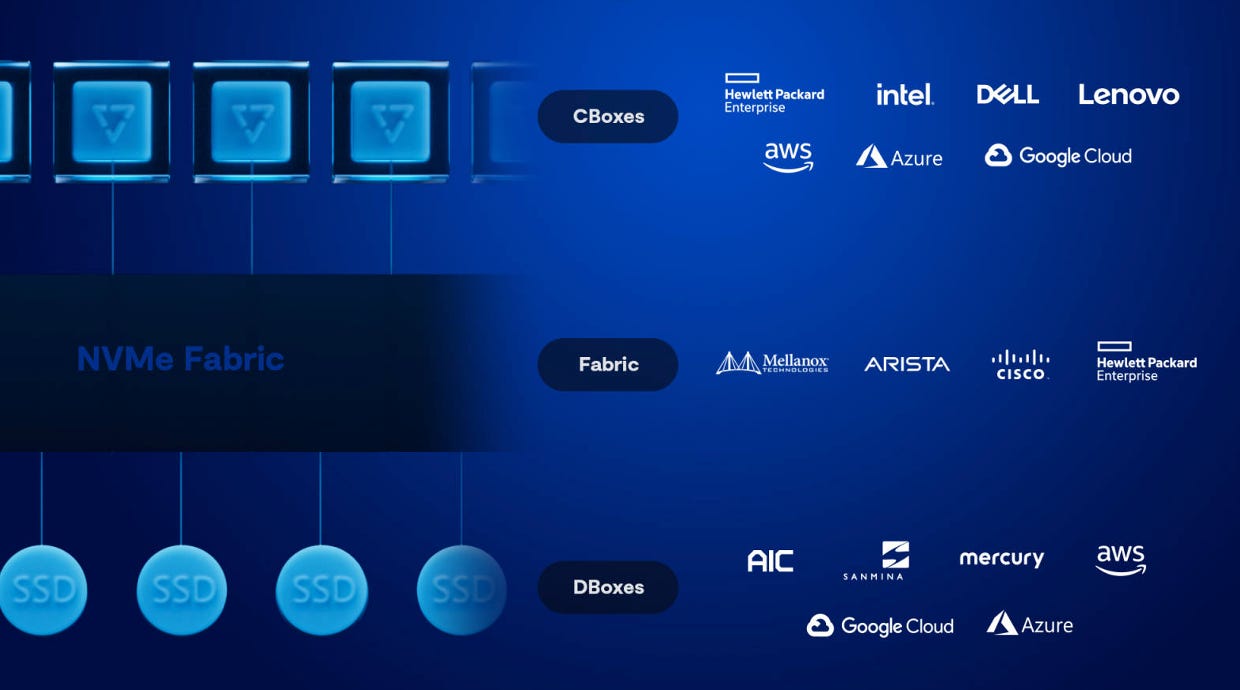
NVIDIA is actively promoting Vast Data as the storage solution of choice to its channel partners, making Vast the first and only SuperPOD certified partner. This partnership stems from Vast's ability to handle the immense data demands of AI and machine learning workloads efficiently, which is crucial for optimizing the performance of NVIDIA's advanced GPUs and networking solutions like Infiniband. By recommending Vast, NVIDIA ensures its partners can offer a comprehensive, high-performance solution, enhancing the overall value and effectiveness of their AI and data-intensive applications. This alignment not only benefits NVIDIA's ecosystem but also solidifies Vast's position as a leading provider of storage solutions in environments where speed and data processing capabilities are critical.
The Company also has made technology partners:
Veeam, to empower enterprise organizations to eliminate the threat of extended downtime following a ransomware attack.
Vertica, to help enterprises consolidate their structured and unstructured data silos to democratize data for real-time data exploration, analytics, and insights.
Splunk, all-flash data store for Splunk that delivers faster insight from more data at lower costs
Commvault, to provide an integrated, modern data protection solution with superior safeguards for organizations looking to protect their data from looming cyber threats or natural disasters.
Dremio, to enable enterprises to get from data to insights faster with a hybrid, multi-cloud architecture for scalable analytics, regardless of physical location – on-premises or in the public cloud.
Vast Data — Product Roadmap:
Vast is working on a new feature called a global namespace for their storage products. Traditionally, a namespace in computing is like a map of where data is stored, and it used to be limited to just one computer or mainframe. Over time, this changed to having multiple computers or servers for one database. Nowadays, large databases, like those used by Snowflake, are spread across many data centers, with each data center holding a part of the database. This setup lets data be moved around easily within the same data center.
What Vast is planning to do is quite innovative. They want to create a single, global namespace that works across all data centers. This means that no matter where the data is physically located – whether it's in Paris or New York – it will perform as if all the data is in one place. This is somewhat similar to what CockroachDB does for databases. The performance benefit of this is significant for tasks that require analyzing or training on all the data a company has, no matter where it's stored. With Vast's global namespace, these tasks can run more efficiently because the data, although physically apart, is treated as if it's all together in one location. This could greatly improve the performance of data-heavy tasks, especially in analytics and machine learning.
Conclusion
Vast stands out as a pioneering company in the intersection of storage and database technology, thanks to its groundbreaking approach in creating a unified, global namespace. This innovation not only blurs the traditional boundaries between storage and databases but also firmly positions Vast as a crucial player in AI storage within data centers, offering a more integrated and efficient infrastructure for handling extensive data workloads.